
How to Build a Private LLM: The Essential Guide for Developers
As artificial intelligence becomes deeply integrated into enterprise workflows, Private Large Language Models (LLMs) have emerged as a powerful solution for organizations seeking to process and generate human-like language in a secure environment. A large language model is a sophisticated neural network, often based on transformer architecture, trained on vast datasets to understand and generate text. Building a private large language model allows organizations to maintain control over sensitive data and tailor the model to their unique requirements.
Unlike public LLMs, private models provide complete control over training data, model architecture, and deployment pipelines. Many private LLMs are based on the generative pre trained transformer architecture, which enables advanced language understanding and generation. This makes them ideal for industries like finance, healthcare, law, and defense, where data privacy, regulatory compliance, and model explainability are mission-critical.
Private LLMs can be fine-tuned for specific NLP tasks — such as sentiment analysis, text summarization, and question answering — enabling domain-specific performance while minimizing reliance on external APIs or providers. Building your own large language model or own private llm gives organizations greater control and data security, supporting compliance and reducing third-party risks.
These models can be deployed on-premises or in secure cloud environments, ensuring that sensitive information remains protected. LLM models and llm model architectures can be customized for specific needs, allowing organizations to experiment with new techniques and optimize for their unique use cases.
By investing in a private LLM, organizations can unlock new capabilities, reduce costs, and gain a competitive edge by enhancing operational efficiency and supporting tailored solutions.

Introduction to Private LLMs
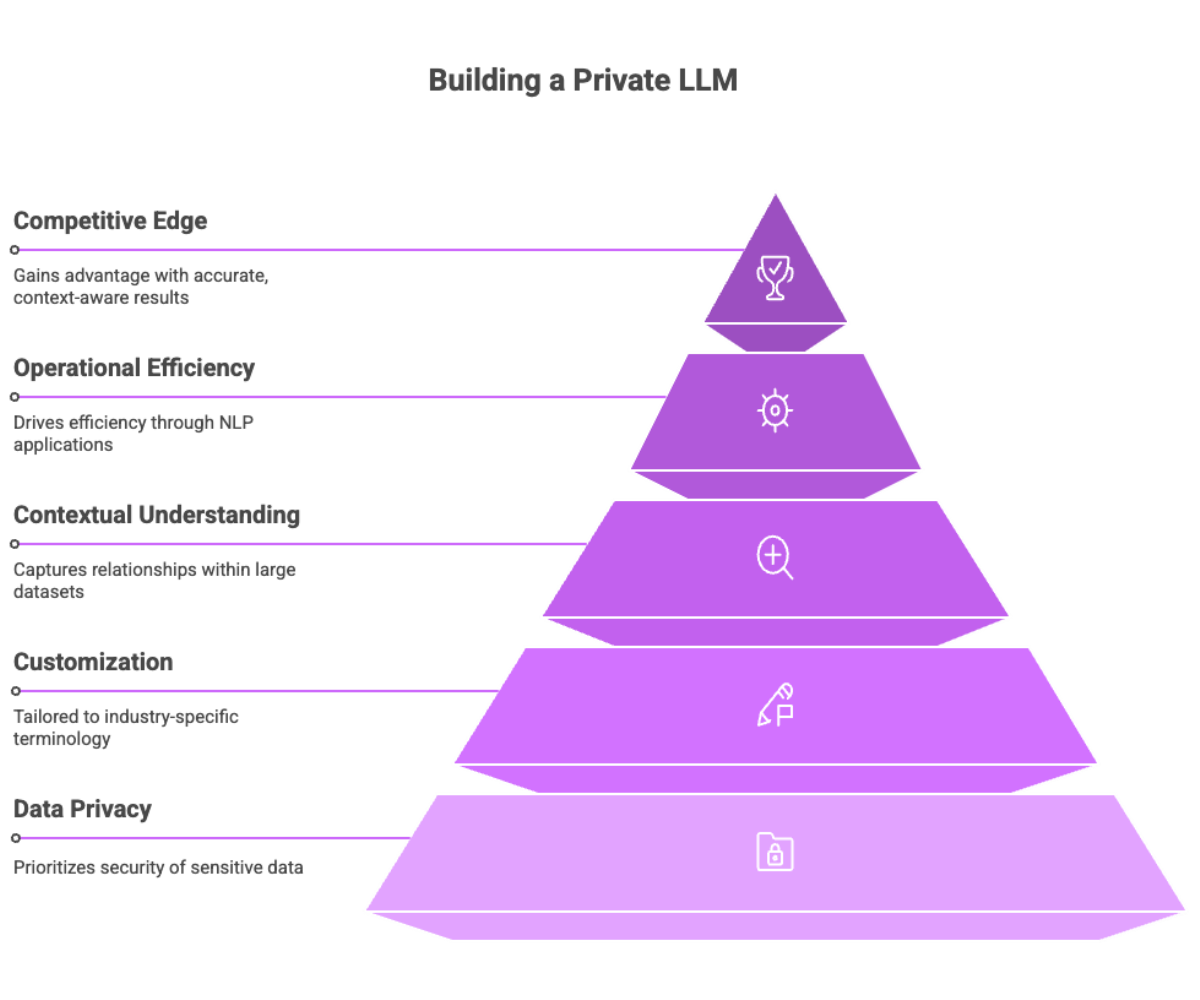
Private Large Language Models (LLMs) are advanced artificial intelligence systems designed to process, understand, and generate human language while prioritizing the privacy and security of sensitive data. Unlike public language models, private LLMs are built and fine-tuned using an organization’s own proprietary data, giving businesses complete control over how their data is handled, stored, and processed. This approach significantly reduces the risks associated with sharing sensitive information with external providers and helps ensure compliance with strict data privacy regulations.
By leveraging domain-specific data, private LLMs can be tailored to understand industry-specific terminology, internal workflows, and unique organizational knowledge. This customization enables private LLMs to deliver highly relevant and actionable outputs, outperforming generic models in specialized tasks. Whether it’s language translation, sentiment analysis, content generation, or other natural language processing (NLP) applications, private LLMs can be fine-tuned to meet the precise needs of the business.
A key advantage of building a private LLM is the ability to capture contextual relationships within large datasets, generating rich vector representations that enhance natural language understanding and support a wide range of NLP tasks. Organizations can use private LLMs to analyze customer feedback, automate document processing, and improve decision-making processes—all while maintaining strict control over sensitive data.
To build a private LLM, organizations should start by defining clear objectives, selecting the right model architecture, and collecting high-quality, domain-specific data. Pre-trained models can serve as a foundation, which can then be fine-tuned on proprietary data to achieve optimal performance. Implementing robust monitoring tools and access controls is essential to safeguard the model and ensure only authorized users can interact with sensitive information.
The significant advantages of private LLMs include enhanced data privacy, improved data governance, and the ability to deliver more accurate, context-aware results. By reducing dependence on external providers and retaining full ownership of their models and data, organizations can better protect sensitive information and comply with regulatory requirements. Ultimately, building a private LLM empowers businesses to unlock the full potential of natural language processing, drive operational efficiency, and gain a competitive edge in their industry.
Defining Objectives
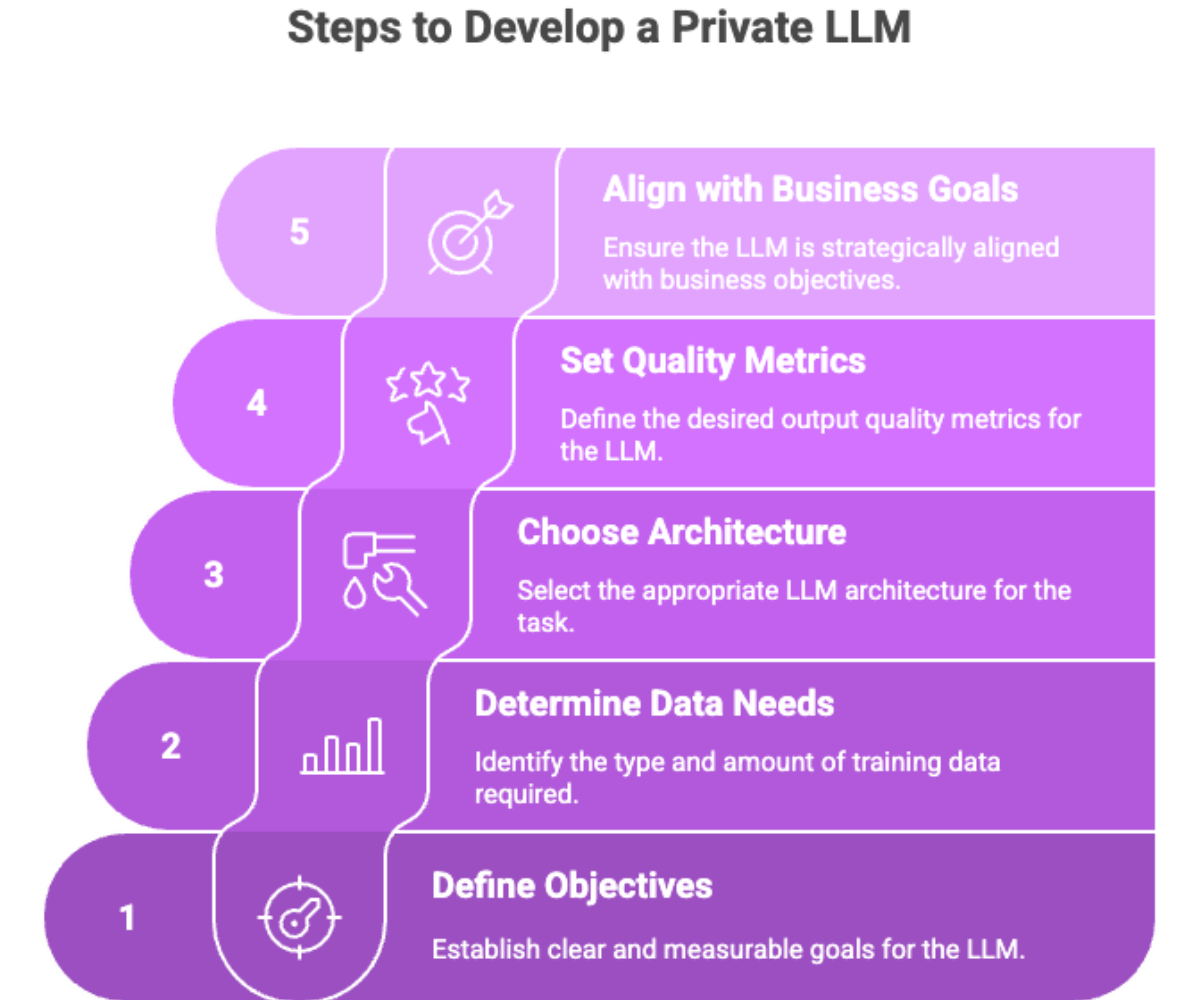
Before beginning the development of a private LLM, it’s crucial to define objectives that are clear and measurable. Your objectives will determine:
What type of training data is needed
Data acquisition strategies and associated costs for sourcing and managing data
Which LLM architecture to use (e.g., transformer-based models like LLaMA, Gemma, or Mistral)
Desired output quality metrics (e.g., F1 score, perplexity, model's accuracy)
Common goals include:
Enhancing customer behavior prediction
Improving document classification
Automating content generation workflows
Strengthening business intelligence capabilities
Adapting the model for specific tasks relevant to your business domain
For more insights on software development, AI strategies, and eCommerce tech trends, visit the Cognativ blog.
A well-defined objective ensures that your private LLM is strategically aligned with business goals and delivers tangible value.
Data Collection
A private LLM is only as good as the data it is trained on. Collecting high-quality input data, relevant data, and text data is essential for effective training and fine-tuning of your model. High-quality and domain-relevant training data is essential to achieve robust and context-aware model performance, and using your own data can further improve model outcomes.
Collecting and curating the right data also enables more effective data analysis with your private LLM.
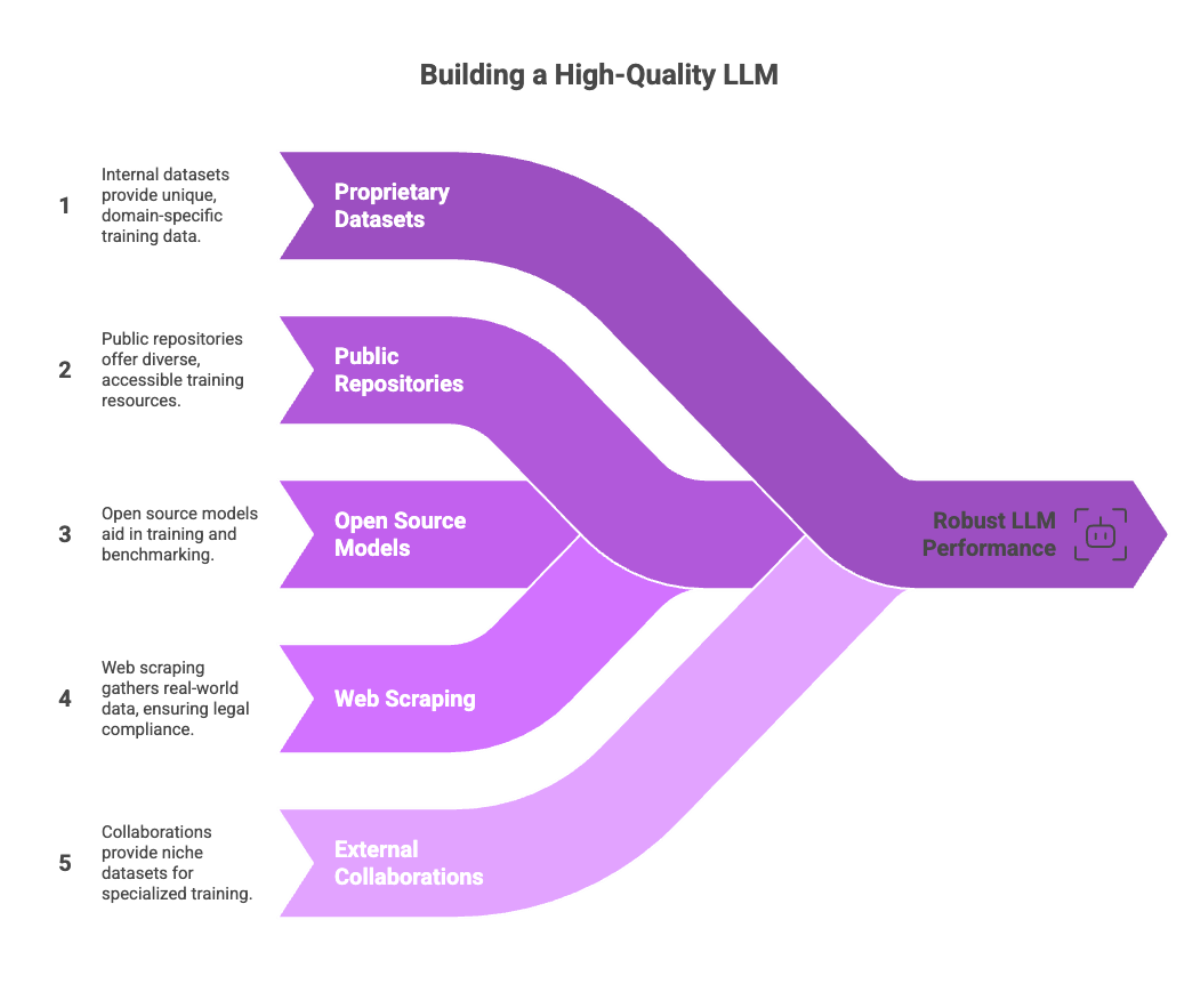
Effective data sources:
Proprietary internal datasets (CRM data, customer support tickets, internal documentation)
Public repositories and open datasets
Open source models and datasets as valuable resources for training and benchmarking
Web scraping (ensure legal compliance)
Collaborations with external providers for niche datasets
The goal is to gather a large, diverse, and balanced dataset that reflects the real-world language and use cases of your target domain.
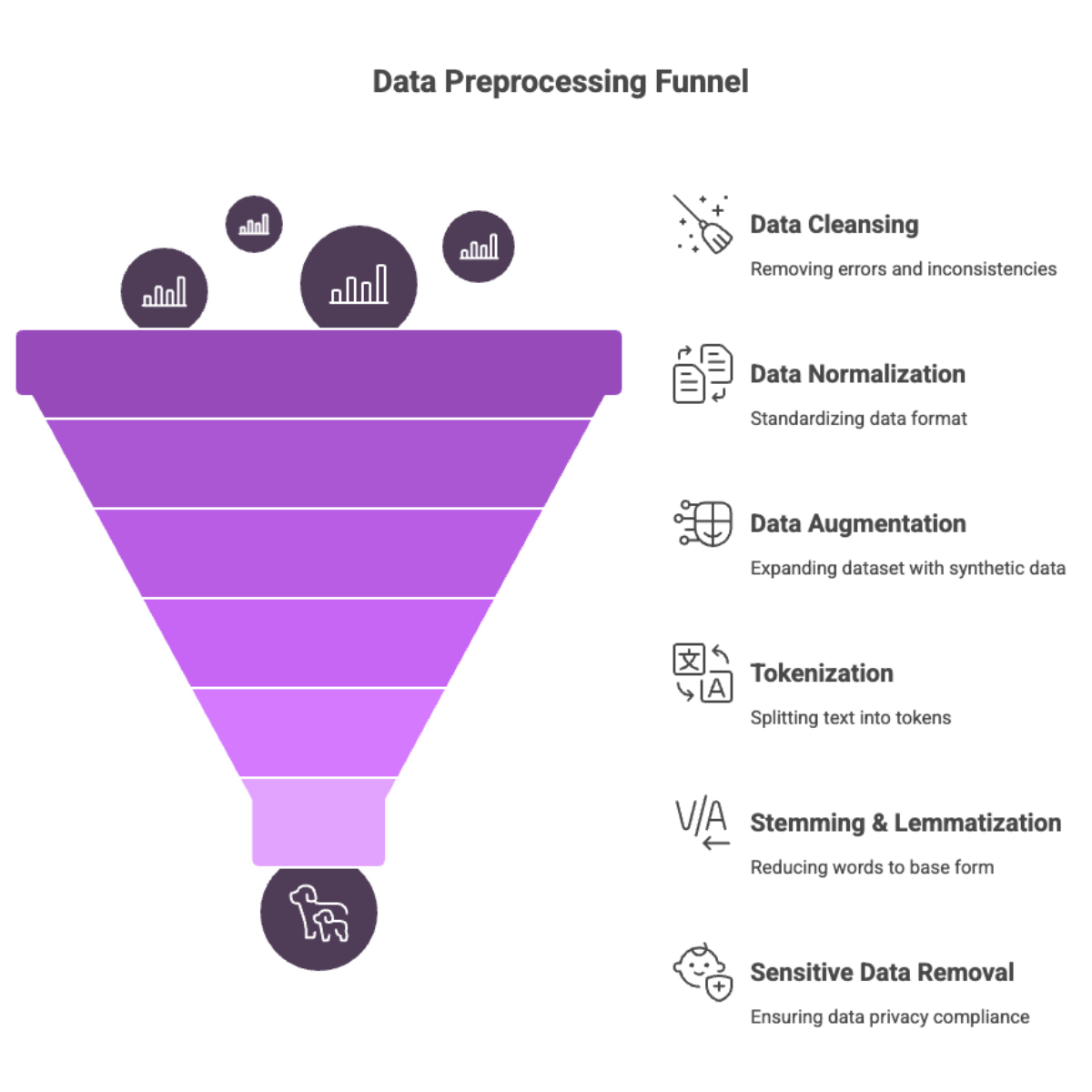
Data Preprocessing
Once collected, your data must be cleansed and normalized before it enters the training pipeline.
Additionally, data augmentation can be used to expand and diversify the training dataset, for example by generating synthetic data or paraphrasing existing examples to improve model training for instruction-following behavior.
Key preprocessing techniques:
Tokenization: Splitting text into words or subwords
Stemming & Lemmatization: Reducing words to their base/root form
Normalization: Lowercasing, punctuation removal, text filtering
Sensitive data removal: Use anonymization and redaction to comply with data protection laws (e.g., GDPR, HIPAA)
High-quality preprocessing ensures your model learns from clean, meaningful signals and avoids noise, bias, or misleading patterns.
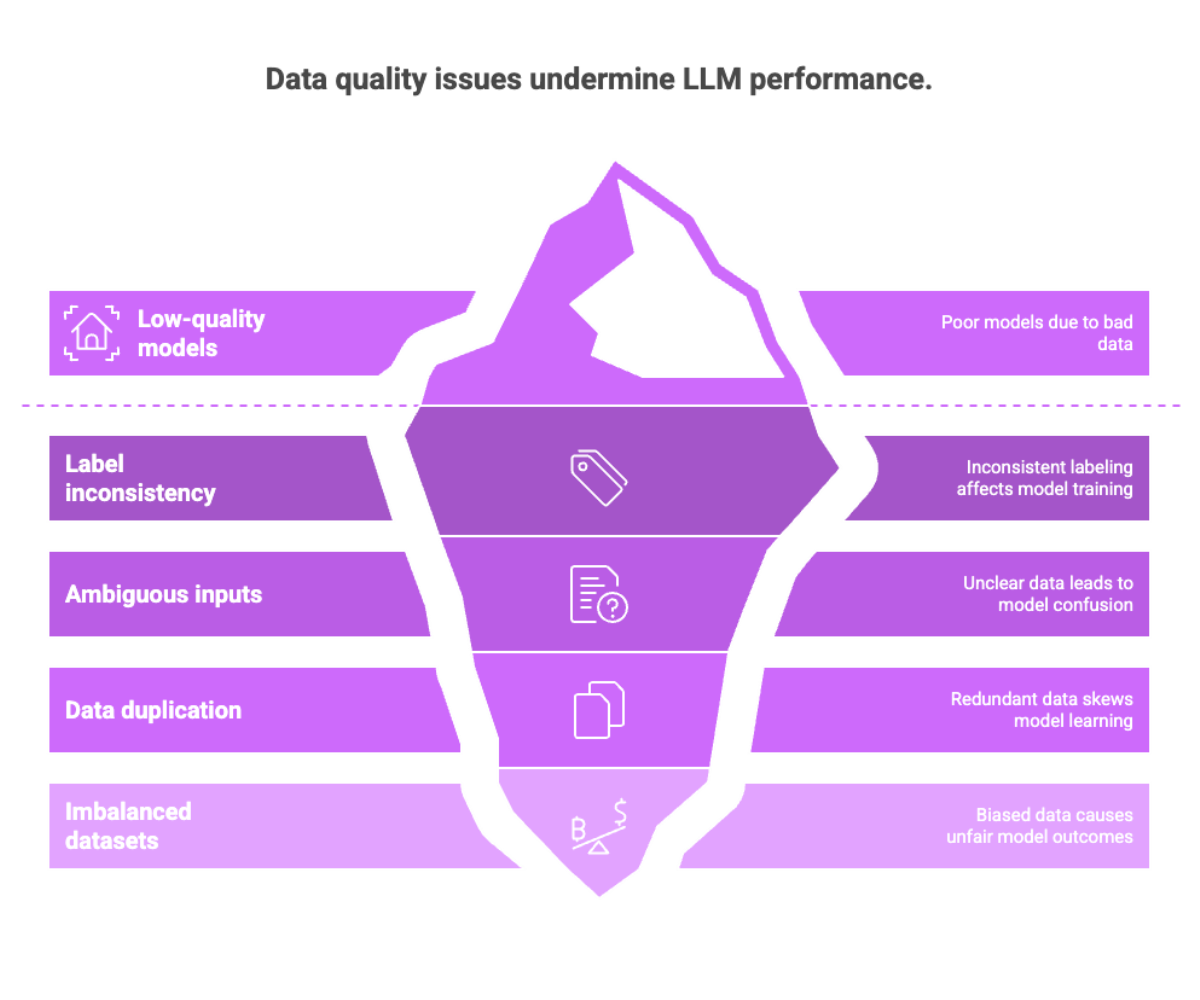
Data Quality
Low-quality data results in low-quality models — regardless of how powerful your architecture may be.
Common data quality issues:
Label inconsistency
Ambiguous or contradictory inputs
Data duplication
Imbalanced datasets
To mitigate these, implement:
Automated data validation
Manual data review
Bias detection tools
Maintaining high data integrity enhances your private LLM’s accuracy, fairness, and reliability.
Domain-Specific Data
To ensure your private LLM excels in its target use case, you must infuse it with domain-specific language, enabling the model to perform well across various NLP tasks.
Examples:
Legal contracts, statutes, or case law (legal domain)
Clinical notes, EMRs, and research abstracts (healthcare domain)
Product descriptions and reviews (e-commerce domain)
This tailored training ensures that the model learns contextual nuances, industry terminology, and user intent — enabling it to outperform general-purpose LLMs in specialized scenarios.

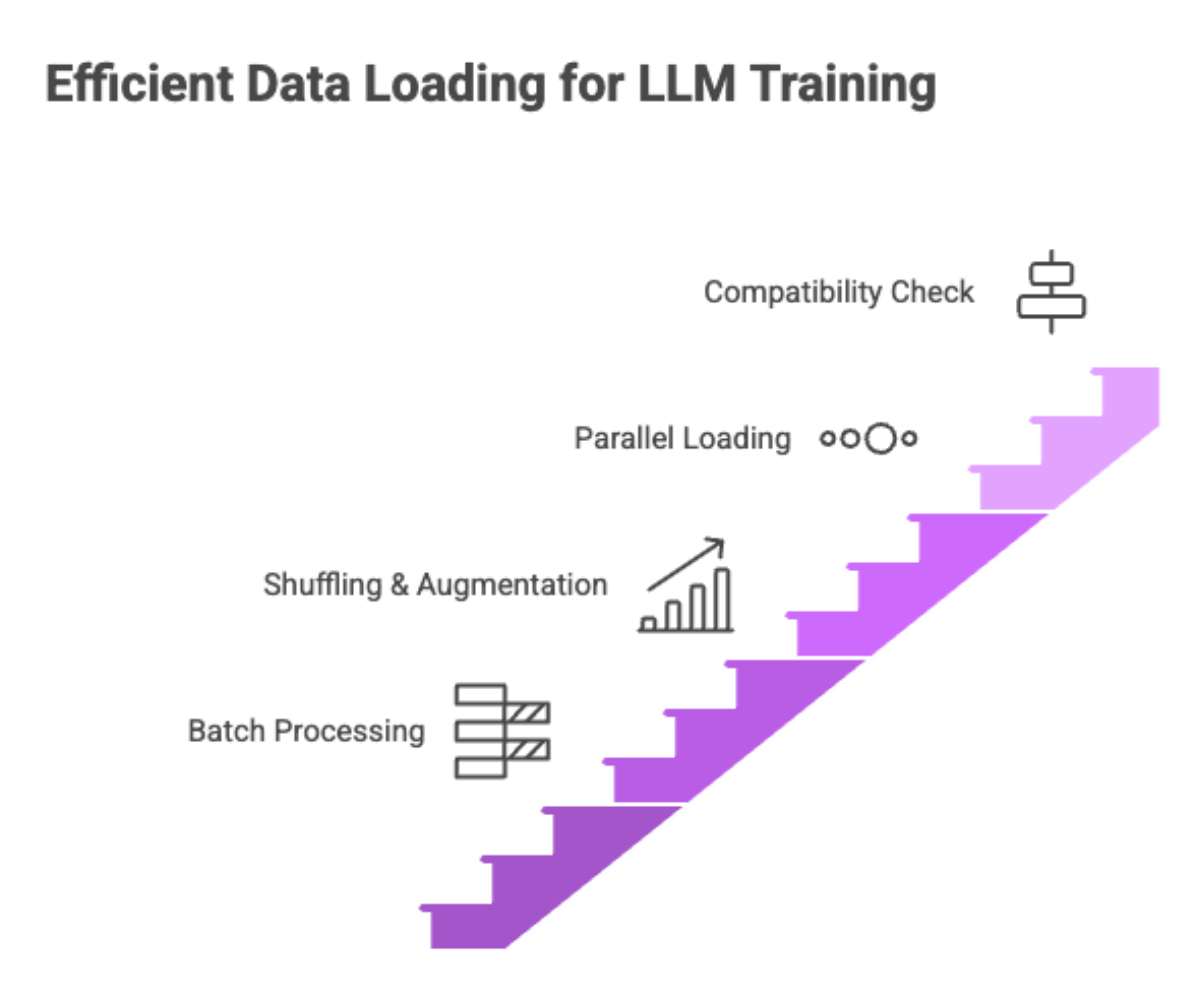
Data Loading
After preprocessing, your data must be efficiently loaded into the model for training, ensuring that the integrity of the input sequence is preserved for effective model training.
Data loading strategies:
Batch processing: Handles large volumes of data by dividing them into manageable chunks
Shuffling and augmentation: Prevents overfitting and improves generalization
Parallel loading: Reduces idle GPU/TPU time and boosts training throughput
Ensure compatibility with your LLM’s tokenizer and architecture during this step.
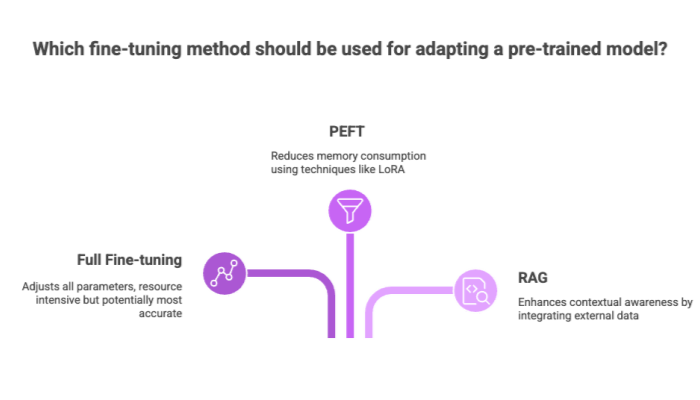
Fine-Tuning
Fine-tuning allows you to fine tune an existing model, such as a pre-trained model (e.g., LLaMA 3, Mistral 7B, Gemma 2B), and adapt it to your specific task or domain.
Fine-tuning methods:
Full fine-tuning: Adjusts all model parameters — resource intensive
Parameter-efficient fine-tuning (PEFT): Includes techniques like LoRA (Low-Rank Adaptation) or Adapters to reduce memory consumption
Retrieval Augmented Generation (RAG): Enhances contextual awareness by integrating external databases or document repositories
Fine-tuning ensures your private LLM can generate accurate, high-recall outputs for your unique data landscape.
Building a Private LLM: Infrastructure & Resources
Building a private LLM from scratch or fine-tuning an existing one demands a strong technical foundation and substantial computing resources. The choice of infrastructure and deployment strategy also depends on the technical expertise available within the organization.
Infrastructure Requirements:
High-performance GPUs/TPUs (NVIDIA A100, H100, etc.)
Distributed training frameworks (DeepSpeed, Horovod, or Hugging Face Accelerate)
Cloud or on-prem environments that allow scalable, containerized deployments
Storage systems for large datasets and checkpoints
Depending on your goals, you can deploy the model via:
Private cloud environments (e.g., AWS PrivateLink, Azure Confidential Compute)
Bare-metal servers for full control
Hybrid edge setups for regulatory reasons
A private LLM setup should support efficient parallelism, automatic mixed precision, and checkpointing to reduce training time and cost.
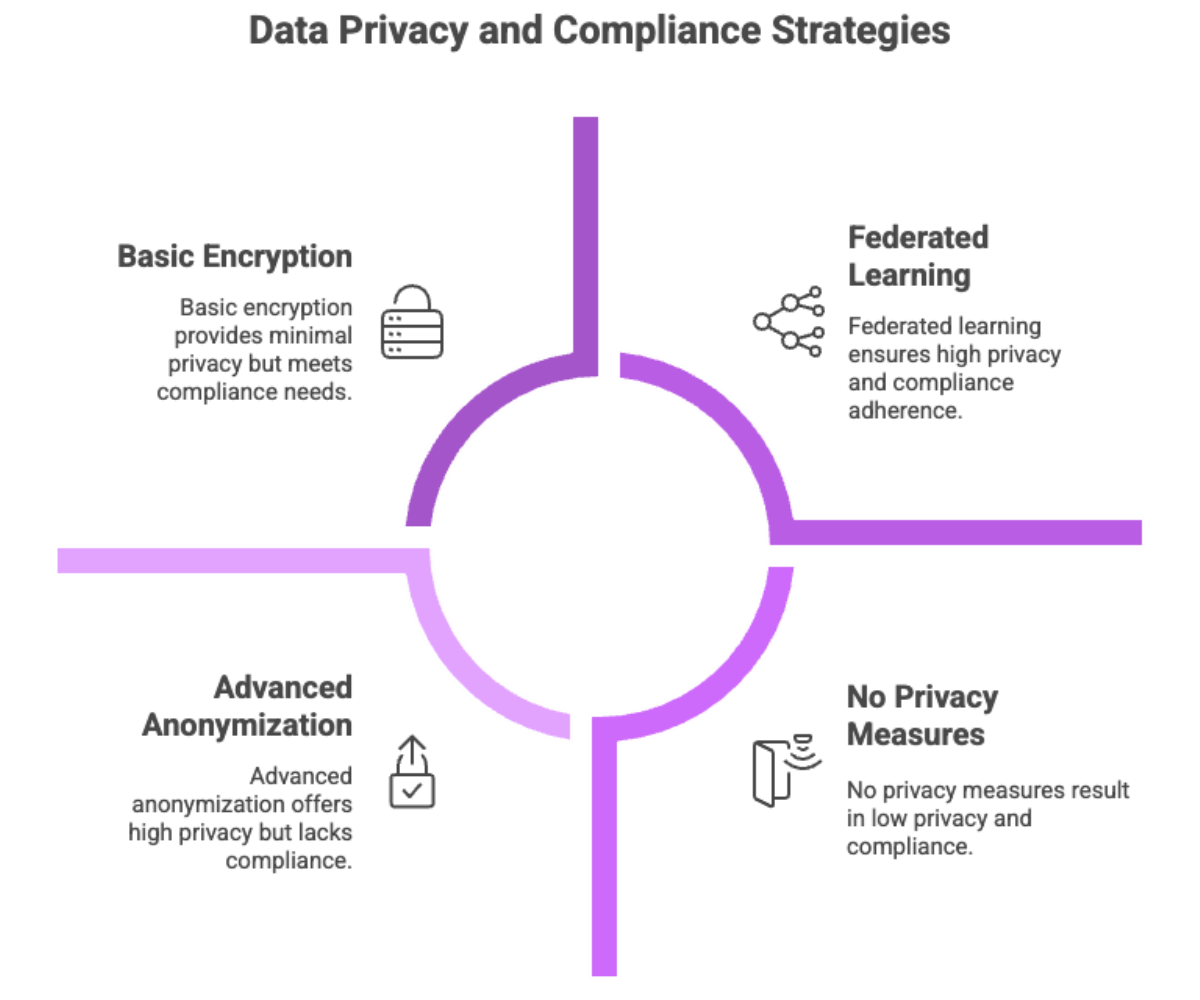
Ensuring Data Privacy
Protecting sensitive data is paramount when developing a private LLM, especially in regulated industries. Federated learning can be used to train models on decentralized data sources while preserving privacy, ensuring that sensitive user data remains on local devices and supporting compliance with regulations like GDPR and CCPA.
Data Privacy Best Practices:
Encryption: Apply AES-256 encryption for both data-at-rest and in-transit
Access controls: Implement RBAC and multi-factor authentication
Data anonymization: Use differential privacy or token masking for PII/PHI
Data logging restrictions: Disable logging of training prompts and outputs unless sanitized
Private LLMs must comply with:
GDPR (Europe)
HIPAA (Healthcare in the U.S.)
CCPA (California)
SOC 2 Type II for enterprise use
These techniques not only minimize compliance risks but also enhance user trust.
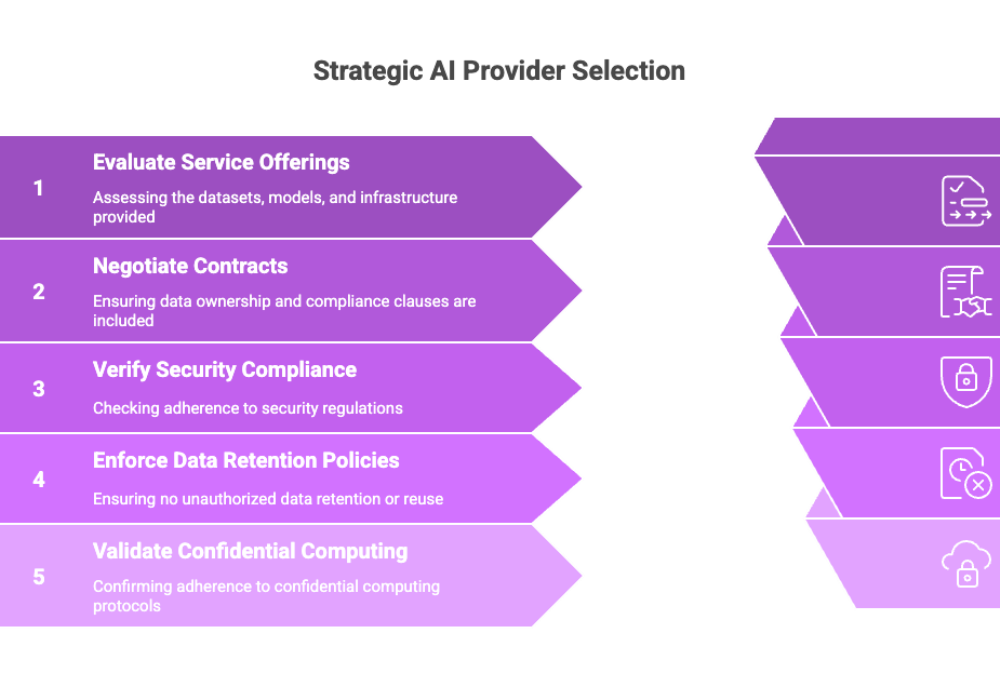
Working with External Providers
Sometimes, your organization may lack the in-house resources to build a private LLM entirely on its own. Partnering with external AI service providers can be a strategic move.
What They Can Offer:
Domain-specific datasets
Fine-tuned base models
Cloud compute infrastructure
Data labeling or annotation services
However, you must ensure:
Contracts include data ownership clauses
Providers comply with security regulations
Zero data retention or unauthorized reuse is allowed
Always validate that external providers adhere to confidential computing protocols and maintain transparent SLAs for auditability.
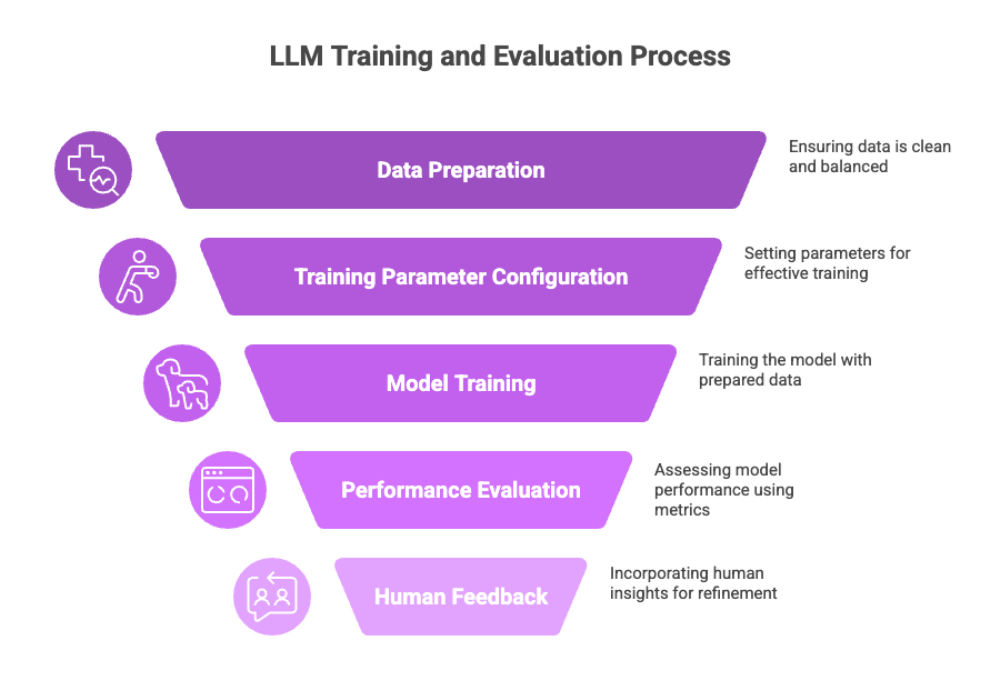
Model Training and Evaluation
Once your infrastructure is in place and data is ready, model training begins. Configuring appropriate training parameters is crucial for successful model training. This phase determines how well your LLM learns language patterns and aligns with your objectives, and monitoring model interactions is important for governance.
Key steps include:
Selecting the right architecture (e.g., autoregressive models, recurrent neural networks, bidirectional encoder representations, hybrid models) and initializing model weights.
Evaluating the model's performance using both quantitative metrics (like perplexity) and qualitative methods.
Using human evaluation to assess the quality of generated outputs.
Key Steps in Model Training:
Choose a base model architecture (transformers, decoder-only, encoder-decoder)
Feed clean, tokenized, and balanced training batches
Monitor loss functions, gradient norms, and training efficiency
Employ early stopping and learning rate schedulers
Evaluation Metrics:
Perplexity: Lower is better; measures how well a model predicts the next word
BLEU / ROUGE scores: Used in summarization and translation
Accuracy, Recall, Precision, F1-score: For classification tasks
Human feedback (RLHF): For generative or conversational applications
Tools like Weights & Biases, TensorBoard, or LLM eval harnesses help automate and track model performance over time.
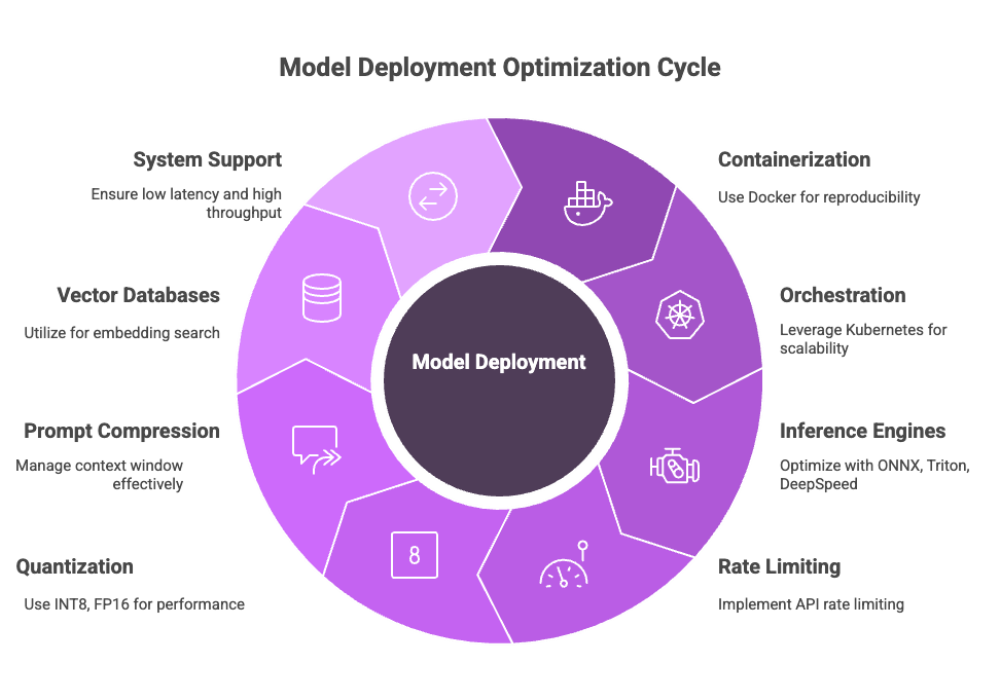
Deployment and Optimization
Once the model is trained and evaluated, it's time to deploy it in a production-ready environment.
Deployment Best Practices:
Use containerization (Docker) for reproducibility
Leverage orchestration frameworks (Kubernetes) for scalability
Serve the model with optimized inference engines (ONNX, Triton, DeepSpeed-Inference)
Implement API rate limiting and token usage monitoring
To further optimize inference:
Use quantization (INT8, FP16) for faster performance
Implement prompt compression and context window management
Utilize vector databases (e.g., FAISS, Pinecone) for embedding search and RAG
Ensure the system supports low latency, high throughput, and failover protocols for mission-critical workloads.
Maintenance and Lifecycle Management
Your private LLM is not a “set-it-and-forget-it” system. Regular maintenance ensures continued relevance, performance, and security.
Maintaining comprehensive documentation is essential to support ongoing model management, user education, and legal compliance. Additionally, it is important to ensure the model's operation adheres to ethical guidelines and promotes ethical usage, helping to prevent misuse and support responsible, compliant practices.
Ongoing Responsibilities:
Monitor for model drift and degradation
Schedule periodic re-training or continuous fine-tuning
Collect human feedback for further tuning (if applicable)
Update training data sources regularly to reflect real-world shifts
Additionally, maintain model version control, update documentation, and integrate auditing systems to ensure operational transparency.

Final Thoughts
Building a private LLM is a complex yet highly rewarding endeavor. It empowers organizations to:
Preserve data privacy
Gain competitive advantages
Stay compliant with regulations
By following this guide — from defining clear objectives and curating quality data to deploying models securely and monitoring their lifecycle — developers and enterprises can confidently adopt and scale private LLMs for real-world business impact.

