
How to Build a Private LLM: Best Practices for Secure AI Development
In today’s rapidly evolving AI landscape, organizations are increasingly seeking ways to harness the power of large language models (LLMs) while addressing critical concerns like data privacy and security.
Building your own private LLM offers a compelling solution — enabling you to develop custom solutions tailored to your unique needs, gain control over sensitive information, and avoid potential risks associated with third-party providers.
This comprehensive guide will walk you through the essential steps and considerations for creating a private LLM, from selecting the right architecture to ensuring ethical usage and ongoing monitoring.
Whether you are aiming to generate accurate insights for specific research or automate content creation workflows, understanding how to build a private LLM empowers your organization with more control and valuable insights.
Key Takeaways
Building a private LLM provides complete control over sensitive data and mitigates data privacy concerns by avoiding reliance on third-party providers.
Fine-tuning an existing model using domain-specific data enables the creation of custom solutions that generate accurate and relevant responses tailored to specific tasks.
Implementing strong ethical usage guidelines, continuous monitoring, and expert guidance ensures your private LLM remains secure, compliant, and effective across various industries.
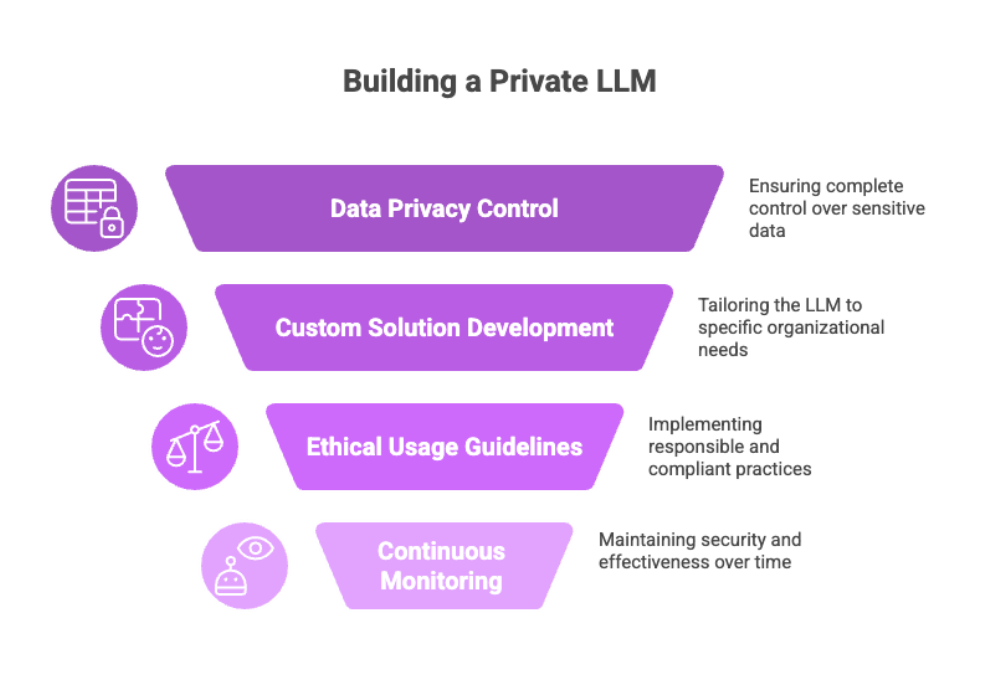

What Is a Private LLM and Why It Matters?
A Private Large Language Model (LLM) is a type of artificial intelligence system that enables organizations to process, analyze, and generate text based on custom data—without relying on external cloud-based solutions. Unlike public LLMs (e.g., ChatGPT or Bard), a private LLM is deployed on a secure infrastructure, giving companies full control over sensitive data, model behavior, and operational governance.
Private LLMs are transforming how enterprises in healthcare, legal, government, and finance manage data privacy, compliance, and task-specific automation. From natural language processing (NLP) to content generation, private LLM development is quickly becoming essential for companies aiming to secure intellectual property while maximizing AI capabilities.
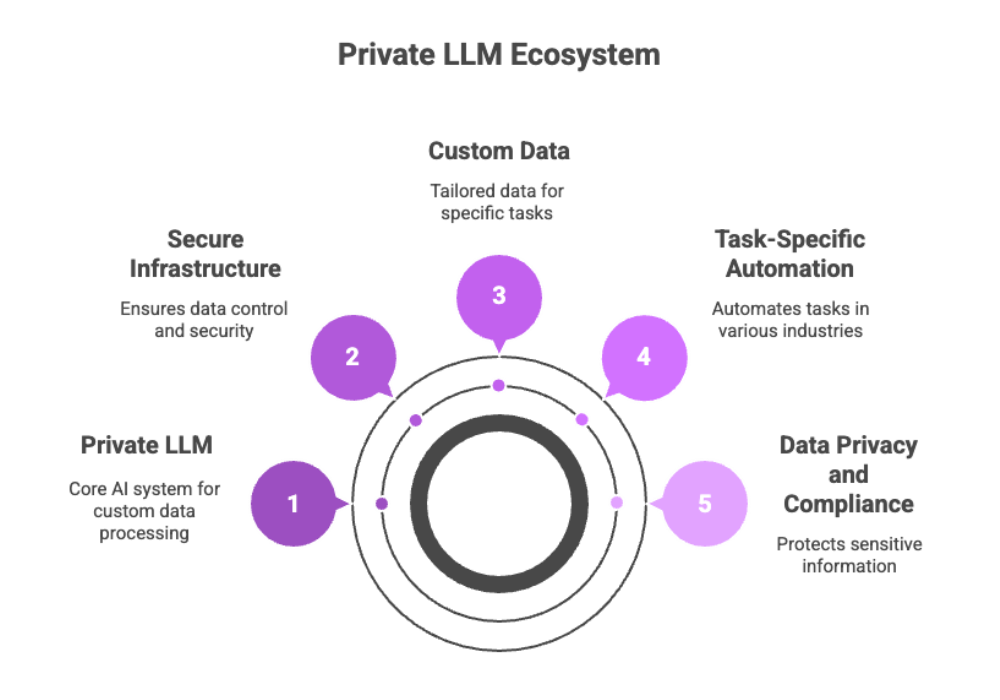
The Strategic Need for Building a Private LLM
Building a private LLM is a strategic move that helps organizations protect sensitive information and gain AI autonomy. This approach addresses concerns around data privacy and reliance on external cloud providers, enabling tailored AI solutions for specific business needs.
The move toward building a private LLM is often driven by two core imperatives:
Protecting sensitive information
Achieving AI model autonomy and accuracy
Common motivators include:
Avoiding risks related to external providers and third-party data access
Ensuring compliance with data privacy regulations (e.g., GDPR, HIPAA, CCPA)
Creating domain-specific AI models that outperform general-purpose LLMs
Achieving full ownership of data pipelines and inference outcomes
Reducing dependency on cloud environments or public API quotas
For example, a law firm dealing with sensitive legal contracts may require an LLM trained on proprietary case law while keeping that data offline and encrypted. A public LLM would be unsuitable for such use cases.
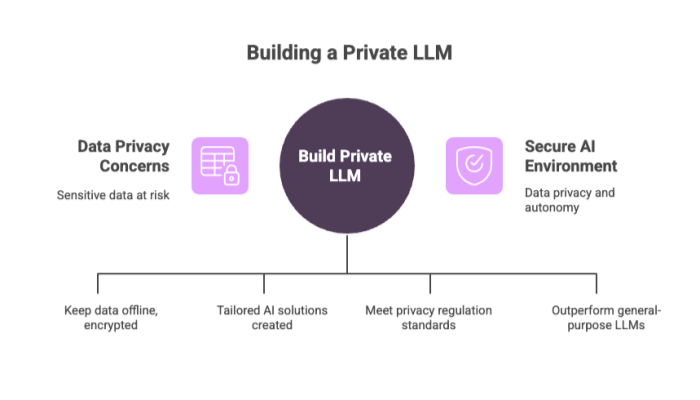
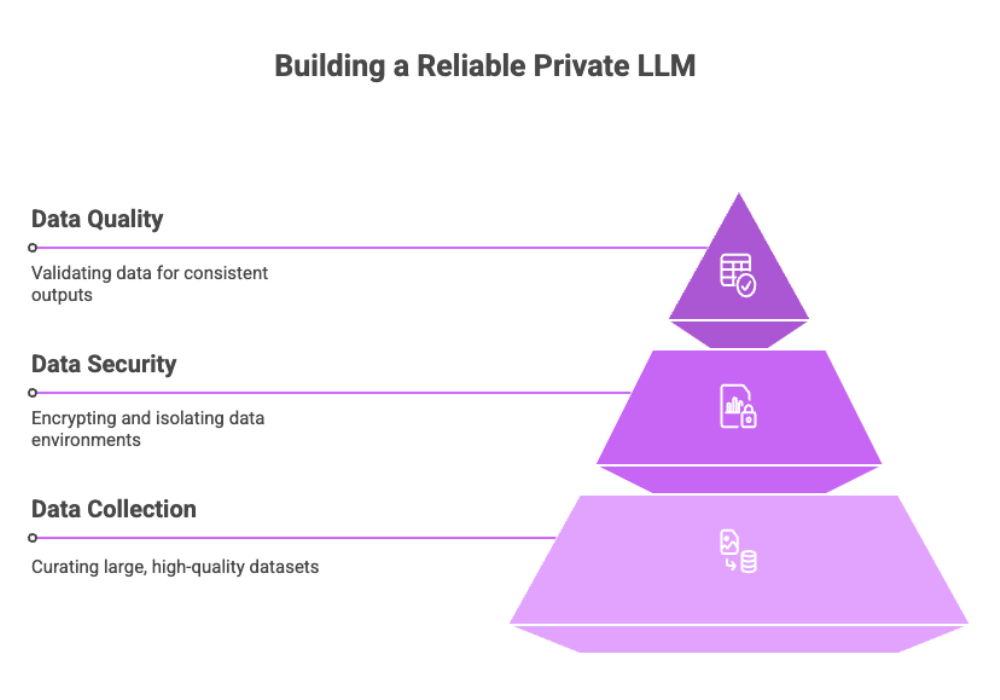
Data Considerations for Private LLM Development
Data is the foundation of any private LLM. Carefully curating, securing, and validating datasets ensures that the model performs reliably and ethically for your specific tasks.
1. Data Collection and Preprocessing
A successful private LLM starts with curating large, high-quality datasets. The training data must be:
Domain-relevant
Well-labeled and structured
Free from noise or bias
This includes internal documents, knowledge bases, support tickets, and domain-specific data like industry reports or technical manuals.
2. Data Security Protocols
To maintain data security, organizations should:
Encrypt datasets during transfer and storage
Use isolated cloud or on-prem environments
Apply data masking for personally identifiable information (PII)
3. Data Quality Metrics
To ensure consistent outputs and LLM performance, validate data using:
Token distribution checks
Vocabulary normalization
Source verification and traceability
This stage is critical to avoid hallucinations or misinformation in generated responses.
Choosing the Right Architecture for Your Private LLM
Selecting the appropriate architecture is a key technical decision that impacts performance, scalability, and resource requirements.
Factors to consider:
Compute availability (e.g., multi-GPU clusters)
Target use cases: classification, summarization, retrieval augmented generation (RAG), etc.
Model size vs latency tolerance
Training from scratch vs fine-tuning a pre-trained model
Common open-source models used:
Meta’s LLaMA 3
Mistral-7B
Falcon LLM
Google Gemma
Fine-tuning a pre-trained model with your domain-specific data often delivers better ROI and faster time to deployment than training from scratch. 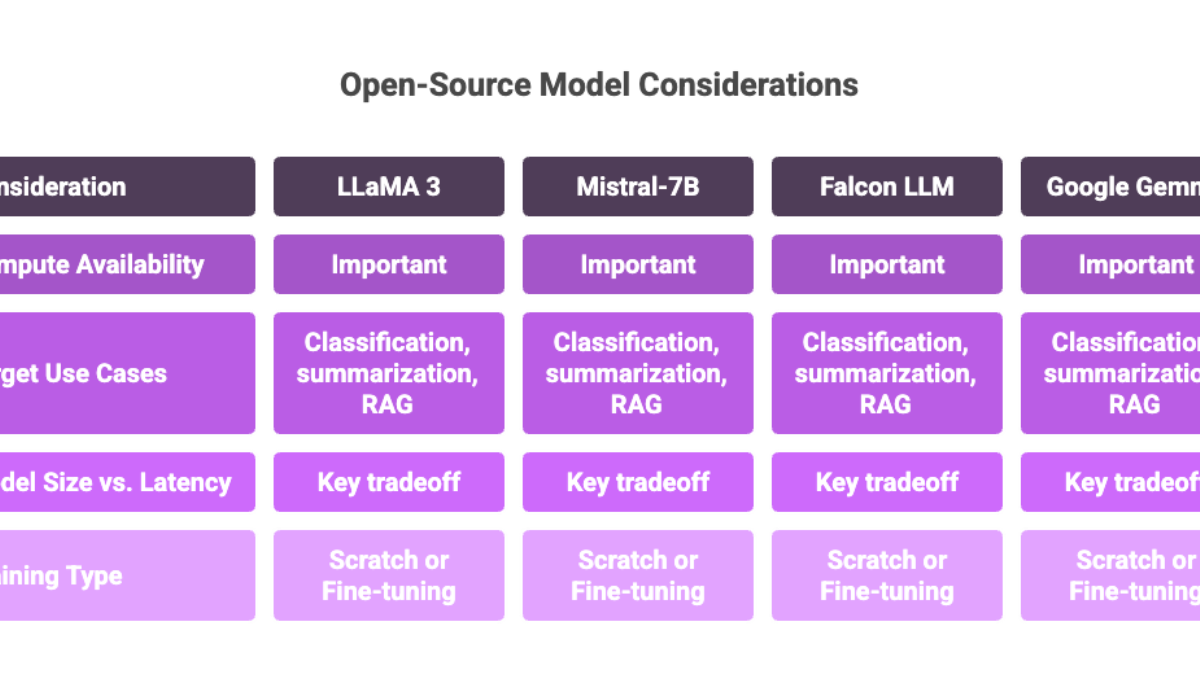
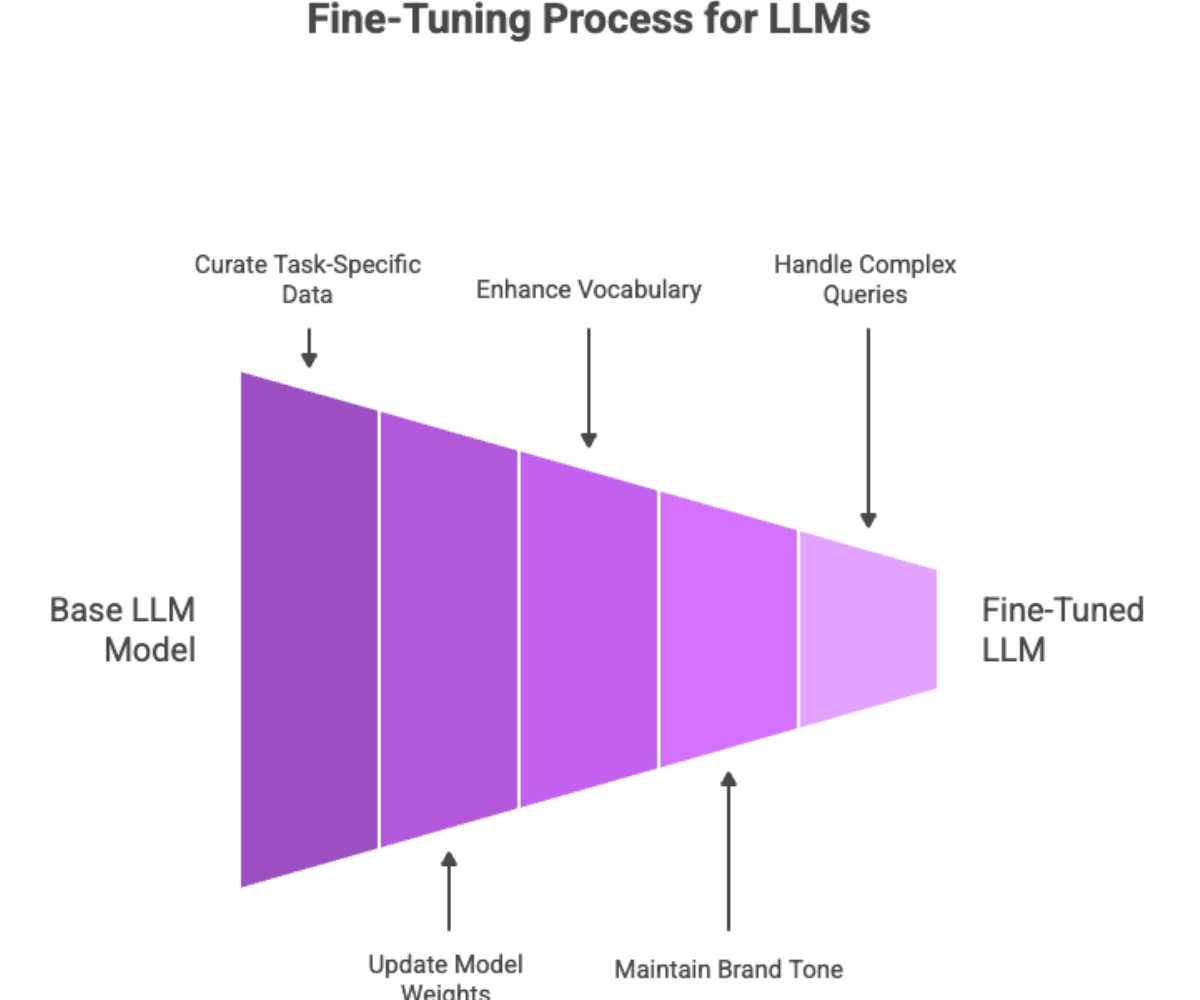
Fine-Tuning and Customization
Fine-tuning allows you to adapt an existing LLM model to your unique requirements by training it on relevant data specific to your domain or tasks. This process improves accuracy and relevance for specific tasks.
What is Fine-Tuning?
Fine-tuning involves updating a base model’s weights using a curated, task-specific dataset. This improves the model’s ability to:
Understand industry-specific vocabulary
Maintain brand tone or compliance rules
Handle complex queries or workflows
You can also experiment with instruction-tuning (training the model to follow structured commands) or adapter layers to modularize domain adaptations.
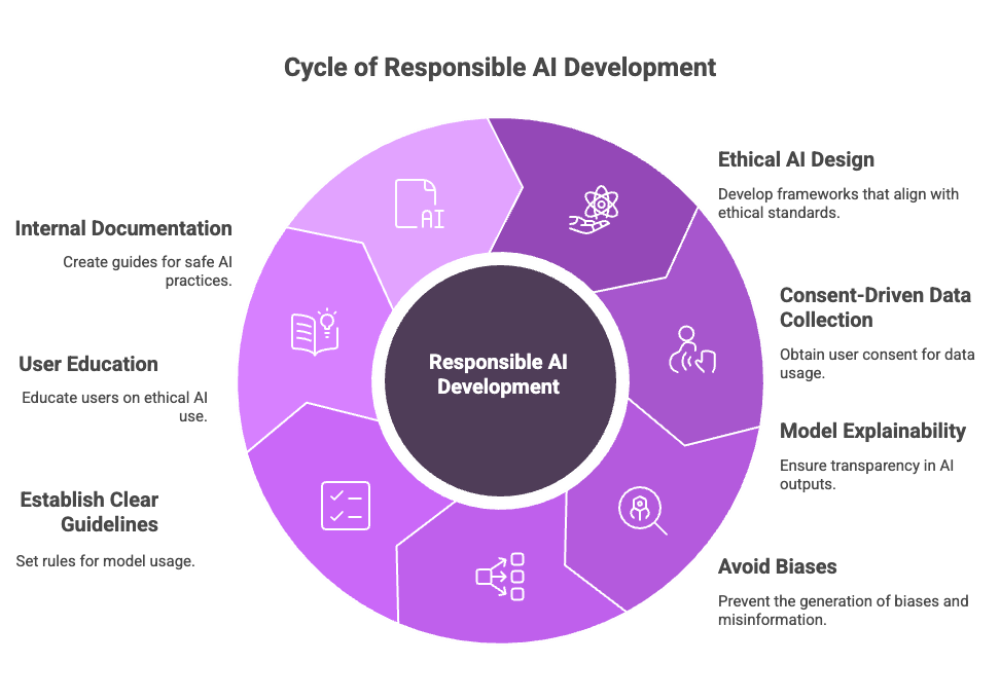
Ethical and Legal Considerations
Responsible AI development requires adherence to ethical guidelines and legal frameworks to ensure the safe and fair use of private LLMs.
Ensure Responsible Use Through:
Ethical AI design frameworks
Consent-driven data collection
Model explainability (transparency in how outputs are generated)
Avoiding generation of biases, toxic language, or misinformation
Establish clear guidelines for model usage. Incorporate user education and internal documentation to guide safe, ethical use of the private LLM.
Deployment Options: On-Prem vs Cloud
Choosing between on-premise and cloud deployments depends on your organization's priorities regarding data privacy, scalability, and infrastructure capabilities.
On-Premise Deployment
Pros:
Highest level of data privacy and control
Best for highly regulated industries
Local compute avoids internet exposure
Cons:
High infrastructure cost
Requires in-house technical expertise
Private Cloud Deployment
Pros:
Scalable and flexible
Access to high-performance GPUs
Easier to maintain and monitor
Cons:
May involve minimal exposure to cloud environments
Requires robust access control and encryption
Tools like Docker, Kubernetes, and MLflow can help orchestrate deployments efficiently.
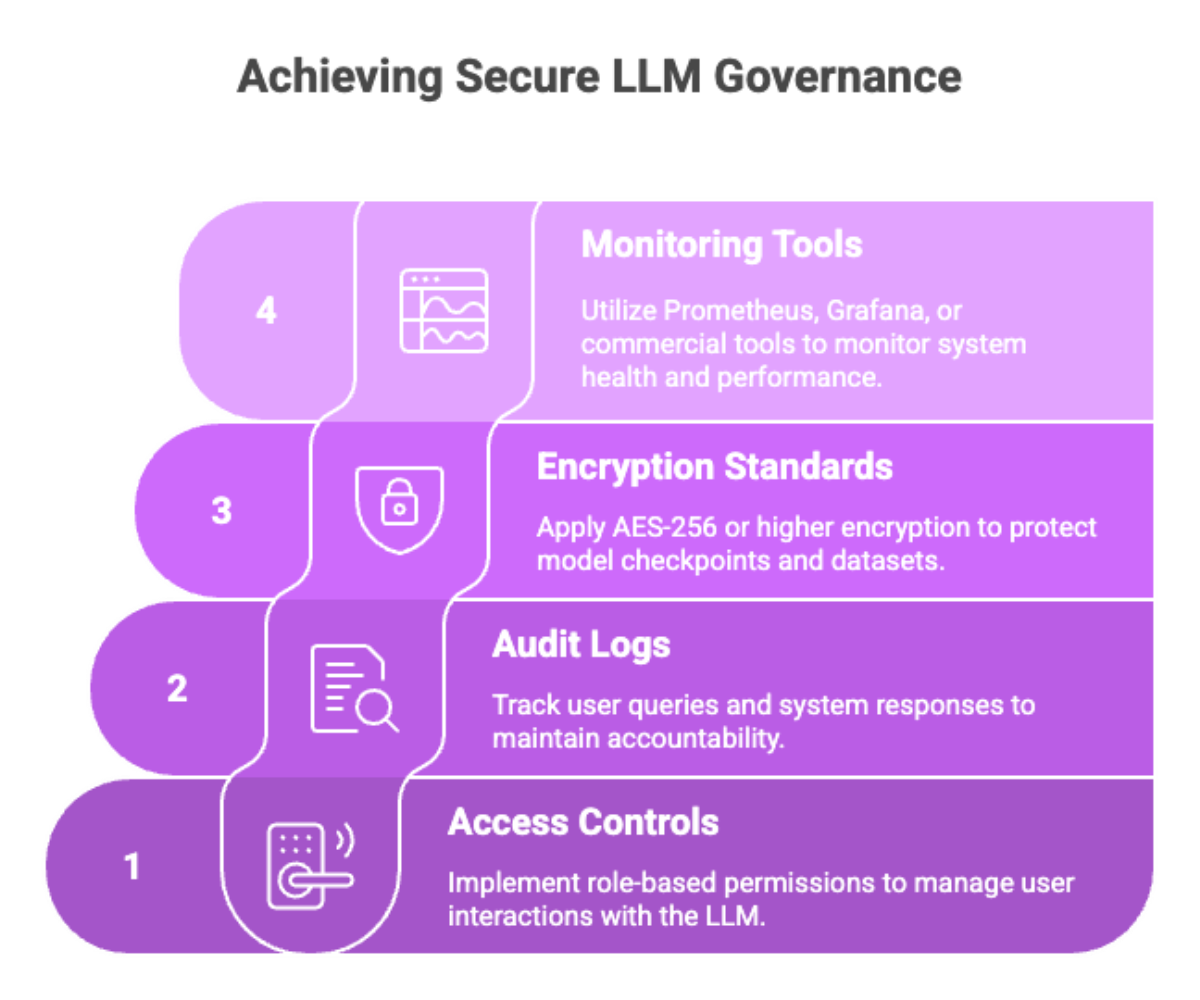
Security and Governance Frameworks
Implementing a strong governance framework ensures your private LLM operates securely and ethically over time.
Key security components include:
Access controls: Role-based permissions for model interaction
Audit logs: Track user queries and system responses
Encryption standards: AES-256 or higher for model checkpoints and datasets
Monitoring tools: Use Prometheus, Grafana, or commercial tools for system health and performance tracking
These practices ensure that your private LLM system remains compliant, ethical, and operational at scale.
Expert Support and Infrastructure Management
Partnering with experts can accelerate your private LLM development and ensure best practices in data handling, model training, and deployment.
Why Partnering with Experts Matters?
Data scientists help with data preprocessing and annotation
Machine learning engineers handle model design and tuning
MLOps specialists manage deployment pipelines and CI/CD systems
Consider external consulting partners for initial bootstrapping and use internal teams for long-term governance and iteration.
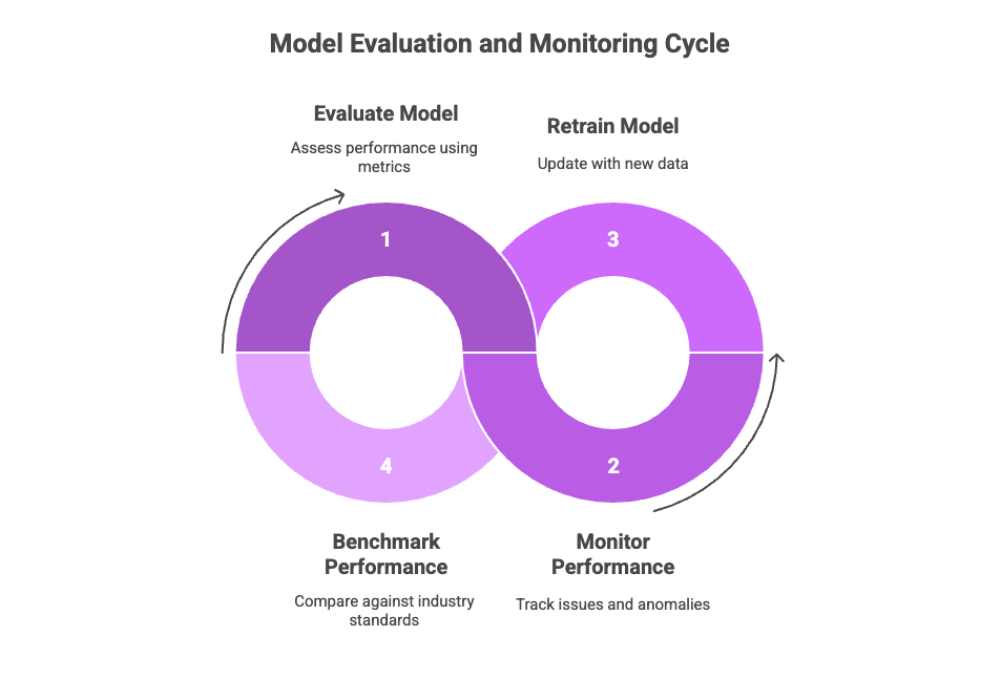
Evaluation, Benchmarking, and Monitoring
Continuous evaluation and monitoring are essential to maintain model accuracy and relevance.
Evaluation Metrics:
BLEU / ROUGE: Text similarity for summarization
Exact Match & F1: For QA tasks
Perplexity: Language modeling fluency
Model Monitoring:
Use logging to capture failed queries, slow responses, or hallucinated content
Periodically retrain on new data to reduce model drift
Benchmark performance against public LLMs to demonstrate ROI
Deploy automated retraining pipelines that incorporate feedback loops for continuous improvement.
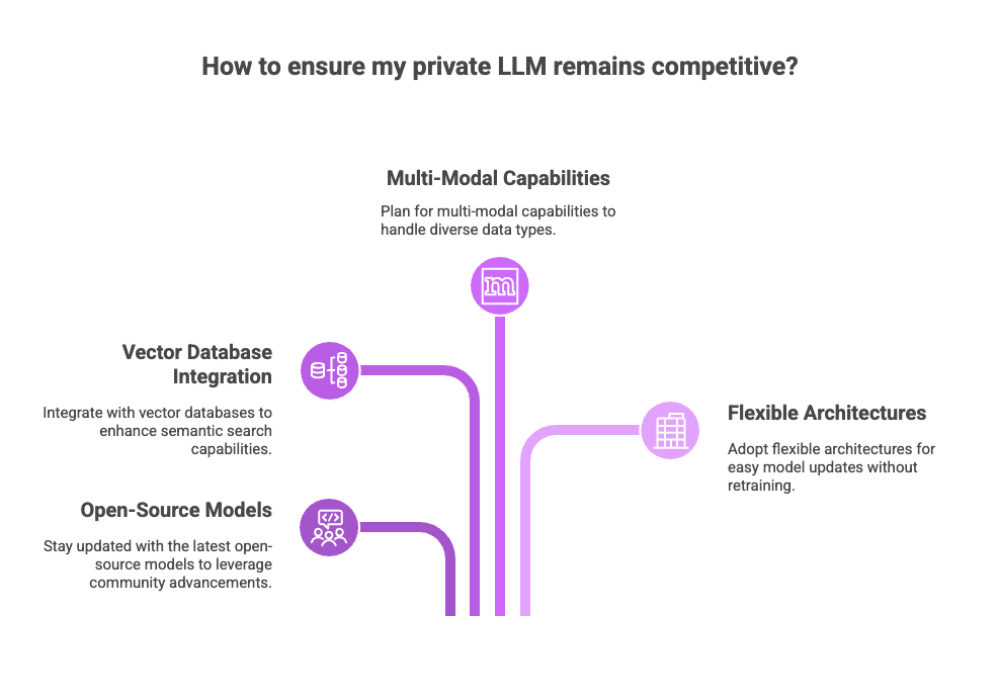
Future-Proofing Your Private LLM
The AI landscape evolves rapidly, and your private LLM should be adaptable to new developments and capabilities.
To stay competitive:
Follow the latest in open-source model development
Explore integrations with vector databases for semantic search
Plan for multi-modal capabilities (text + image + code)
Adopt flexible architectures that can be updated or swapped with newer state-of-the-art models without retraining from scratch.
Final Thoughts: Unlocking the Power of Private LLMs
Developing a private large language model is a strategic investment that gives your organization:
Full control over sensitive data
Ability to train on relevant documents and knowledge bases
A custom AI engine that reflects your brand, tone, and logic
Competitive advantage through proprietary AI capabilities
By following these best practices for architecture selection, ethical design, data handling, and deployment, businesses can safely unlock the power of secure, private LLMs.
As demand for data privacy grows, organizations that own and govern their own models will be best positioned to innovate and lead in their industries.

