
Essential Guide to the GPT-OSS Benchmark: Performance Insights & Tips
The release of OpenAI's GPT-OSS models marks a significant step forward in the world of open-source large language models. Designed with a focus on deep reasoning, efficient inference, and flexible deployment, these models offer developers powerful tools to tackle complex tasks across coding, math, science, and more. This guide provides an in-depth look at GPT-OSS's architecture, benchmarking methodologies, and best practices to help you understand and leverage their capabilities effectively.
Key Takeaways
-
Balanced Performance and Efficiency: GPT-OSS models deliver frontier-level reasoning and multi-step problem-solving abilities while maintaining efficient inference through sparse Mixture-of-Experts architecture and precision optimizations.
-
Flexible Reasoning and Tool Use: With adjustable reasoning levels and support for agentic workflows, GPT-OSS enables developers to tailor model behavior for diverse applications, balancing accuracy, speed, and cost.
-
Open-Source and Community-Driven: The permissive license and transparent design empower the AI community and enterprises to audit, adapt, and deploy GPT-OSS models with minimal restrictions, fostering innovation and collaboration.

1) Introduction to OpenAI GPT-OSS Models
OpenAI GPT-OSS models are open-weight, production-oriented foundation models with deep-reasoning capability and a sparse Mixture-of-Experts (MoE) architecture. They are offered in two headline scales—GPT-OSS 20B and GPT-OSS 120B—to balance scale, price, and speed across target applications.
Both models support agentic workflows (tool use, function calling, structured outputs) and are tuned for reproducible evaluation under standardized prompts. The family emphasizes efficient inference while retaining strong general-purpose performance in coding, math, science, and multilingual tasks.
A permissive, open-source release enables the AI community and enterprise developers to audit, adapt, and deploy with minimal restrictions.

2) GPT-OSS Architecture (MoE, Attention, Precision)
- Sparse MoE. Router networks activate a small subset of experts per token, yielding high effective capacity with bounded latency.
- Attention stack. Grouped-Query Attention (GQA) reduces memory traffic; rotary position embeddings stabilize long-context extrapolation.
- Forward pass efficiency. Optimized kernels reduce time per forward pass at a given batch size; continuous batching improves utilization in production.
- Precision. Mixed formats (e.g., FP8-style / MXFP4 or NVFP4) target minimal accuracy loss with meaningful energy savings.
- Reasoning controls. “Low/medium/high” reasoning levels modulate depth, tool-use propensity, and scratchpad usage during generation.
3) Model Variants
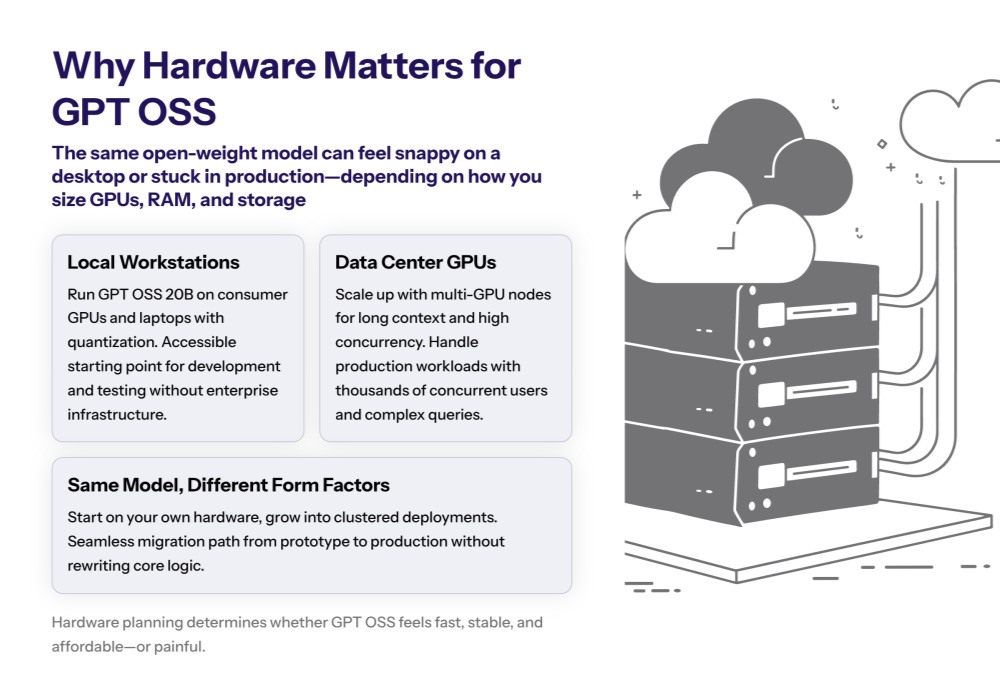
OpenAI GPT-OSS offers two primary model variants designed to balance performance, efficiency, and deployment flexibility. These variants cater to different use cases, from latency-sensitive applications to deep reasoning tasks requiring extensive computational resources.
3.1 gpt oss 20b model
A ~20.9B-parameter MoE configured to activate ~3.6B parameters per token.
-
Goal. Running efficiently on single-GPU or edge servers (≈16 GB class with quantization).
-
Use. Latency-sensitive assistants, on-device analytics, and agentic workflows with tight cost controls.
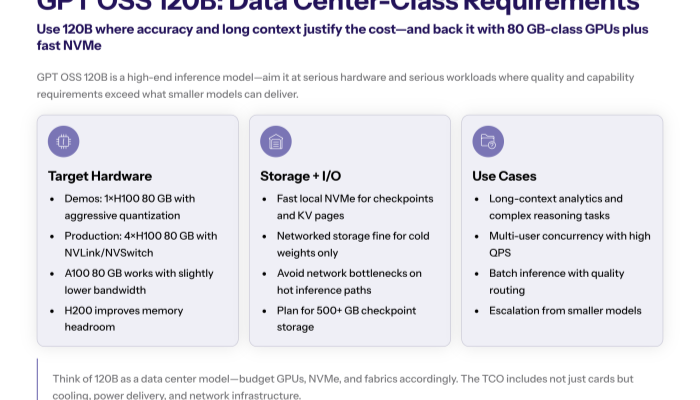
3.2 gpt oss 120b
A ~116–117B-parameter MoE with ~5B active parameters per token.
-
Goal. Maximize complex reasoning depth and long-horizon synthesis where accuracy dominates price.
-
Use. High-stakes decision support, difficult multi-step math/science, and large-document analysis with extended context.

4) Benchmarking Methodologies (Toward fair comparison)
- Task mix. Include reasoning (AIME-style), coding, science QA, and multilingual to cover diverse functions and skills.
- Prompt templates. Standardize system prompt and chat schema (e.g., harmony chat format) to eliminate template variance.
- Decoding policy. Fix temperature, top-p, and output schema constraints; log seed and nucleus settings for reproducibility.
- Compute context. Report hardware, batch size, precision, and maximum context window; pin tokenizer builds.
- Replications. Use ≥3 runs with bootstrap intervals; publish failures (timeouts, schema violations) to avoid silent bias.
- Key takeaway. A fair comparison requires controlling the full inference stack—not only the model checkpoint.

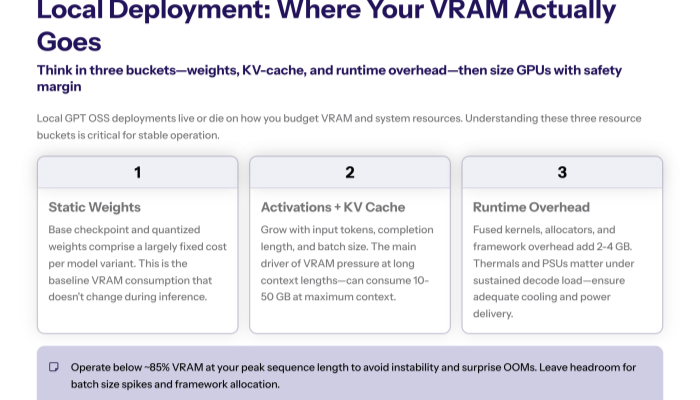
5) Performance Metrics (accuracy, latency, cost)
- Quality. Exact-match / pass@k for code; chain-of-thought rubric for reasoning; factuality scores for retrieval-grounded tasks.
- Latency.Time-to-first-token (TTFT). Sensitive to compile/warmup and prompt length. Tokens/sec (decode). Function of sampling strategy, parallelism, and KV-cache hits.
- Cost. Effective price per 1k tokens (prompt + completion) or per successful task instance; include tool-call overhead.
- Throughput. Requests/sec at target SLOs with medium reasoning; publish p50/p95 tails.
- Uptime. Failure rates on long prompts and large output objects; report “final JSON schema pass” success rate.
6) Reasoning Levels and Chain-of-Thought
- Variable reasoning levels. “Low/medium/high” adjust planning depth, tool call frequency, and scratchpad verbosity.
- Post-training. Chain-of-Thought reinforcement learning improves decomposition and function orchestration in agentic workflows.
- Evaluation. Benchmarks like AIME-style math, GPQA-Diamond, and structured STEM tasks stress long multi-step chains.
- Tip. Default to medium for interactive apps; escalate to “high” only when accuracy gains outweigh speed and price impacts.
7) Context Window Optimization
- Rotary embeddings. Enable stable scaling to extended context with less degradation.
- Prompt packing. Merge short messages to reduce wasted tokens; keep tool schemas outside the hot path when possible.
- Retrieval. Use RAG to externalize long data—reduce prompt bloat while preserving evidence traceability.
- Observation. Accuracy is moderately correlated with effective evidence density; longer is not always better.

8) Output Tokens and Generation (Decoding & Structure)
- Schema-constrained outputs. Enforce JSON schemas for function calls and structured answers; validate on the edge.
- Sampling. For reasoning, small temperature (e.g., 0.1–0.3) with moderate top-p stabilizes final answers; creative tasks may raise temperature.
- Hallucination control. Penalize unsupported claims; prefer retrieval citations; measure schema-pass rate as a hard performance metric.
- Forward pass vs. decode. The forward pass dominates TTFT; decode throughput dominates total time for long output sequences.

9) Agentic Tool Use and Harmony
- Harmony chat format. A standardized “system-user-assistant-tool” scaffold with explicit tool schemas reduces prompt drift across API providers.
- Tool stack. Browsing tool, code function execution, vector retrieval, and calendar/knowledge calls are common primitives.
- Auditability. Log tool arguments, return payloads, and the “final” stitched answer to support governance and post-mortems.
- New format. Where needed, a “plan → act → verify → final” variant surfaces intermediate intent for safety review.
10) Artificial Analysis & External Benchmarks
- Composite indices. Use multi-suite dashboards (e.g., MMLU-Pro, GPQA-Diamond, “Humanity’s Last Exam”) to triangulate capability.
- Model-card lens. Combine headline scores with safety/FalseReject, multilingual stability, and long-context robustness.
- Key takeaway. No single number captures capability; publish performance metrics as a vector with uncertainty bounds.
11) Deployment Strategies (Cloud, On-Prem, Edge)
- Two sizes, one API. Route by hardness: start on 20B; escalate to 120B when “high” reasoning materially raises correctness.
- Quantization. INT8/INT4 reduces footprint for 20B at small accuracy deltas; validate final task quality.
- Parallelism. Tensor/expert parallelism for 120B; careful dependencies and NUMA placement to avoid poor resource utilization.
- Providers. Multi-home across API providers; maintain prompt parity and decoding defaults to keep results comparable.
12) Environment Setup for Benchmarking
- Determinism. Pin seeds, tokenizer, and library versions; record kernel capabilities (Flash-style attention availability).
- Workload. Use an orchestration script that enforces identical message templates, line-delimited JSON logs, and structured details.
- Measurement. Capture TTFT, tokens/sec, tool-call count, schema-pass rate, and cost per instance.
- Artifacts. Store prompts, system note, and final outputs; publish a minimal hf/Git snapshot for reproducibility.

13) Best Practices for Evaluation
- Fair comparison. Keep prompts, seeds, and decoding policies identical; disclose cache warmup and retry policies.
- Ablations. Report sensitivity to temperature/top-p, medium vs. high reasoning, and context truncation.
- Coverage. Include examples that require tool use, long-context reasoning, and multilingual inputs.
- Risk. Track harmful content filters, FalseReject rates, and refusal quality under safety constraints.
14) GPT-OSS Use Cases
- Operations. Root-cause summaries and incident timelines from heterogeneous data streams.
- Coding. Secure function stubs, test generation, and static analysis with structured SARIF outputs.
- Knowledge work. RAG-grounded drafting with citations; controlled production of policy-conformant reports.
- Edge AI.On-prem assistants and kiosks using 20B quantized for minimal footprint and privacy.
15) Future Directions
- Pre-training data audits for factuality and bias; better scale laws for MoE routing efficiency.
- Planning. Stronger self-verification loops inside agentic workflows to reduce tool-call errors.
- Context. Learned retrieval and compression to push effective context window without linear cost growth.
- Metrics. Task-specific performance metrics beyond accuracy/latency—e.g., intervention value and operator time saved.
16) Tips & Quick Reference (C-Level Summary)
-
Default routing. Start with gpt oss 20b at medium reasoning; escalate selectively to gpt oss 120b for high-stakes tasks.
-
SLO guardrails. Track TTFT, tokens/sec, schema-pass rate, and unit price; publish p95s.
-
Prompt governance. Standardize on harmony chat format across all API providers to stabilize behavior.
-
Cost discipline. Use quantization and retrieval to shrink context; prefer schema-constrained final answers.
-
Fair comparison. Fix seeds, templates, and decoding; report uncertainty and failure modes alongside scores.
Appendix: Minimal Evaluation Pseudocode (illustrative)
for task in benchmark_suite:
prompt = render_harmony(system, user, tools, schema)
t0 = now()
resp = model.generate(prompt, temperature=0.2, top_p=0.9, reasoning="medium")
t1 = now()
metrics.log(
ttft=resp.time_to_first_token - t0,
toks_per_sec=resp.tokens / (t1 - t0),
schema_pass=validate(resp.final),
tool_calls=len(resp.tools),
cost=pricing.estimate(resp.tokens)
)
scorer.update(task, resp.final)
report(metrics.aggregate())This guide consolidates the benchmarking and deployment posture for GPT-OSS models, emphasizing fair comparison, transparent performance metrics, and pragmatic controls that yield reliable results in production.

