
Anthropic Reportedly Commits $200B to Google Cloud
Anthropic reportedly commits 200b to Google Cloud and chips over five years, marking one of the largest infrastructure deals in technology history. This recent agreement covers cloud services, compute resources, and chip access—specifically Google’s Tensor Processing Units (TPUs)—and signals a fundamental shift in how AI companies secure the infrastructure needed to build and deploy frontier models.
This analysis, citing public information and expert comment, covers the deal structure, strategic implications for AI infrastructure, and what enterprise technology leaders should understand when evaluating their own AI infrastructure partnerships. The target audience is CTOs, technology executives, and enterprise leaders who need to build knowledge about AI compute economics at scale. Whether you’re planning your organization’s AI roadmap or negotiating cloud contracts on your website, this deal offers concrete lessons about infrastructure planning in the AI era.
The direct answer: Anthropic commits approximately $200 billion to Google Cloud and chips, representing about $40 billion annually in cloud and chip spending. This reflects the real costs of training and serving frontier AI models like Claude at scale. This deal, combined with similar arrangements across major cloud providers, contributes to a revenue backlog of $2 trillion—demonstrating that sustained demand for AI services is shaping infrastructure decisions measured in decades, not quarters.
Key outcomes from this analysis:
Understanding what drives AI infrastructure costs at this scale
Vendor lock-in considerations and multi-cloud strategy insights
Market implications for enterprise AI planning
Practical lessons for negotiating long-term cloud commitments
Timeline and capacity expectations for AI compute availability
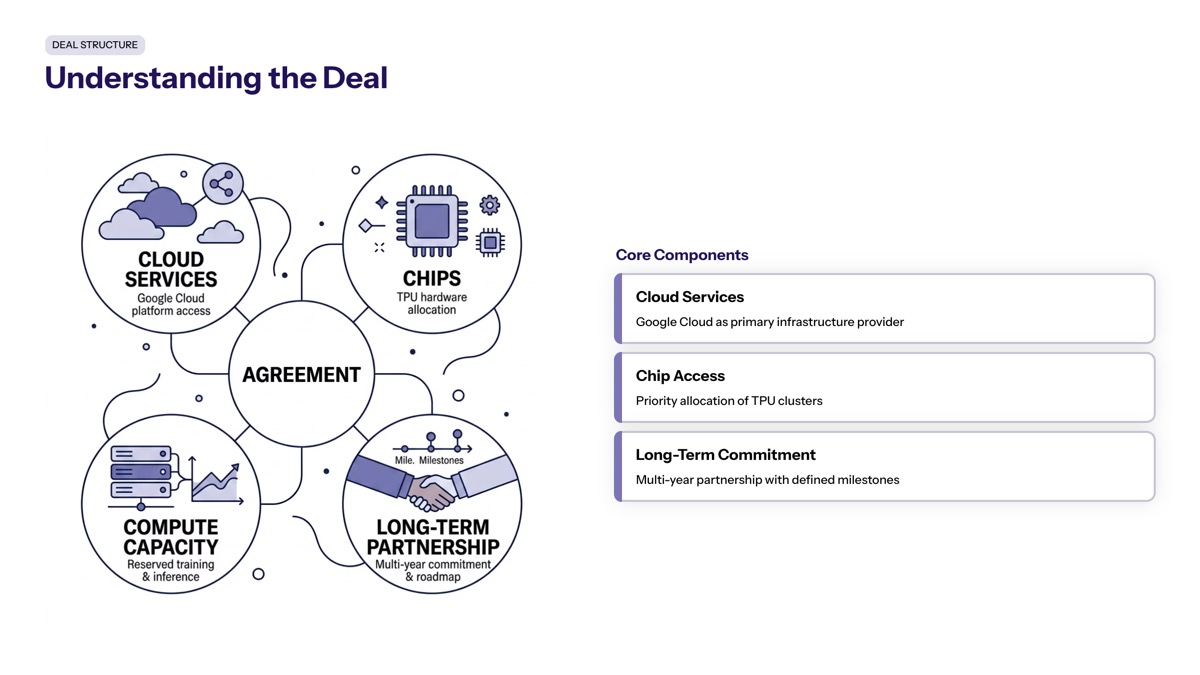
Understanding the Deal Structure
The $200 billion commitment between Anthropic and Google represents more than a standard cloud contract—it’s a strategic partnership that combines infrastructure spending, chip access, and financial investment into a single arrangement. The deal will support the development of Anthropic’s future AI models, including the Claude models, providing the compute foundation needed for both training and inference at scale.
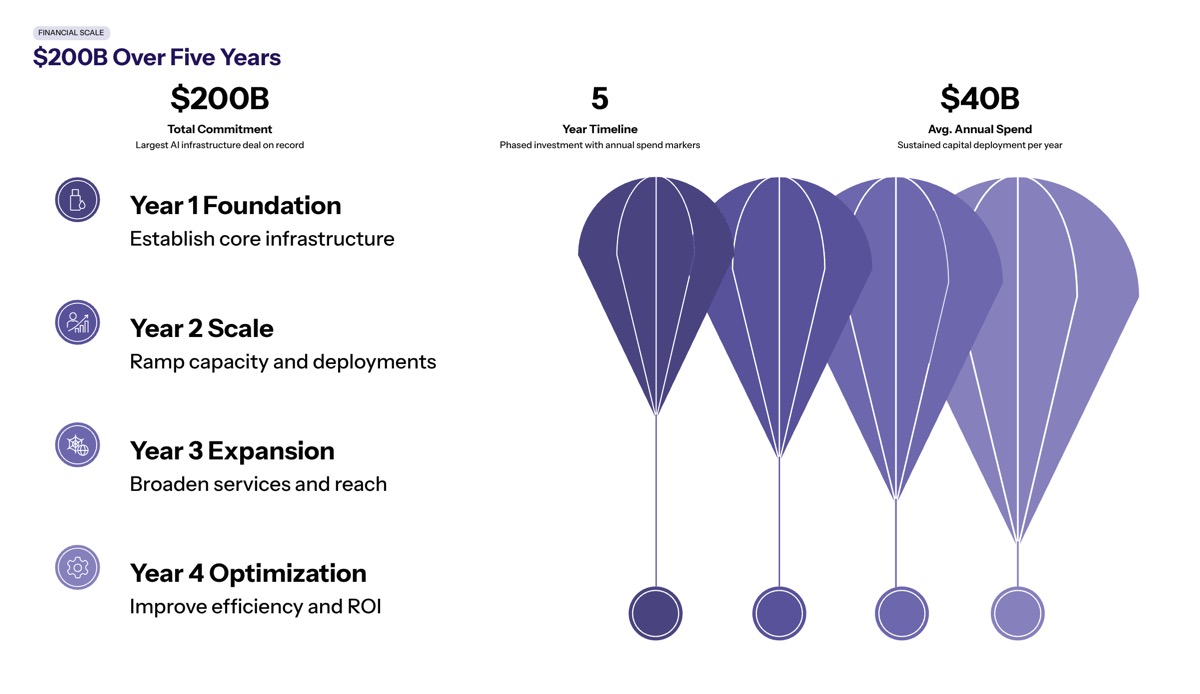
Financial Scale and Timeline
Breaking down the money involved: $200 billion over five years averages to roughly $40 billion annually that Anthropic will pay for Google’s cloud infrastructure. This agreement will initiate significant capacity utilization starting in 2027, with approximately 1 GW of TPU capacity coming online in 2026 and an additional 3.5 GW through Broadcom partnerships beginning the following year.
To understand the scale, consider that Google Cloud’s revenue backlog stood at approximately $462 billion as of Q1 2026. More than half of this backlog is attributable to major commitments like Anthropic’s, demonstrating the concentration of demand from a single customer. Comparable deals exist (Oracle’s $300 billion arrangement with OpenAI, for instance), but few enterprise contracts approach this percentage of a provider’s total committed revenue.
The financial relationship runs both directions. Alphabet is reportedly investing up to $40 billion in Anthropic, with approximately $10 billion immediately and the remaining $30 billion tied to performance milestones. This partnership reflects a trend where major cloud providers act as both investors and vendors for AI startups, creating financial interdependencies that reshape traditional customer-vendor relationships.
Technical Infrastructure Components
The technical substance of this recent agreement centers on chips—specifically, access to Google’s proprietary Tensor Processing Units and associated infrastructure provided through chip partner Broadcom. Anthropic’s reliance on Google TPUs indicates a shift toward custom AI accelerators as alternatives to Nvidia’s GPUs, a strategic bet that purpose-built silicon can deliver better price-performance for specific AI workloads.
The infrastructure components include:
Multiple gigawatts of TPU compute capacity for model training
Cloud services for storage, networking, and deployment
Broadcom-supplied components including networking, packaging, and power systems
TSMC fabrication for the underlying chip manufacturing
This isn’t simply renting compute time—it’s securing manufacturing capacity and supply chain commitments years in advance. Anthropic is effectively reserving a share of the world’s specialized AI chip production.

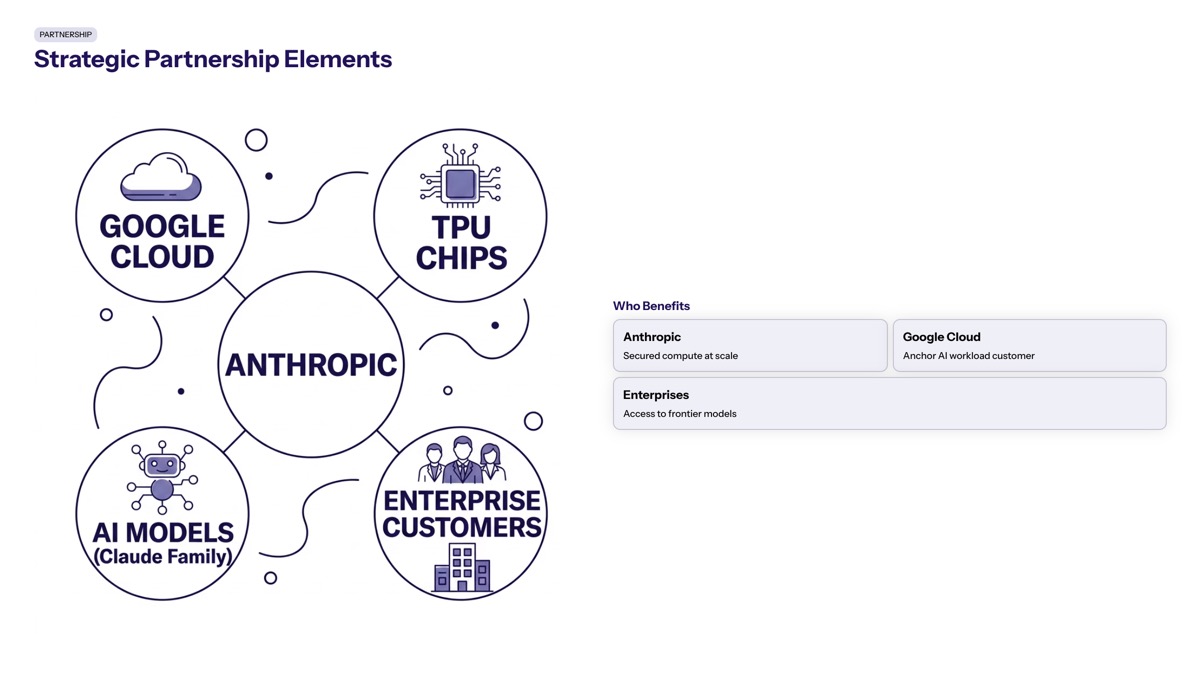
Strategic Partnership Elements
What makes this deal different from standard cloud contracts? Three elements stand out:
First, the time horizon. Five years represents a significant commitment in an industry where technology shifts rapidly. Anthropic is betting that TPU architecture will remain competitive, that their compute needs will continue growing, and that Google will execute on hardware roadmap promises.
Second, the vertical integration. Google provides the chip architecture, Broadcom supplies manufacturing components, TSMC handles fabrication, and Google Cloud delivers the infrastructure. Anthropic gains access to this entire stack through a single relationship, simplifying procurement but increasing dependency.
Third, the scale creates negotiating power. A person familiar with the deal commented that a customer committing $40 billion annually commands different service levels, pricing structures, and customization options than typical enterprise accounts. The deals between Anthropic and major cloud providers like Google and Amazon are contributing to a revenue backlog of $2 trillion across these companies, reflecting the growing financial stakes in AI development.
This structure raises an important question for enterprise leaders: when does a vendor relationship become a strategic partnership, and what governance, risk management, and dependency considerations should that trigger?
Strategic Implications for AI Infrastructure
The Anthropic deal reveals something fundamental about AI economics: the cost of competing at the frontier isn’t measured in millions, but in tens of billions annually. Understanding why this commitment makes sense for Anthropic—and whether similar logic applies to enterprise AI initiatives—requires examining the compute constraints shaping these decisions.
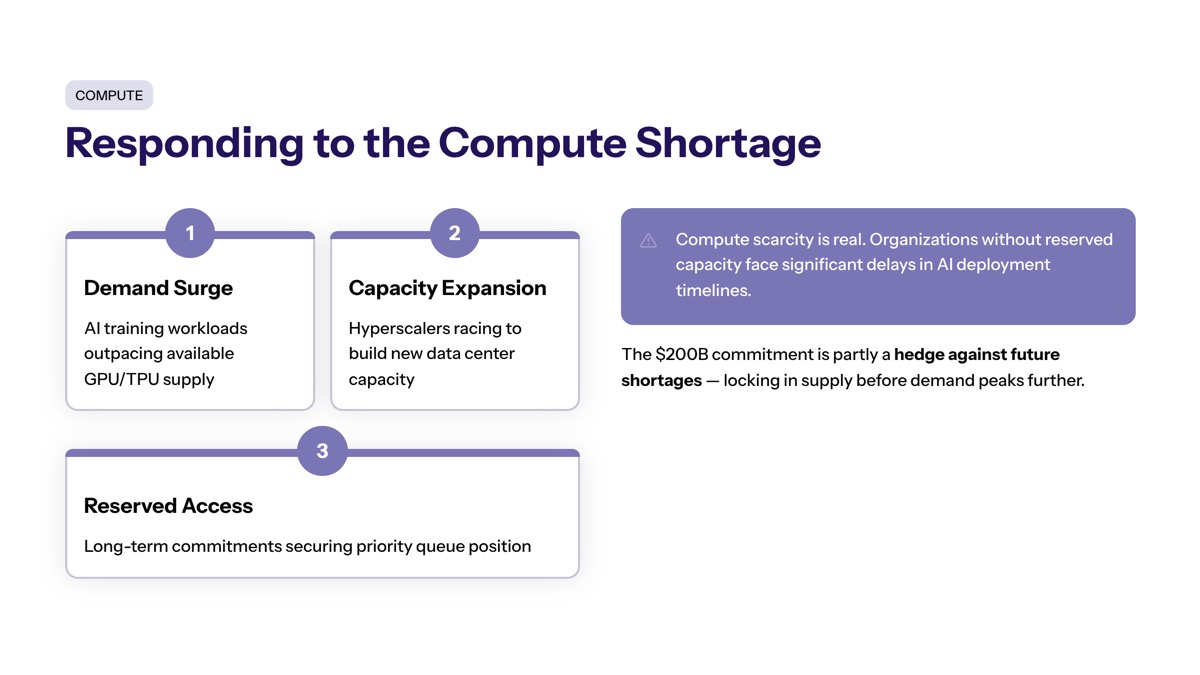
Compute Shortage Response
Anthropic faced real infrastructure constraints before this deal. Demand for Claude across Pro, Max, Team, and Enterprise tiers was growing faster than available compute capacity. The company’s revenue run rate passed $30 billion in early 2026, up from approximately $9 billion at end of 2025—growth that required corresponding infrastructure expansion.
The scale of investment raises concerns about the sustainability of the current AI investment model, described as ‘cash-burning’ by some analysts. Yet Anthropic’s leadership apparently concluded that the greater risk was insufficient capacity rather than overcommitment. Training next-generation models requires enormous FLOP budgets, and serving those models to millions of users requires sustained inference capacity.
For enterprises facing similar—if smaller-scale—challenges, the lesson is clear: AI infrastructure planning must look 3-5 years ahead, not just to the next budget cycle. Capacity constraints during critical growth periods can be more damaging than conservative overprovisioning.
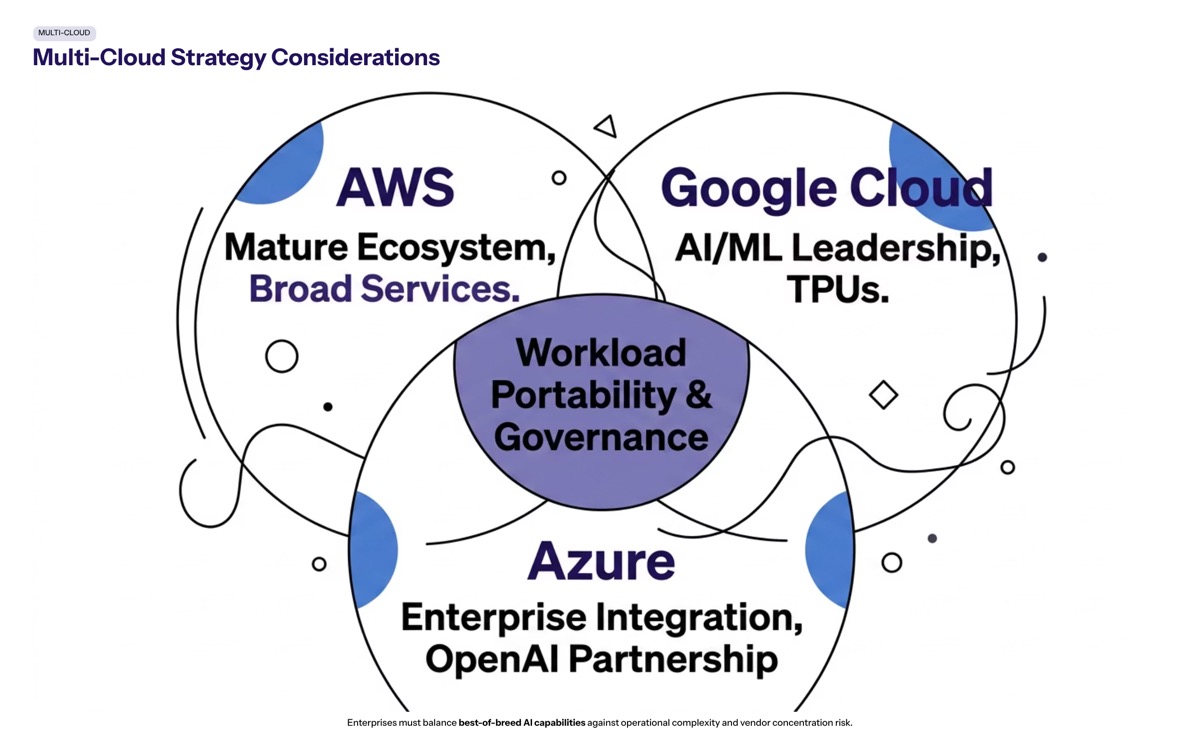
Multi-Cloud Strategy Considerations
Despite the $200 billion Google commitment, Anthropic maintains parallel infrastructure relationships. AWS remains a primary partner through Trainium chips, and agreements with CoreWeave and GPU providers continue. This diversification isn’t contradictory—it’s risk management.
The recent partnerships and commitments by Anthropic are expected to improve the reliability and capacity of AI services, which is crucial for developers building applications that depend on consistent compute resources. By maintaining multiple infrastructure partners, Anthropic can:
Allocate different workload types to optimal hardware (TPUs for certain training tasks, GPUs for others)
Maintain negotiating leverage with each provider
Build redundancy against outages, supply chain disruptions, or capacity constraints
Avoid technical lock-in that would prevent workload portability
Enterprise architects should read this as validation of multi-cloud strategies, even when one provider dominates spend. The question isn’t whether to use multiple clouds, but how to structure that relationship for maximum flexibility.
Market Signal Analysis
Anthropic’s $200 billion commitment to Google Cloud over five years signals a significant shift in the AI infrastructure landscape, indicating a belief in sustained demand for AI services. This isn’t speculative investment in future possibilities—it’s committed spend based on existing revenue and projected growth.
The Anthropic deal with Google, which involves a $200 billion commitment over five years, is expected to significantly increase demand for advanced chips as it signals sustained growth in AI infrastructure needs. For enterprise leaders, this creates both opportunities and challenges. Cloud providers will continue prioritizing their largest AI customers for capacity allocation during shortage periods. Traditional enterprise workloads may find themselves competing for resources with AI labs willing to make decade-long commitments.
The deal between Anthropic and Google Cloud is part of a larger trend where AI startups are making substantial commitments to cloud providers, contributing to a revenue backlog of $2 trillion across major tech companies. Understanding this market context helps enterprises anticipate pricing trends, capacity availability, and the evolving nature of vendor relationships.
Implementation and Market Impact
How should enterprise technology leaders respond to a market where individual AI companies commit $200 billion to single vendors? The practical implications touch infrastructure planning, cost modeling, vendor negotiations, and technical architecture decisions.
Enterprise Infrastructure Planning Process
The revenue backlog created by deals like Anthropic’s with major cloud providers is estimated to be around $2 trillion, indicating substantial demand for chip manufacturing to support this growth. Enterprises planning AI initiatives must account for this competitive landscape.
Step-by-step approach for enterprise AI infrastructure planning:
Assess current and projected AI workload requirements — Distinguish between training and inference needs, estimate growth curves based on business adoption scenarios, and identify peak versus sustained compute demands.
Evaluate multi-cloud versus single-provider strategies — Determine which workloads benefit from specialized hardware (TPUs, Trainium, custom ASICs) versus commodity GPU compute, and design portability into critical systems.
Model cost implications over 3-5 year periods — Build scenarios for different utilization levels, account for power and cooling costs at scale, and include chip supply chain risks in financial projections.
Plan for capacity constraints and vendor negotiations — Identify when long-term commitments make sense versus on-demand usage, and structure contracts with flexibility clauses while securing necessary guaranteed capacity.
The planned Terrafab chip manufacturing facility in Texas, which has seen its cost estimates rise to between $55 billion and $119 billion, is now viewed as a credible project due to the demand generated by Anthropic’s commitment to cloud computing. This suggests infrastructure investment at all levels—from data centers to chip fabrication—will continue expanding.

Cost Structure Comparison
Understanding when massive long-term commitments make financial sense requires comparing cost structures across different infrastructure approaches:
Factor | Traditional Cloud Usage | Long-term AI Infrastructure Commitment |
|---|---|---|
Pricing Predictability | Variable, subject to market rates | Fixed or predictable over contract term |
Capacity Guarantee | Best-effort during high demand | Reserved capacity with SLAs |
Hardware Access | Standard instances | Custom accelerators, priority allocation |
Negotiating Position | Transactional | Strategic partnership |
Lock-in Risk | Lower, easier migration | Higher, significant switching costs |
Cost per FLOP | Market rate | Potentially 30-50% lower at scale |
For most enterprises, the Anthropic model won’t apply directly—few organizations need gigawatts of AI compute. However, the underlying economics suggest that organizations with predictable, sustained AI workloads should explore committed capacity agreements rather than relying entirely on on-demand pricing. |
Vendor Relationship Implications
A commitment of this scale transforms the vendor relationship. Service level agreements, capacity reservations, hardware roadmap visibility, and customization options all expand when a customer becomes a meaningful portion of a provider’s business.
For enterprise leaders, the question becomes: what commitment level creates similar partnership dynamics at smaller scale? The answer varies by organization, but signals exist. When AI infrastructure becomes critical business infrastructure—not experimental workloads—vendor relationships should evolve accordingly.
Common Questions and Enterprise Concerns
Enterprise leaders evaluating AI infrastructure often encounter consistent concerns. This section addresses the most frequent questions, drawing lessons from the Anthropic deal structure.

Vendor Lock-in Risk Management
The $200 billion commitment creates significant dependency on Google’s infrastructure and chip architecture. How does Anthropic mitigate this risk—and how should enterprises approach similar decisions?
Key strategies include:
Maintaining parallel infrastructure relationships (AWS Trainium, CoreWeave, GPU providers)
Investing in hardware-agnostic frameworks and containerized deployments
Building portability testing into development workflows
Negotiating exit provisions and data export guarantees in contracts
For enterprises, the principle applies at smaller scale: any commitment should include documented migration paths, even if you don’t intend to use them.

Budget Planning for AI Infrastructure
AI compute costs can escalate rapidly. Anthropic’s revenue growth (from $9 billion to $30 billion annually) justified corresponding infrastructure expansion, but enterprises need conservative forecasting approaches.
Practical budgeting guidance:
Build scenarios at multiple utilization levels (conservative, expected, optimistic)
Separate training costs (typically front-loaded, project-based) from inference costs (ongoing, scales with usage)
Account for the full cost stack: compute, storage, networking, data transfer, power, and personnel
Include flexibility provisions in contracts to scale down if projections don’t materialize

Technical Architecture Decisions
How should enterprises design AI systems that can adapt to changing infrastructure availability? The Anthropic approach offers guidance: specialize where it creates significant advantage, but maintain portability for critical components.
Architectural principles:
Separate training pipelines from inference systems, as they have different optimization targets
Use abstraction layers that can target multiple hardware backends
Monitor cost per model or per feature, not just aggregate infrastructure spend
Design for hybrid deployment: some workloads on committed capacity, others on spot instances
Compliance and Security Considerations
Large cloud commitments in regulated industries require attention to data sovereignty, auditability, supply chain security, and environmental compliance. Custom hardware stacks (TPUs, specialized networking, Broadcom components) introduce considerations that standard cloud deployments don’t trigger.
Enterprises should address:
Data residency and sovereignty requirements for model training data
Hardware supply chain security and firmware trust
Physical infrastructure risks at data centers handling critical workloads
Environmental compliance and sustainability reporting for multi-gigawatt deployments

Conclusion and Strategic Recommendations
The $200 billion commitment from Anthropic signals a shift in the AI infrastructure landscape, indicating a long-term belief in sustained demand for cloud resources. This isn’t speculative investment—it’s operational reality for organizations building and deploying frontier AI models. The economics of AI compute, the scarcity of specialized hardware, and the multi-year timelines for capacity expansion all point to a world where infrastructure planning matters more, not less.
Immediate actionable steps for enterprise leaders:
Audit current AI infrastructure capacity and projected needs — Quantify existing usage, model growth scenarios, and identify bottlenecks before they constrain business initiatives.
Evaluate vendor relationships for strategic partnerships — Determine which cloud relationships should evolve beyond transactional, and what commitment levels create meaningful partnership dynamics.
Develop multi-cloud strategies for critical AI workloads — Design portability into systems even when primary vendor relationships dominate spend.
Related topics to explore:
Enterprises building AI capabilities should also evaluate AI governance frameworks for responsible deployment, custom software development for integrating AI into existing systems, and secure infrastructure modernization to support AI workloads at scale.

Additional Resources
For organizations planning AI infrastructure investments:
AI infrastructure planning templates covering capacity modeling and cost projection
Enterprise AI architecture resources and best practices documentation
Cloud vendor comparison frameworks for AI-specific workloads
Multi-cloud strategy guidelines with portability considerations
To find more knowledge on developing custom AI infrastructure strategies tailored to your organization’s specific requirements, explore how strategic technology partnerships can support your business objectives.
