
Scaling What Works: From Pilot to Program Without Regressions
Most transformations don’t fail at the pilot. They fail at the scale.
A pilot works because it has:
- focused attention
- motivated champions
- fewer edge cases
- manual support (“we’ll just handle it”)
- temporary exceptions
Then you scale—and reality hits:
- adoption breaks
- rework spikes
- decision latency explodes
- data trust collapses
- teams rebuild workarounds
RAPID prevents this by treating transformation as a system: big problems are solved through many small steps, and progress must be measurable and continuously evaluated through Decide (stay/change/stop).
This post is a practical framework to scale what works—without regressions.
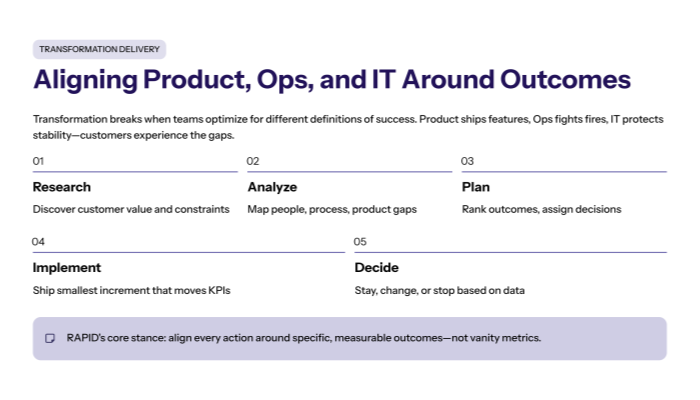

Why pilots succeed but scaling fails?

1.1 Pilots hide the real cost by relying on heroic support
In pilots, teams often compensate with invisible labor:
- extra meetings
- side-channel approvals
- manual data cleanup
- “ask Sarah, she knows how it works”
Those behaviors aren’t scalable. They’re a fragile bridge.
RAPID’s iceberg concept matters here: what you see on the surface isn’t the full system. A pilot can look great while the underlying constraints are still present—just temporarily masked.
Scaling removes the mask.
1.2 Scaling fails when the constraint moved, but the plan didn’t
Once you relieve one bottleneck, the constraint shifts. That’s normal.
Scaling fails when organizations:
- keep pushing the same change everywhere
- don’t measure new constraints
- don’t update decision rights
- don’t re-sequence the roadmap
RAPID is built as a flywheel: Research/Analyze → Plan/Implement → Decide, then adapt based on results. If your plan doesn’t evolve as constraints move, scaling will regress.
The RAPID scaling principle (prove outcomes, then expand)
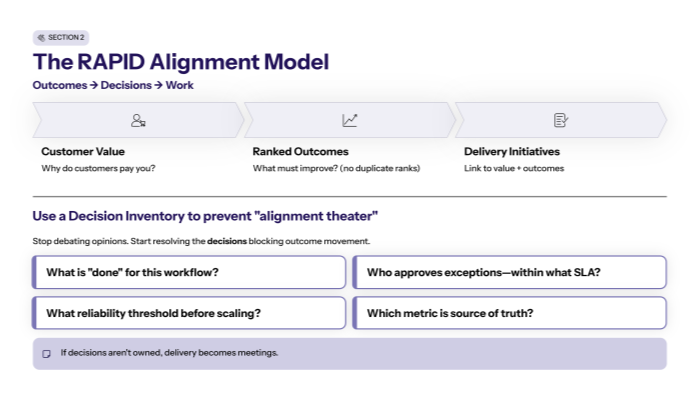
2.1 Don’t scale adoption—scale outcome movement
Most teams scale based on “rollout completion”:
- “we trained everyone”
- “we deployed to all teams”
- “usage is up”
RAPID warns against vanity metrics—signals that make leaders feel good while outcomes aren’t moving.
So the scaling rule is: Only scale when constraint KPIs move and stay moved.
That means:
- cycle time improves sustainably
- rework stays down
- decision latency remains within SLAs
- data remains consistent across teams
If the KPI movement isn’t stable, scaling is premature.
2.2 Use Decide as your scaling gate: stay / change / stop
RAPID’s Decide step is explicit: evaluate results, then decide to stay, change, or stop.
That logic becomes a scaling gate:
- Stay + expand when metrics improve and adoption holds
- Change before scaling when metrics improve but friction appears
- Stop when the initiative isn’t tied to outcomes or isn’t moving constraints
This is how you scale without regressions: you scale on evidence, not enthusiasm.
A practical scaling framework (from pilot → program)

3.1 The “Scale Readiness Checklist” (what must be true before expansion)
Use this as a hard gate before broad rollout:
|
Readiness item |
What you’re testing |
Pass criteria |
|---|---|---|
|
Outcome clarity |
Is the goal measurable and ranked? |
1–3 outcomes, clear KPIs |
|
Constraint KPI movement |
Did the bottleneck metric move? |
Sustained improvement 2–4 weeks |
|
Workflow stability |
Does the workflow work without heroics? |
Low manual exceptions |
|
Decision rights |
Are decisions owned + fast? |
Decision SLA met consistently |
|
Rework control |
Is quality stable? |
Rework down and not creeping |
|
Data trust |
Are metrics consistent? |
No reconciliation fights |
|
Enablement |
Can teams perform without champions? |
Simple training + reference tools |
|
Support load |
Is support scalable? |
Support demand predictable |
This ties directly to RAPID’s measurable-outcomes discipline and decision-making emphasis.
3.2 Scale in waves (and measure between waves)
RAPID emphasizes many small steps. Scaling should follow the same logic:
- scale to 1–2 additional teams
- measure for 2 weeks
- fix exceptions and decision rights
- scale to the next wave
This prevents the classic “big bang scaling” failure where regressions spread faster than you can diagnose them.
Preventing regressions (what breaks during scale)

4.1 Regressions usually come from exceptions, not core workflows
Core workflows often work. Exceptions create chaos:
- edge-case approvals
- special customer rules
- compliance nuances
- legacy integrations
- partial adoption
When exceptions aren’t designed, teams create:
- shadow processes
- spreadsheets
- private approvals
- manual rework loops
RAPID’s Decision Inventory matters because exceptions are decisions. Decisions must be posed as questions, owned, and prioritized.
If exception decisions aren’t handled within SLAs, decision latency becomes the new constraint.
4.2 Protect the system by tightening standards as you scale
Scaling without standards is how flexibility becomes chaos.
RAPID’s Process Gap Analysis is designed to translate findings into workflow improvements aligned to outcomes and customer value.
As you scale, standardize:
- intake definitions (“definition of ready”)
- acceptance criteria (“definition of done”)
- handoff rules (reject incomplete work)
- metric definitions (source of truth)
This doesn’t kill flexibility. It creates a stable base so flexibility is safe.
The leadership moves that make scaling stick
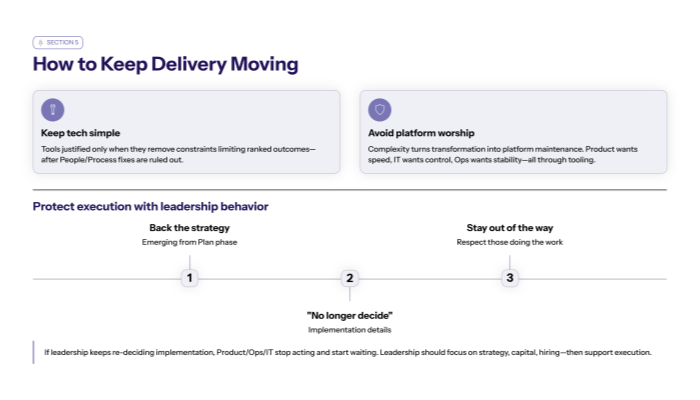
5.1 Leadership must stop re-deciding implementation (or scale will collapse)
RAPID highlights a critical leadership decision: once the strategy is backed, leadership must decide to “no longer decide” implementation details.
During scaling, interference is lethal:
- leaders grant exceptions publicly
- override owners
- change metrics midstream
- demand special workflows
That tells the organization:
- “the system is optional”
- “the old way is still acceptable”
And regressions follow immediately.
5.2 Budget and resources must scale with reality
RAPID notes that momentum can die when essential resources aren’t provided—like insufficient licenses causing bottlenecks and workarounds.
Scaling requires you to provision:
- access/licenses for the whole workflow chain
- QA/quality coverage
- training/support capacity
- data/reporting maintenance
Otherwise scaling is just expanding scarcity—and scarcity always creates workarounds.
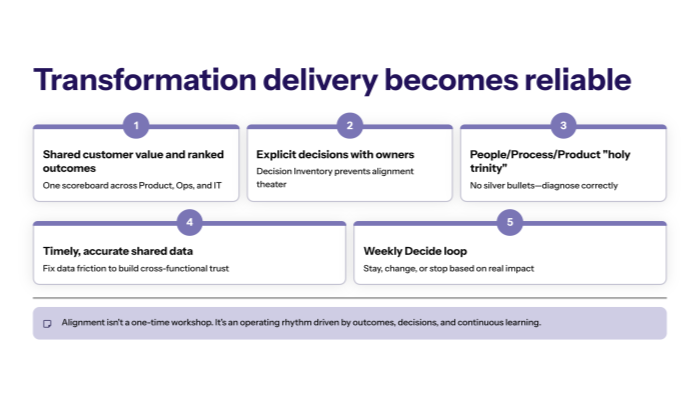
Closing takeaway
Scaling what works isn’t “rollout.” It’s controlled expansion of proven outcome movement.
Use RAPID to scale without regressions:
- measure constraints weekly and scale only on stable KPI movement
- run Decide as a scaling gate: stay/change/stop
- scale in waves, not big bangs
- standardize interfaces and decision rights as you expand
- protect execution by preventing leadership interference

