
Best Local LLM Tools: Your 2025 Guide to Top Options
In an era where privacy, cost control, and performance are top priorities, Local LLMs (Large Language Models) are rapidly becoming the go-to alternative to cloud-based solutions like ChatGPT. Rather than relying on third-party APIs or cloud services, running large language models locally means you can run locally and execute powerful AI capabilities directly on your own computer. A large language model (LLM) is an advanced AI system trained on vast amounts of text data, enabling it to understand and generate human-like language, and its local deployment offers significant advantages in privacy and control.
This form of local deployment ensures that sensitive data never leaves your machine, making it ideal for industries such as healthcare, legal, and finance where data privacy is non-negotiable. Using an open source llm allows for greater customization and enhanced security, as you can tailor the model to your specific needs without relying on external providers. Whether you’re looking to automate code generation, perform language translation, or engage in creative writing, local LLMs offer a fast, secure, and cost-effective way to build smart applications with complete control.
Key Takeaways
Running local LLMs offers significant cost savings by eliminating subscription fees and reducing reliance on external servers, while providing complete control over sensitive data.
The best local LLM tools combine minimal setup required with support for multiple models, fine tuning, and compatibility across various operating systems and hardware setups.
Leveraging optimized versions of open source models enables users to achieve optimal performance on both consumer hardware and enterprise systems, making local deployment a versatile and secure AI solution.

Introduction to Local LLMs
Local LLMs, or large language models running on your own hardware, are transforming the way individuals and organizations leverage AI. By using local LLM tools, users can deploy and manage powerful language models directly on their personal computers or local servers, gaining complete control over their data and workflows. This approach eliminates the need for cloud-based services, resulting in significant cost savings and enhanced privacy. With the latest advancements in technology, running LLMs locally has become more accessible than ever, allowing even those with minimal technical expertise to fine tune models for specialized tasks. Whether you’re a developer, researcher, or business professional, local LLMs offer a flexible and secure solution for harnessing the power of AI on your own hardware.
Large Language Models (LLMs): An Overview
Large language models (LLMs) are sophisticated AI systems trained on massive datasets, enabling them to understand, generate, and manipulate human language with remarkable accuracy. These models excel at a wide range of tasks, including code generation, language translation, creative writing, and building conversational agents. While LLMs can be accessed through cloud-based platforms, running LLMs locally offers distinct advantages: users maintain full control over their data, experience faster response times, and can operate without a constant internet connection. However, local deployment of large language models requires adequate computational resources, such as a capable GPU and sufficient storage, to ensure smooth operation. By choosing to run LLMs locally, users unlock the ability to customize and optimize their AI models for unique applications, all while keeping sensitive information secure.
Benefits of Running LLMs Locally
Choosing to run LLMs locally provides a strategic advantage in both functionality and operational cost.
However, it's important to note that running LLMs locally can be resource intensive, requiring significant hardware and computational resources to handle complex data extraction tasks efficiently.
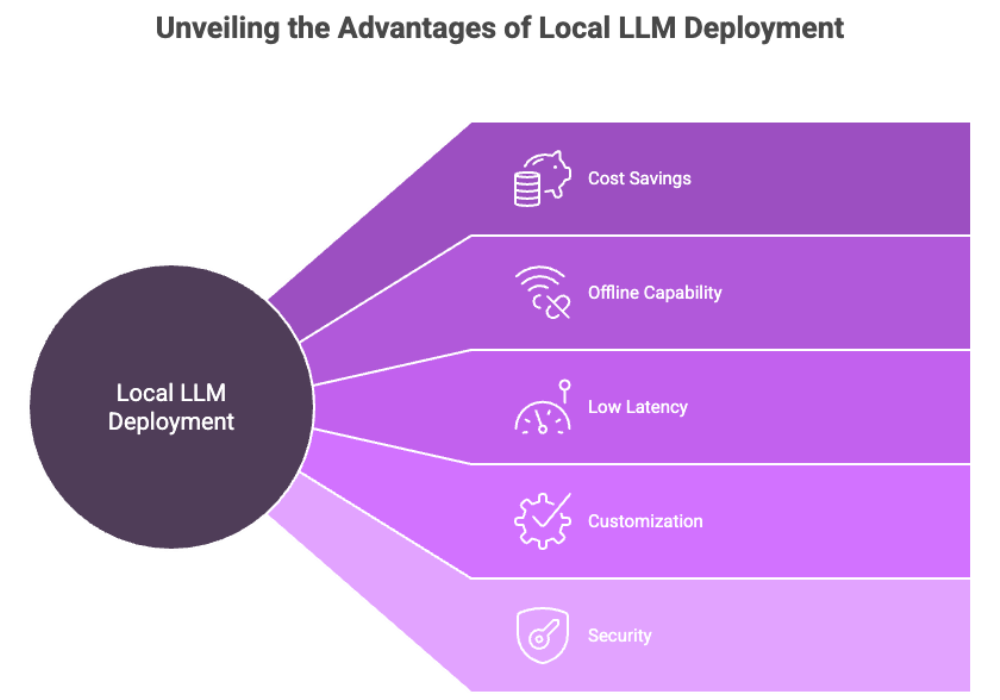
Major Benefits Include:
Cost savings: Eliminate subscription fees, API usage charges, and bandwidth costs.
Offline capability: No dependency on internet connection or external servers, enabling continuous operation.
Low latency: Real-time response thanks to reduced communication delays.
Customization: Full access to model parameters and training datasets enables fine tuning for specific tasks.
Security: Keeps all data on the local machine, making local LLMs perfect for sensitive applications.
With minimal setup required, many tools now offer optimized versions of models specifically tailored for local deployment on a range of hardware—from consumer hardware to enterprise-grade systems.
Key Features of Local LLMs
When evaluating the best local LLM tools, understanding their key features is essential for matching capabilities with your specific needs.
Web interfaces and command-line tools: Many tools offer both command-line utilities and a user-friendly web UI. The web UI simplifies access to and management of AI models, making installation and daily use more approachable for users who prefer graphical interfaces.
Common Capabilities of Local LLM Tools:
Web interfaces and command-line tools: Flexible user interfaces allow beginners and pros to interact with the models.
Multi-model support: Many platforms support running multiple models simultaneously, including both open-source models and custom builds.
Hardware compatibility: Designed to work across different hardware setups, including systems without a GPU.
Model configurability: Users can manipulate model parameters like temperature, token limits, and memory footprint.
Low barrier to entry: Thanks to minimal setup requirements, many tools are usable with just a few clicks or a single executable.
This flexibility makes local LLM tools invaluable for developers, researchers, and hobbyists alike.
Best Models for Local Use
Selecting the best models for local use depends on your hardware, use case, and desired model size. Running large models locally can be challenging due to significant hardware and storage requirements, as well as increased technical complexity. Fortunately, several high-performing open source models offer competitive performance even on smaller models optimized for local machines, and there are various llms available to suit different use cases and optimizations.
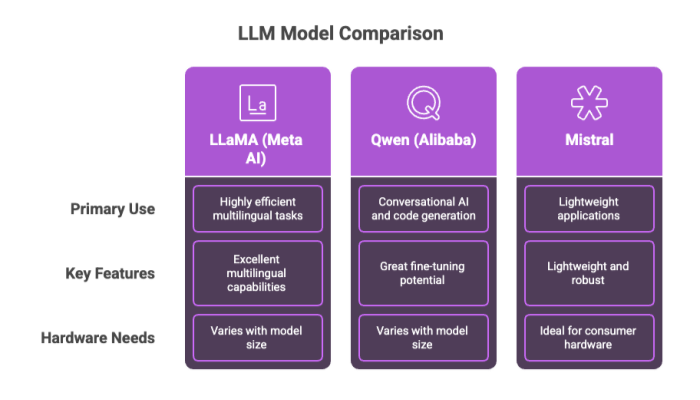
Top Local LLM Models for 2025
LLaMA (Meta AI): Highly efficient with excellent multilingual capabilities.
Qwen (Alibaba): Designed for conversational AI and code generation, with great fine-tuning potential.
Mistral: Lightweight yet robust, making it ideal for consumer hardware or mobile devices.
These models come in various sizes, allowing users to choose between larger models for complex analysis or smaller models for lightweight, fast deployment on modest setups.
LM Studio and Local LLMs
Among all local LLM tools, LM Studio has earned a reputation as one of the most accessible and powerful platforms for running models locally.
Model compatibility: LM Studio supports a wide range of model formats, allowing users to select from all the models available after setup. This flexibility ensures you can work with the specific model that best fits your needs.
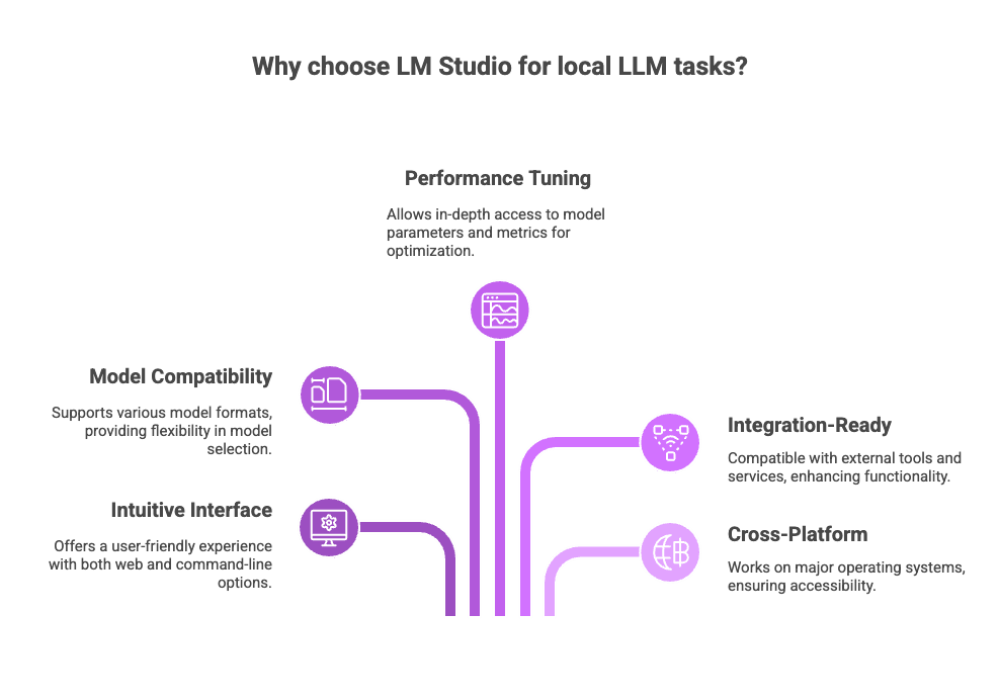
Why Choose LM Studio?
Intuitive interface: Features both a rich web interface and powerful command-line tool.
Model compatibility: Supports multiple models and formats, including .gguf, .bin, and custom formats.
Performance tuning: Offers in-depth access to model parameters, performance metrics, and memory diagnostics.
Integration-ready: Compatible with external tools and services, including APIs and external data sources.
Cross-platform: Works on every major operating system including Windows, macOS, and Linux.
Whether you’re building a chatbot, fine-tuning a model, or using LLMs for enterprise applications, LM Studio is a versatile platform that caters to both beginners and advanced users.
Fine Tuning Local LLMs
Fine-tuning is one of the core advantages of using LLMs locally. It enables you to personalize your AI systems, ensuring they deliver state-of-the-art performance on tasks unique to your domain.
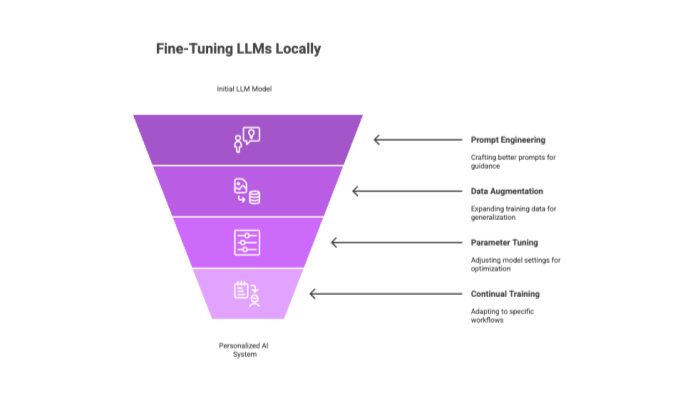
Fine-Tuning Techniques
Prompt Engineering: Crafting better prompts to guide model behavior with minimal retraining.
Data Augmentation: Expanding training data to improve generalization.
Parameter Tuning: Adjusting model settings like learning rate and batch size.
Continual Training: Training with your own datasets to adapt to specific workflows.
Fine-tuning on a local machine gives you the flexibility to iterate quickly, experiment with specialized models, and maintain complete control over your training process.
LLM Tools for Local Deployment
Several leading LLM tools now dominate the space for running models locally, each offering unique features for different users. These tools enable users to run models directly on their own hardware, providing greater privacy and control over their AI workflows. Running local llms is especially important for those seeking cost savings and enhanced data security, as it eliminates reliance on cloud-based services.
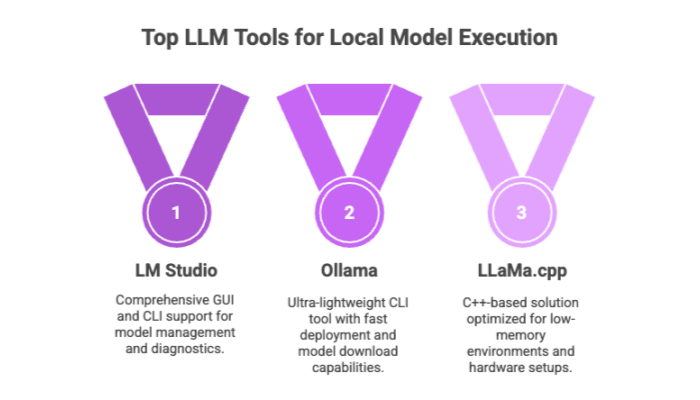
Top Tools to Run LLMs Locally in 2025
LM Studio
GUI + CLI support
Performance diagnostics and model management
Ollama
Ultra-lightweight CLI tool with fast deployment capabilities
Supports download models directly from repositories
LLaMa.cpp
C++-based solution optimized for running LLaMA models efficiently
Designed for low-memory environments and different hardware setups
These tools are tailored to provide minimal setup required, fast performance, and full access to model parameters, empowering users to run open source models and their own customized builds with ease.
Running LLMs Locally: Practical Guide
Getting started with running LLMs locally is more straightforward than ever, thanks to user-friendly local LLM tools and minimal setup requirements.
First, assess your hardware to ensure it meets the minimum specifications for your chosen model size—larger models demand more computational resources, while smaller models can run efficiently on standard consumer hardware. Next, select a local LLM tool such as LM Studio, Ollama, or GPT4All, and follow the installation instructions for your operating system. Once installed, download the desired LLM model and configure it within the tool.
With just a few steps, you can begin running LLMs locally, experimenting with applications like code generation, language translation, and creative writing. For those seeking optimal performance, fine tuning your model and monitoring resource usage will help you get the most out of your local deployment.
Local Deployment Considerations
To maximize the benefits of running local LLMs, understanding the interplay between hardware capabilities, software compatibility, and scalability is crucial. This section covers essential considerations such as GPU requirements, memory optimization, and support for various operating systems. We also explore how different hardware setups impact the ability to run larger models or multiple models simultaneously, ensuring optimal performance and resource management for your local deployment.
Hardware, Compatibility, and Scaling
When deploying a local LLM, choosing the right hardware and ensuring compatibility are essential for achieving optimal performance. Your local machine should run a supported operating system and have enough GPU memory and storage to handle the demands of your selected model—especially if you plan to work with larger models or multiple LLMs locally.
It’s important to verify that your hardware is compatible with your preferred local LLM tools, as some tools are optimized for specific platforms or hardware configurations. As your needs grow, consider scaling up your computational resources to accommodate more complex tasks or larger models.
By carefully matching your hardware to your deployment goals, you can ensure smooth operation and make the most of your local LLM setup.
Local LLM Use Cases
The range of practical applications for local LLMs is broad and growing fast. Because they run entirely on a local machine, they offer flexibility, security, and performance unmatched by many cloud-based LLMs.
Common Applications
Coding Tasks: Use local models for code generation, review, and refactoring.
Language Translation: Translate documents and websites with minimal setup, offline.
Creative Writing: Draft blog posts, stories, scripts, or poetry using specialized models.
Chatbots and Assistants: Build interactive AI-powered interfaces that don’t rely on cloud APIs.
Enterprise and Personal Use
Whether you’re an enterprise user managing compliance requirements, or a hobbyist interested in building tools with LLMs locally, use cases span:
Secure document analysis
Educational tools
Legal text review
Customer support automation
Internal knowledge base Q&A systems
Evaluating LLMs’ Performance
Performance is a core criterion when choosing the best local LLM for your project. Fortunately, local environments allow for complete visibility into how models behave and how to optimize them.
Performance Evaluation Metrics
Response Time: The latency in processing queries or generating text.
Token Throughput: Tokens processed per second, especially critical in longer conversations.
Memory Usage: RAM and GPU consumption during model execution.
Accuracy: How correct and relevant the model outputs are in specific domains.
Tools and Techniques
Use built-in profiling in LM Studio or CLI tools like Ollama.
Evaluate outputs against curated datasets.
Test how well a model adapts to prompt engineering techniques.
By testing across use cases and collecting performance metrics, users can optimize model parameters and ensure optimal performance tailored to specific needs.
Local LLM Security and Ethics
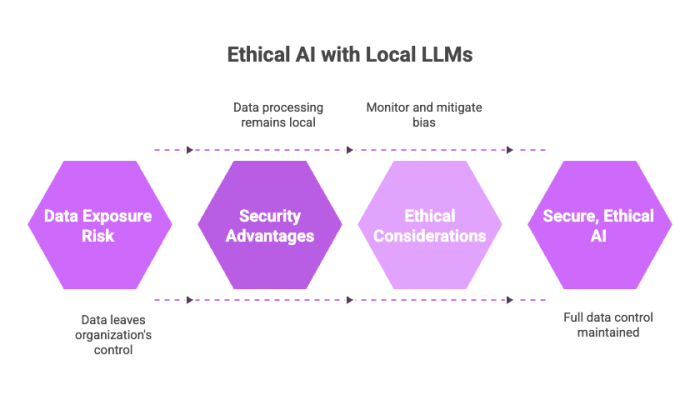
Running LLMs locally gives organizations the tools to build ethical AI systems while maintaining full control over their data processing practices.
Security Advantages
No data exposure: All processing remains on your own computer or local server.
Vendor independence: Avoid vendor lock-in and ensure future-proof operations.
Proprietary data protection: Keep confidential or regulated data safe.
Ethical Considerations
Bias control: You can monitor and mitigate bias through fine tuning.
Model transparency: By running open source models, you understand how the model was trained.
Auditability: Retain complete logs and conversation history without third-party oversight.
When deploying AI in areas like healthcare or education, these ethical and security benefits are not just best practices—they’re essential.
Community and Resources
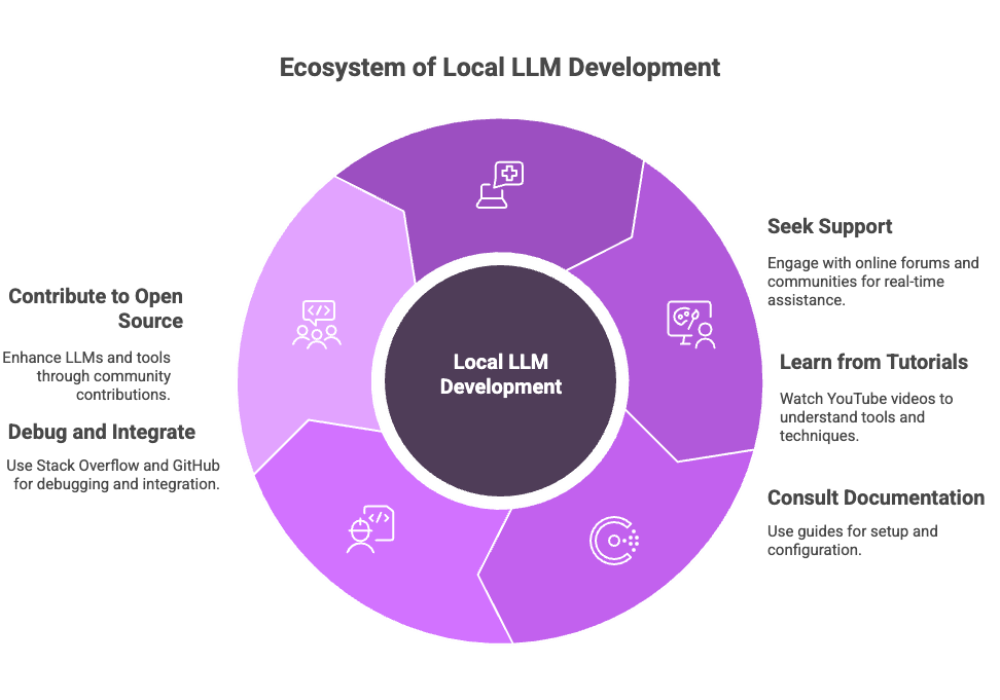
The ecosystem around local LLMs is expanding rapidly. Whether you’re looking for help configuring models, exploring new tools, or sharing your own builds, there are countless resources available.
Top Resources for Local LLM Developers
Online Forums: Reddit, Hugging Face forums, and Discord channels offer real-time support.
YouTube Videos: Tutorials on LLM tools, fine tuning, and prompt engineering for specific tasks.
Documentation: Most tools like LM Studio and Ollama provide comprehensive setup and configuration guides.
Stack Overflow & GitHub: Ideal for debugging, custom integrations, and discovering emerging techniques.
Open Source Community
Developers worldwide contribute to improving open source LLMs, creating web UIs, improving model files, and refining deployment scripts. Engaging with the open source community ensures you stay on the cutting edge and have a support network as you scale.
Final Thoughts: Choosing the Best Local LLM Tool for You
The decision to switch to running models locally hinges on several factors: control, privacy, cost, and performance. To ensure smooth installation, setup, and optimal performance, it's crucial to choose the right tool for your specific hardware, use case, and expertise. Fortunately, with a wide array of LLM tools and models available in 2025, you’re no longer locked into centralized, subscription-based solutions.
Recap of Top Tools
LM Studio: Best for all-in-one local deployment with a polished intuitive interface.
Ollama: Great for fast, efficient CLI-based deployment.
LLaMa.cpp: Ideal for lightweight, custom solutions on limited local hardware.
What to Look for:
Does it support multiple models?
Is there minimal setup required?
Can it be customized and fine-tuned for specialized models?
Does it integrate well with your existing infrastructure?
Why It Matters?
Running LLMs locally gives you complete control over your AI model, performance, and data. It aligns with modern demands for data privacy, cost savings, and scalable AI.

