
Guide to Local LLM: Setup, Tools, and Best Practices
In recent years, local LLMs (Large Language Models) have emerged as a compelling alternative to cloud-based AI services. These models allow users to run powerful AI tools directly on their own computer, providing greater control, security, and privacy. This setup eliminates the dependence on third-party providers, ensuring that sensitive data stays within your local environment.
The demand for large language models has surged across industries, from software development and content creation to data analysis and customer support. While cloud-based solutions offer convenience, they often come with subscription fees, internet connection dependencies, and potential data privacy concerns. For sectors like healthcare, finance, and legal services, where compliance and confidentiality are non-negotiable, local deployment of LLMs is not just an advantage—it's a necessity.
Running LLMs locally means you have full control over model parameters, configuration, and access, reducing the risk of data exposure and enabling tailor-made AI experiences.
Key Takeaways
Running local LLMs on your own hardware offers significant cost savings, enhanced security, and full control over sensitive data without relying on third party providers.
Choosing the best models and local LLM tools like LM Studio or Ollama with support for various model formats ensures optimal performance and seamless integration on your operating system.
Employing techniques such as fine tuning, retrieval augmented generation, and leveraging versatile platforms enables customization and improved capabilities for specific applications while maintaining privacy and reducing dependence on cloud based LLMs.

Local Deployment Options
In this section, we'll explore various methods and tools available for running local LLMs. Whether you prefer working directly on your own hardware or leveraging user-friendly platforms, understanding these options will help you choose the best approach tailored to your needs and resources.
Running LLMs Locally on Your Machine
Thanks to significant strides in consumer hardware and model optimization, it's now feasible to run LLMs locally even on mid-range systems. You no longer need enterprise-grade infrastructure to benefit from the capabilities of large models.
Key Local Deployment Approaches
Local Machine: Run models directly on your laptop or desktop.
Local Server: Ideal for multi-user environments, offering greater processing power and accessibility.
External Tools and Platforms: Tools like LM Studio and Ollama abstract the complexities of setup and offer an intuitive interface.
These deployment methods provide flexibility based on use case, budget, and technical expertise.
Choosing the Best Models for Local Deployment
Selecting the best models depends on multiple factors:
Model size and context length requirements
Computational capacity of your local hardware
Target use cases: e.g., code generation, translation, summarization
Popular Models for Local Deployment
LLaMA: High-performance open-source LLM from Meta, ideal for various local tasks.
Qwen: A scalable model architecture offering competitive performance and flexibility.
Mistral, TinyLlama, and Gemma: These smaller models are well-suited for resource-constrained systems.
Fine tuning these base models for domain-specific tasks can significantly boost relevance and efficiency.
Local LLM Tools and Platforms
To effectively run local LLMs, selecting the right tools and platforms is crucial. This section introduces some of the most popular and user-friendly options available today, highlighting their key features and benefits. Whether you prefer graphical interfaces or command-line utilities, these tools simplify the process of deploying and managing large language models on your local machine.
LM Studio
A leading tool for running local LLMs, LM Studio provides a web interface, command-line support, and minimal setup experience. Users can download models and start running them without deep technical knowledge.
Key features include:
-
Single executable installer
Integrated model marketplace
GPU/CPU toggle support
Ollama
Ollama emphasizes simplicity and seamless integration. Once you install Ollama, you can load and run models with just a few commands.
Key features:
Fast installation via CLI
Support for fine tuning
Minimal memory footprint
Versatile Platforms
LangChain: Known for building LLM-powered apps, it supports chaining local and remote models with external tools.
Hugging Face: The go-to platform for open source models and community-driven contributions.
Transformers Library: Enables easy integration of large language models LLMs into local applications using Python.
Hugging Face and Transformers: Essential Tools for Local LLMs
When it comes to running local LLMs, having access to the right user interfaces and model formats is crucial for a smooth experience. Hugging Face serves as a comprehensive hub where developers can find a vast collection of open source models, including many specialized models designed for specific tasks. These models are optimized to run efficiently on various computational resources, making them suitable for deployment on your local machine.
The accompanying Transformers library simplifies integration by supporting multiple operating systems and enabling seamless use of large language models through an easy-to-use API. Whether you want to run a single executable file or build complex AI applications, Hugging Face and Transformers provide the foundation for effective local deployment of popular LLMs.
Hugging Face: The Open Source Hub
Hugging Face is a central repository for open source LLMs, offering thousands of pre-trained models ready for local use. Whether you're interested in closed source models or open source LLMs, the platform supports both through model cards, version control, and community feedback.
Transformers Library
Built by Hugging Face, this library is essential for:
Loading models via a few lines of code
Enabling retrieval-augmented generation
Supporting both fine tuning and inference
Transformers streamline the process of embedding local LLMs in production-ready applications with cross-platform compatibility.
Local AI and LLMs
Local AI represents a growing paradigm where AI models are trained, deployed, and executed entirely on local hardware. This shift empowers users with autonomy and data sovereignty, especially critical in privacy-sensitive environments.
Benefits of Local LLMs
Reduced latency: No cloud roundtrips, faster response times.
Improved security: Your data never leaves your system.
Cost savings: No subscription fees or high compute cloud bills.
Though still in the early stages, the local AI movement is picking up pace, driven by the open-source community and tools designed for easy installation and local scalability.
Installing and Running LLMs Locally
Modern local LLM tools make running local LLMs remarkably accessible. Here's how you can get started:
Minimal Setup with LM Studio or Ollama
Install the tool on your preferred operating system (Windows, macOS, Linux).
Download models like LLaMA or Mistral directly through the interface.
Configure model parameters such as temperature, top-p, or max tokens.
With LM Studio, it's a matter of launching the intuitive GUI and selecting a model. With Ollama, a simple terminal command can do the same.
LLMs Locally: Use Cases and Applications
Running local LLMs on your own hardware unlocks numerous advantages, including enhanced privacy, reduced latency, and significant cost savings. By leveraging machine learning models that run locally, organizations can process sensitive data securely without relying on a third party provider. This section highlights practical applications and benefits of deploying large language models directly on your local machine.
Core Applications
Language Translation: Translate documents in real-time with no cloud dependency.
Text & Code Generation: Draft emails, content, or scripts directly from your local model.
Data Analysis: Integrate with spreadsheets or local documents for contextual understanding.
Industry Use Cases
Healthcare: Analyze patient data without breaching HIPAA.
Finance: Automate compliance reports securely.
Education: Provide offline tutoring and assessment tools.
Running LLMs locally enables businesses to tailor AI to their exact workflows without compromising security.
Fine Tuning and Optimization
Fine tuning allows developers to adjust open source models for domain-specific tasks, improving performance and relevance.
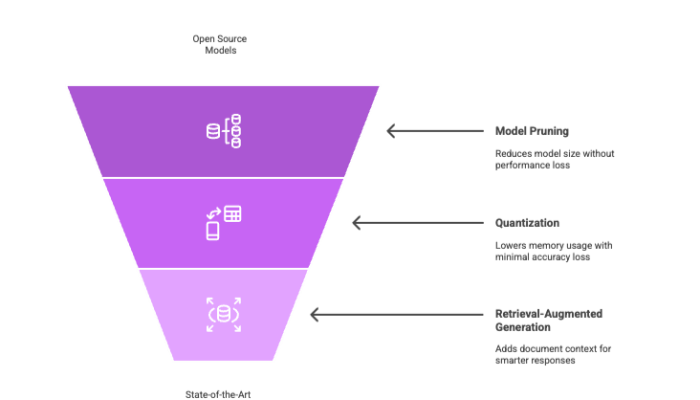
Optimization Techniques
Model pruning: Reduces size while maintaining performance.
Quantization: Lowers memory usage with minimal accuracy loss.
Retrieval-Augmented Generation: Adds document context from local documents to generate smarter responses.
These strategies ensure state-of-the-art results on modest systems, enhancing the quality and speed of outputs.
Model Evaluation and Validation
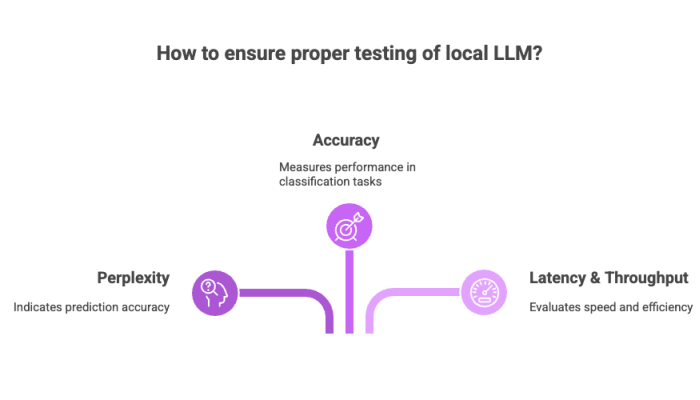
Before deploying any local LLM, proper testing is critical.
Key Metrics
Perplexity: Indicates how well the model predicts a sample.
Accuracy: Especially relevant for classification or QA tasks.
Latency & Throughput: Measure how fast and efficiently models run on your system.
Tools like evaluation frameworks or synthetic benchmarking help validate model files and outputs.
Security and Privacy Considerations
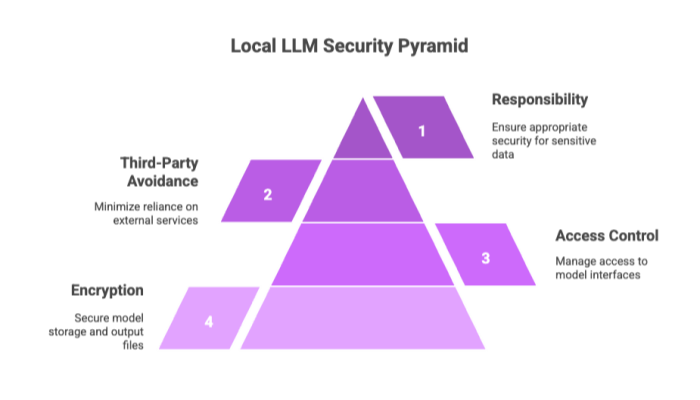
Local LLMs offer a privacy-centric approach, but implementation must be secure.
Security Best Practices
Encryption of model storage and output files
Access control for model interfaces
Avoid use of third-party providers for any auxiliary processing
When you run LLMs locally, you assume responsibility for sensitive data—make sure to secure it appropriately.
Community and Support Resources
As more developers and organizations embrace local LLMs, the open source community supporting these tools has grown rapidly. Whether you're a beginner trying to download models for the first time or an advanced user optimizing model parameters, the community offers abundant help.
Where to Find Support
GitHub: Repositories for tools like LM Studio, Ollama, and Transformers often include issues, FAQs, and discussions.
Discord & Reddit: Community-run spaces where developers share tips, updates, and troubleshooting advice.
Documentation & Tutorials: Comprehensive guides are available directly on project sites and platforms like Hugging Face and LangChain.
Having access to a thriving support network ensures smoother adoption and ongoing innovation for those working with local LLM tools.
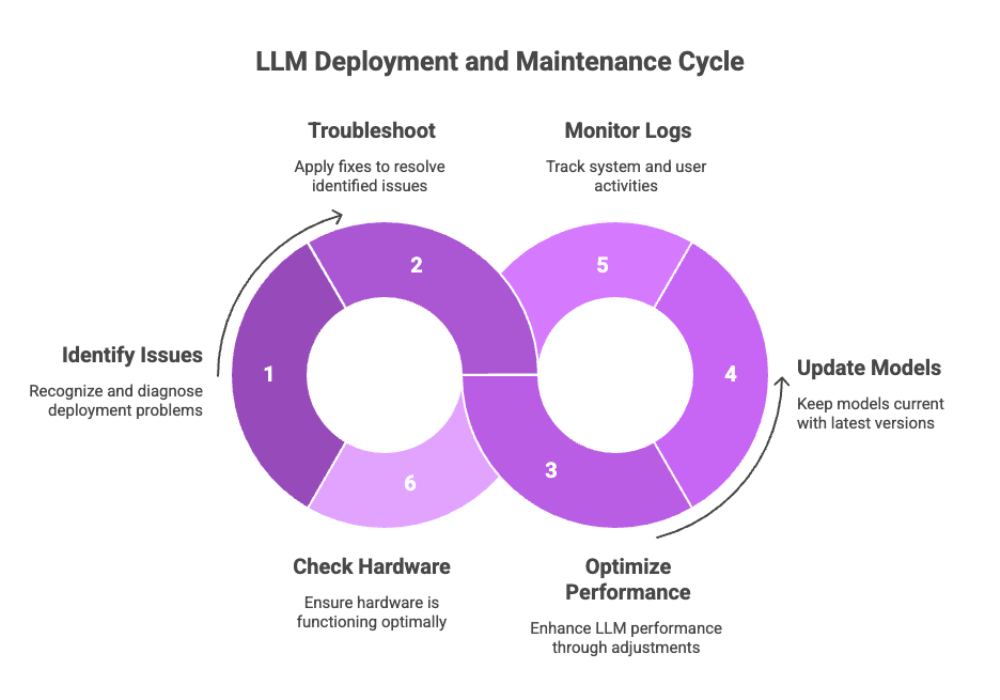
Troubleshooting and Maintenance
Deploying LLMs locally isn’t always seamless. Issues may arise with model compatibility, operating system differences, or GPU support. Effective troubleshooting and ongoing maintenance are essential.
Common Issues and Fixes
Installation Errors: Use verbose logging (--debug or -v) to identify dependency or environment problems.
Model Crashes: Ensure you're using optimized versions for your hardware, and that the model size fits available memory.
Latency Spikes: Try caching or reducing batch size for better performance.
Maintenance Practices
Model Updates: Keep your model files and tool versions up-to-date to benefit from performance and security patches.
Log Monitoring: Use logs to track anomalies, memory usage, and user interactions.
Hardware Health: Monitor your GPU/CPU temperatures and RAM usage, especially for continuous deployments.
Future Developments and Trends
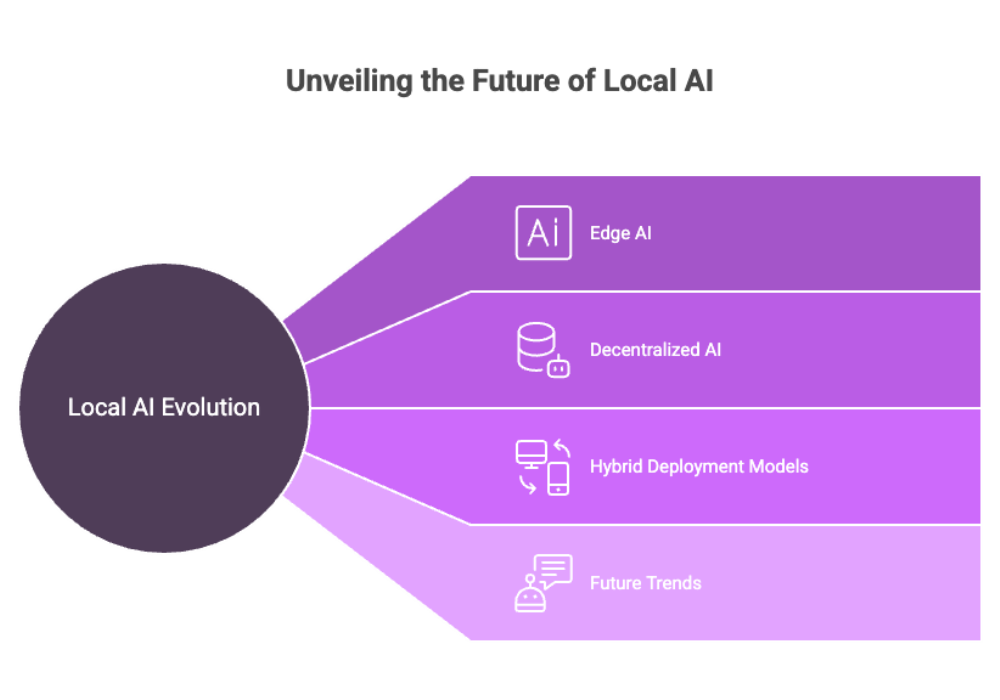
The landscape of local AI is evolving rapidly. With innovations in model compression, hardware acceleration, and decentralized computing, local LLMs are becoming more accessible and powerful.
Key Trends
Edge AI: Running LLMs on embedded or mobile devices, increasing offline AI capabilities.
Decentralized AI: Peer-to-peer AI systems where local models collaborate without central servers.
Hybrid Deployment Models: Combining local inference with cloud-based fine-tuning for balance between performance and scalability.
What's Next?
Expect smaller models with competitive performance, increased interoperability between tools, and better web interface options for non-technical users.
Local LLMs Recommendations
Local LLMs offer a viable, efficient, and secure alternative to cloud-hosted AI systems. They empower users with full control over data and models, eliminating reliance on third-party providers.
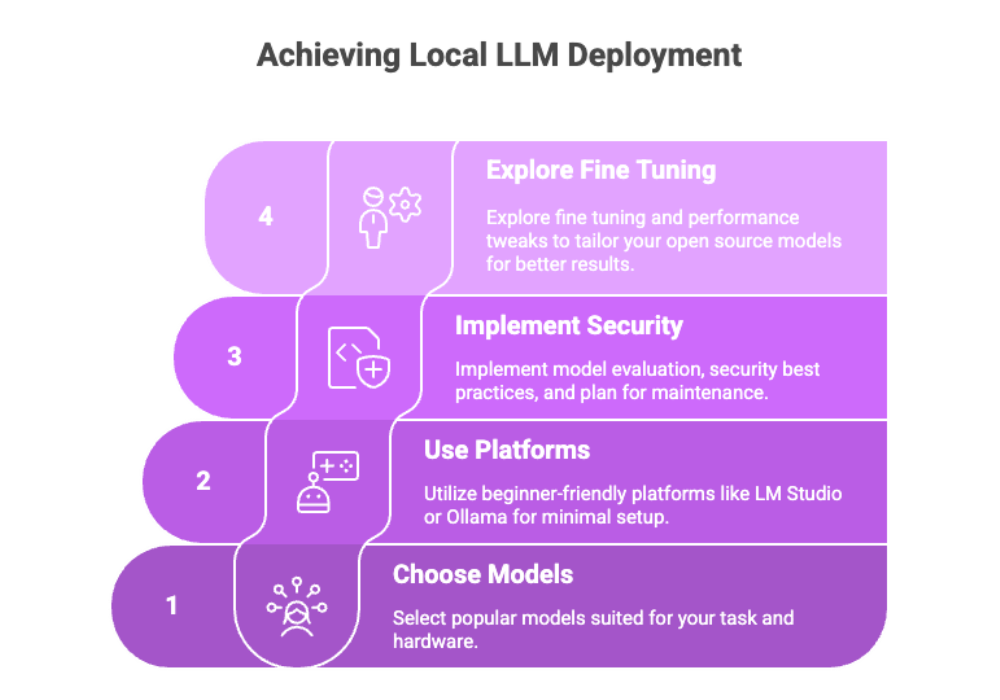
Key Recommendations
Choose popular models suited for your task and hardware.
Use beginner-friendly platforms like LM Studio or Ollama for minimal setup.
Implement model evaluation, security best practices, and plan for maintenance.
Explore fine tuning and performance tweaks to tailor your open source models for better results.
With continued advancements in open source LLMs, local deployment is poised to become the standard in AI adoption across industries.
Local LLM Setup and Configuration
Setting up local LLMs requires planning and an understanding of both software and hardware limitations. From choosing the right model to configuring runtime parameters, careful setup determines the optimal performance of your deployment.
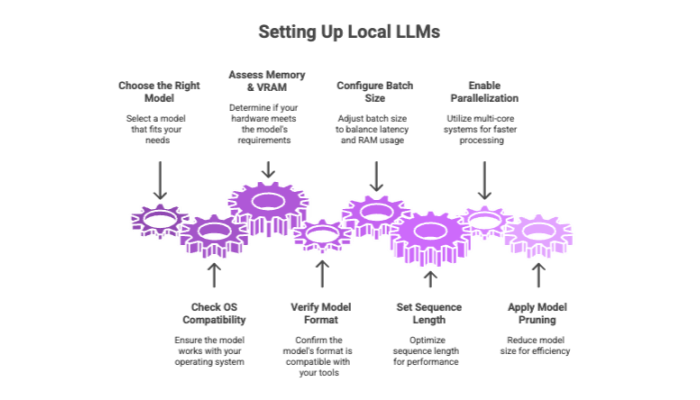
Key Considerations
Operating system compatibility: Some tools are OS-specific, so choose versions for Windows, macOS, or Linux accordingly.
Memory & VRAM: Larger models may require GPU support or system optimization like swap memory.
Model formats: Ensure compatibility with tools like .gguf or .pt formats used by Ollama and Transformers respectively.
Configuration Tips
Batch size and sequence length: These settings directly affect latency and RAM usage.
Parallelization: If using multi-core systems, configure threading options.
Model pruning: Helps reduce unnecessary layers for smaller, more efficient models.
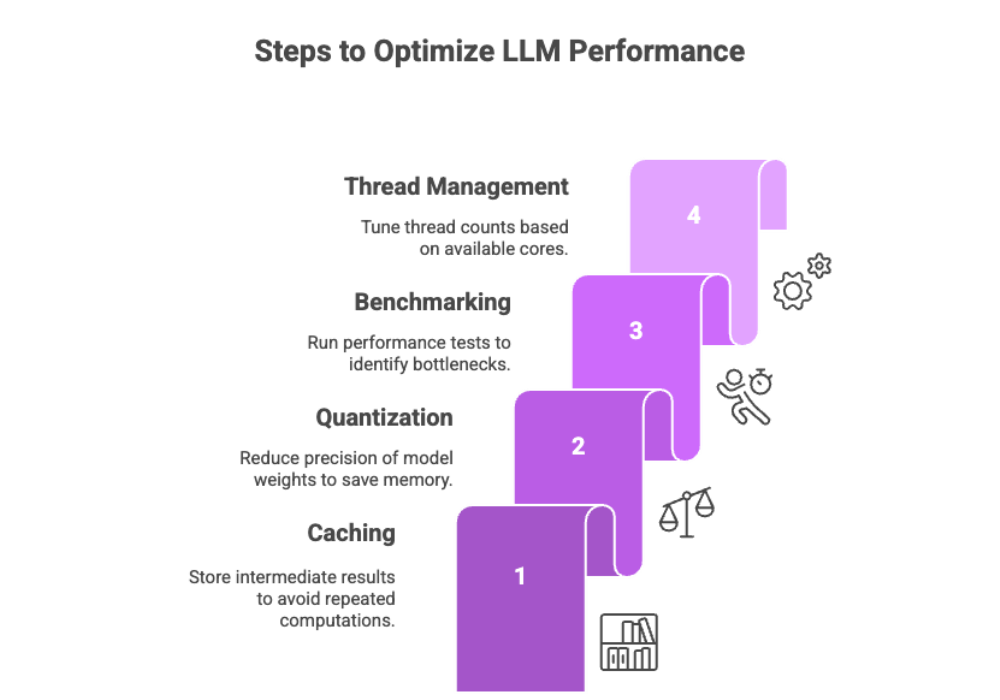
Local LLM Performance Optimization
Optimizing performance is critical to ensure LLMs locally deliver fast and reliable results.
Techniques to Improve Performance
Caching: Store intermediate results to avoid repeated computations.
Quantization: Reduce precision of model weights (e.g., from FP32 to INT8) to save memory.
Benchmarking: Run performance tests with different settings to identify bottlenecks.
Thread management: Tune thread counts based on available cores.
Tools That Help
LM Studio has built-in profiling tools.
Transformers offers model optimization scripts.
Use third-party profilers like NVIDIA Nsight or Intel VTune.
Local LLM Integration and Interoperability
Deploying local LLMs in isolation limits their potential. Integration with other systems, APIs, or apps creates a holistic AI environment.
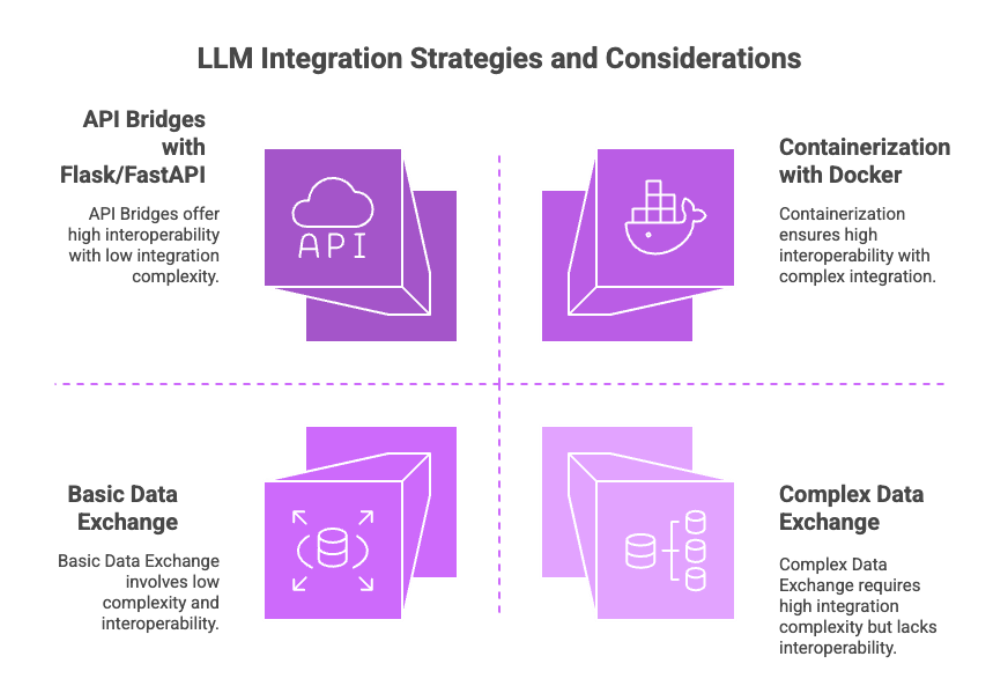
Integration Strategies
API Bridges: Use Flask/FastAPI to serve models via RESTful endpoints.
Data Exchange: Connect with databases or file systems to interact with external data sources.
Containerization: Package models with Docker for easy deployment across different systems.
Interoperability Considerations
Follow standard model formats like ONNX or GGML.
Check compatibility between toolchains (e.g., LangChain + Ollama).
Avoid vendor lock-in by choosing open source models and frameworks.
Local LLM Scalability and Flexibility
Although initially designed for small-scale use, local deployment of LLMs can be scaled effectively.
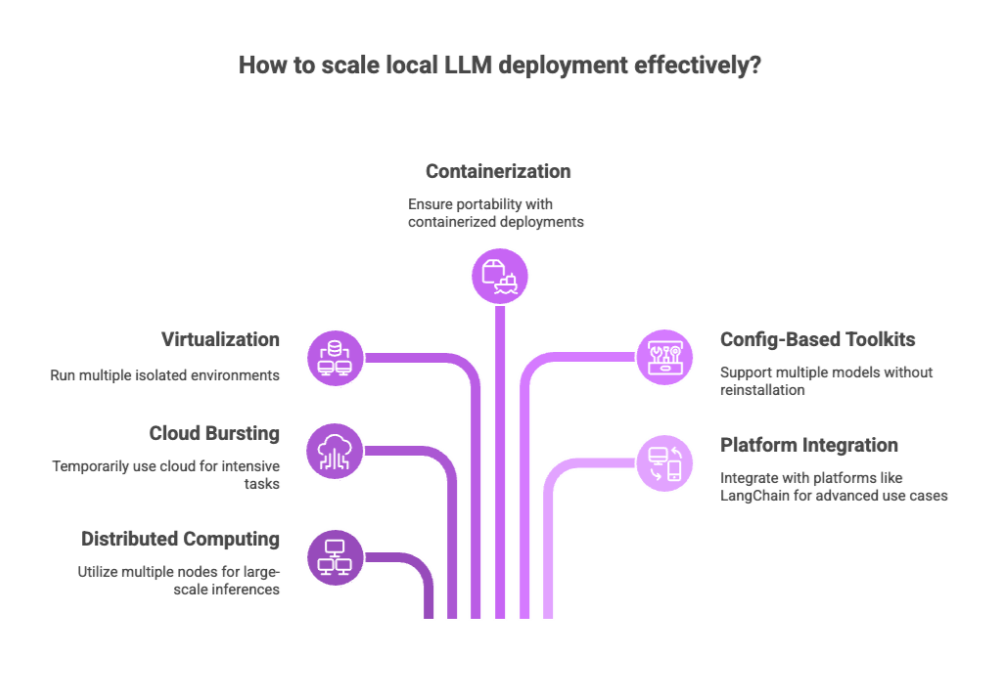
Methods for Scaling Local LLMs
Distributed computing: Use multiple nodes or machines to run large-scale inferences.
Cloud bursting: Temporarily use cloud for intensive tasks while maintaining local model ownership.
Virtualization: Run multiple isolated environments for different tasks or users.
Enabling Flexibility
Adopt containerized deployments for portability.
Use config-based toolkits to support multiple models without reinstallation.
Integrate with versatile platforms like LangChain for advanced use cases.
Local LLM Cost and Resource Considerations
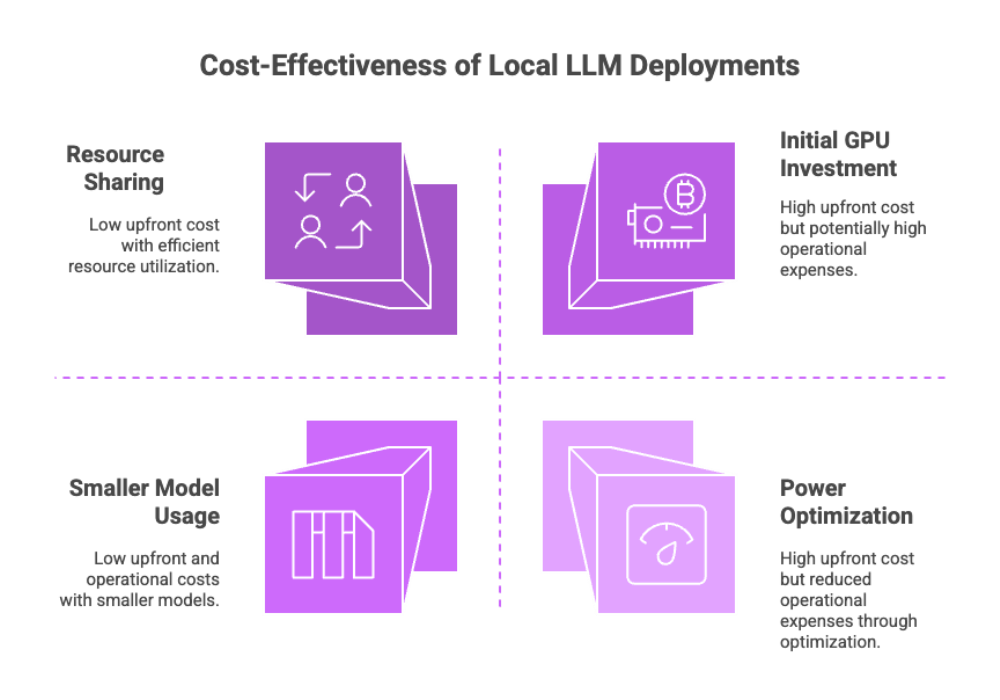
Unlike cloud-based LLMs, local deployments involve upfront costs for hardware but lower operational expenses over time.
Key Factors to Consider
Hardware cost: Investing in a GPU or upgrading RAM may be necessary.
Power consumption: Local inference can be power-intensive—optimize for efficiency.
Maintenance costs: Consider time and effort for troubleshooting and updates.
Cost-Effective Practices
Use smaller models where suitable.
Share resources across teams using a local server setup.
Monitor usage to avoid resource bottlenecks with logging tools.
Local LLM Ethics and Responsibility
Deploying AI—especially local AI—demands strong ethical grounding to ensure fairness, transparency, and safety.
Ethical Considerations
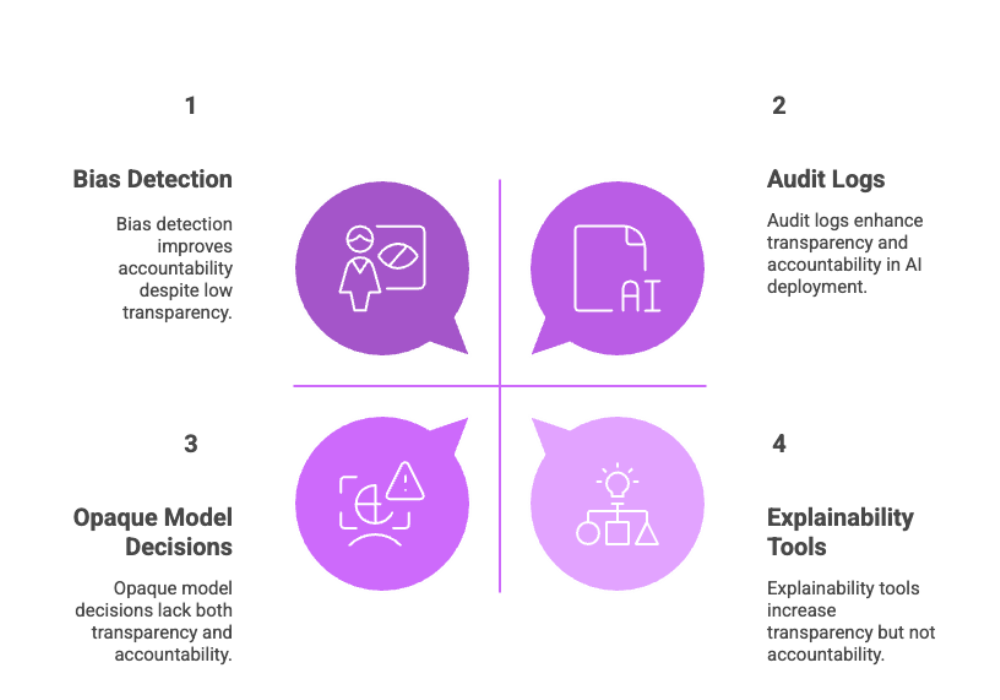
Bias Detection: Regularly test model outputs for bias using benchmark datasets.
Explainability: Use tools like SHAP or LIME to interpret model decisions.
Accountability: Maintain audit logs and transparent deployment records.
Running LLMs locally adds layers of privacy but doesn't exempt developers from ethical obligations. It’s important to foster trust by making systems understandable and inclusive.
Final Thoughts
The rise of local LLMs signals a significant shift in how organizations and individuals approach AI. By adopting local model deployment, you gain unmatched control, privacy, and customization.
Whether you're optimizing a fine tuned model for your company’s workflows or experimenting with open source models at home, the tools, communities, and resources are more accessible than ever.
By understanding key features, maintaining secure setups, and staying engaged with the open source community, you’ll be well-positioned to harness the full power of running LLMs locally.

