
How to Use LLM with Private Data: A Practical Guide
Large Language Models (LLMs) are revolutionizing industries such as finance, healthcare, legal services, and e-commerce, by enabling powerful generative AI capabilities. However, as LLMs become more integrated into critical workflows, the challenge of handling private data securely has taken center stage.
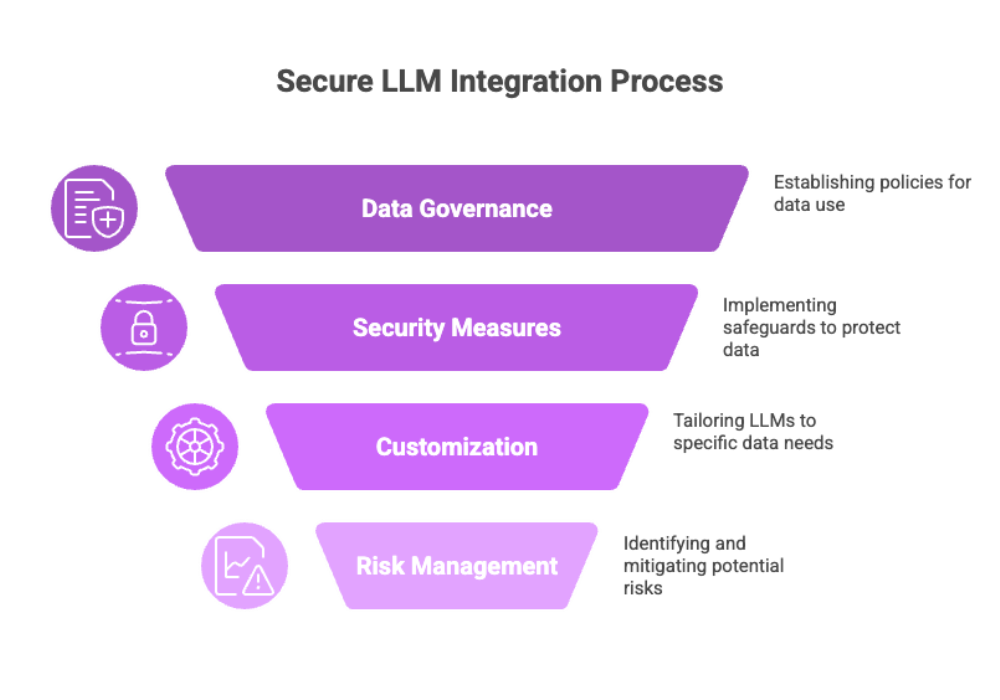
Whether it’s personally identifiable information (PII) or protected health information (PHI), working with sensitive data requires organizations to adopt rigorous practices in data governance, security, and customization. Training or fine-tuning LLMs on proprietary data can enhance accuracy and domain relevance—but also introduces risks such as data exposure, regulatory non-compliance, and model drift.
This guide explores the strategic, technical, and operational aspects of how to use LLMs with private data, ensuring that businesses can leverage the power of AI without compromising on data security or user privacy. By utilizing a private LLM, organizations can train or supplement the model with proprietary information to provide more accurate and relevant responses, while maintaining confidentiality and security.

The Importance of Data Preparation and Protection
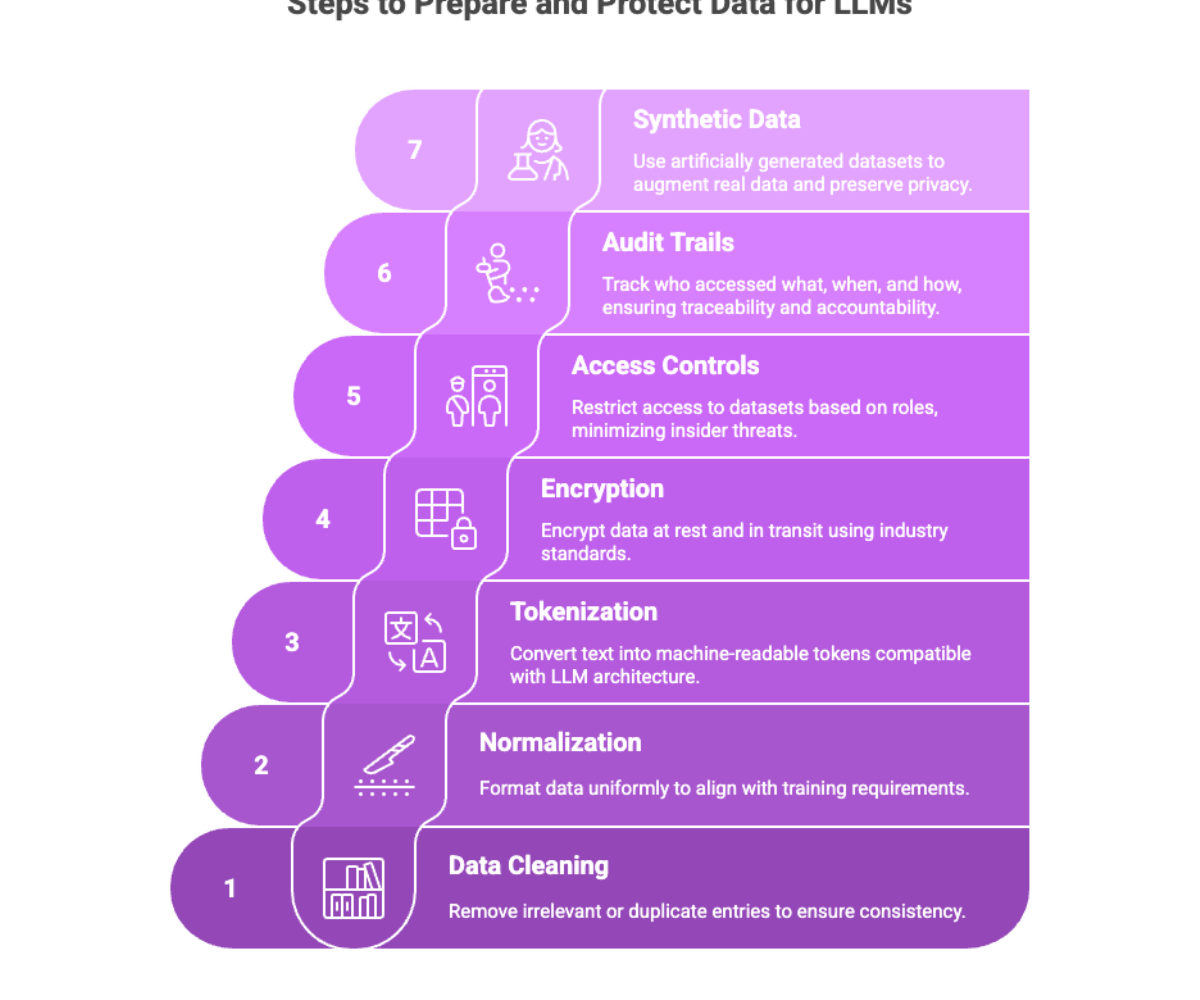
Before feeding any information into a large language model, organizations must undertake robust data preparation and protection procedures. Ensuring high data quality through validation, governance, and cleaning processes is essential for effective model performance and reducing risks.
Key Data Preparation Steps:
Data cleaning: Remove irrelevant or duplicate entries to ensure consistency. Only properly processed data should be used for training to maintain reliability.
Normalization: Format data uniformly to align with training requirements.
Tokenization: Convert text into machine-readable tokens compatible with LLM architecture.
Data Protection Essentials:
Encryption: All data at rest and in transit must be encrypted using industry standards like AES-256. Encrypted data must also be securely stored to prevent unauthorized access or breaches.
Access controls: Restrict access to datasets based on roles, minimizing insider threats.
Audit trails: Track who accessed what, when, and how, ensuring traceability and accountability.
Leveraging Synthetic Data
Synthetic data—artificially generated datasets—can be used to augment real data. This helps:
Preserve data privacy
Improve model generalizability
Reduce reliance on real-world sensitive data
Synthetic datasets are particularly useful in training LLMs on scenarios where real data is scarce, sensitive, or regulated. Introducing statistical noise during synthetic data generation can help preserve privacy while maintaining data utility.
Fine-Tuning for Domain-Specific Customization
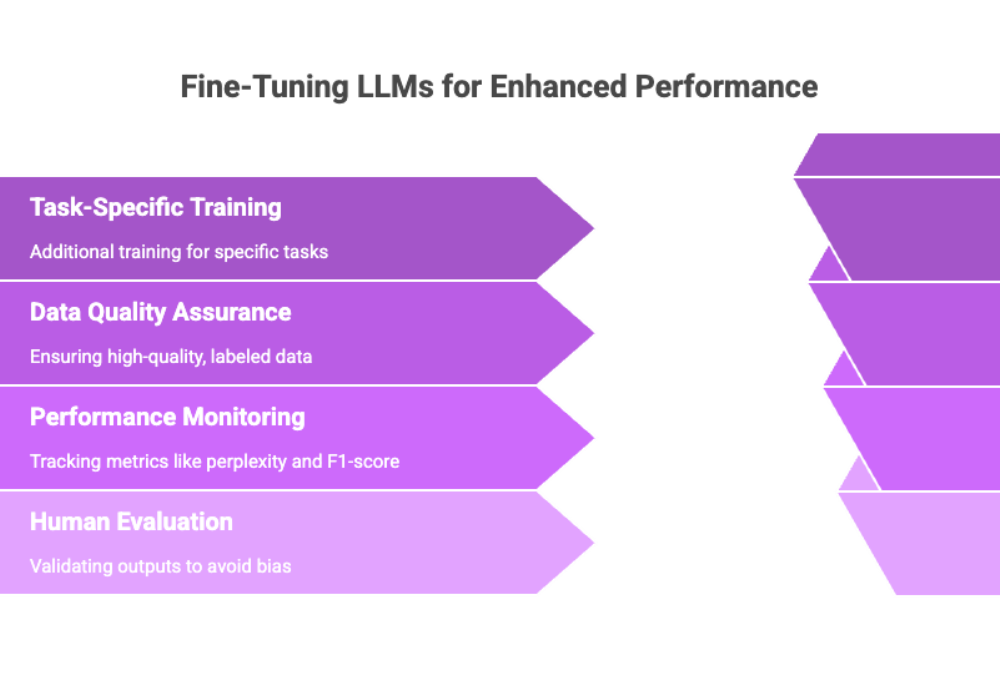
Fine-tuning an LLM involves adapting a pre-trained model to a specific task or dataset, thereby enhancing performance on proprietary use cases. The model can be fine tuned for specific tasks, which means additional training steps are applied after initial pre-training to improve performance and relevance for targeted applications.
Why Fine-Tune LLMs?
Achieve domain-specific fluency
Customize tone, intent, or logic for internal workflows
Improve response consistency in high-stakes environments
Enable LLMs to perform specific tasks more effectively by tailoring them to particular objectives or specialized applications
Best Practices for Fine-Tuning:
Use high-quality, labeled training data
Monitor training loss and evaluation metrics like perplexity and F1-score
Define clear evaluation criteria to assess the performance and suitability of the fine-tuned model
Validate outputs using human evaluation to avoid bias or hallucinations
Low-Rank Adaptation (LoRA)
LoRA is a fine-tuning optimization technique that introduces fewer trainable parameters, reducing computational demands. It enables efficient customization without sacrificing model quality—a perfect option for organizations with limited GPU resources.
How to Safely Work with Your Own Data?
When training an LLM on your organization’s own data, there are several critical considerations. Curating a high-quality data set is essential to effectively test and demonstrate the LLM's capabilities, ensuring it can accurately interpret and retrieve information from your structured data.
Data Handling Requirements:
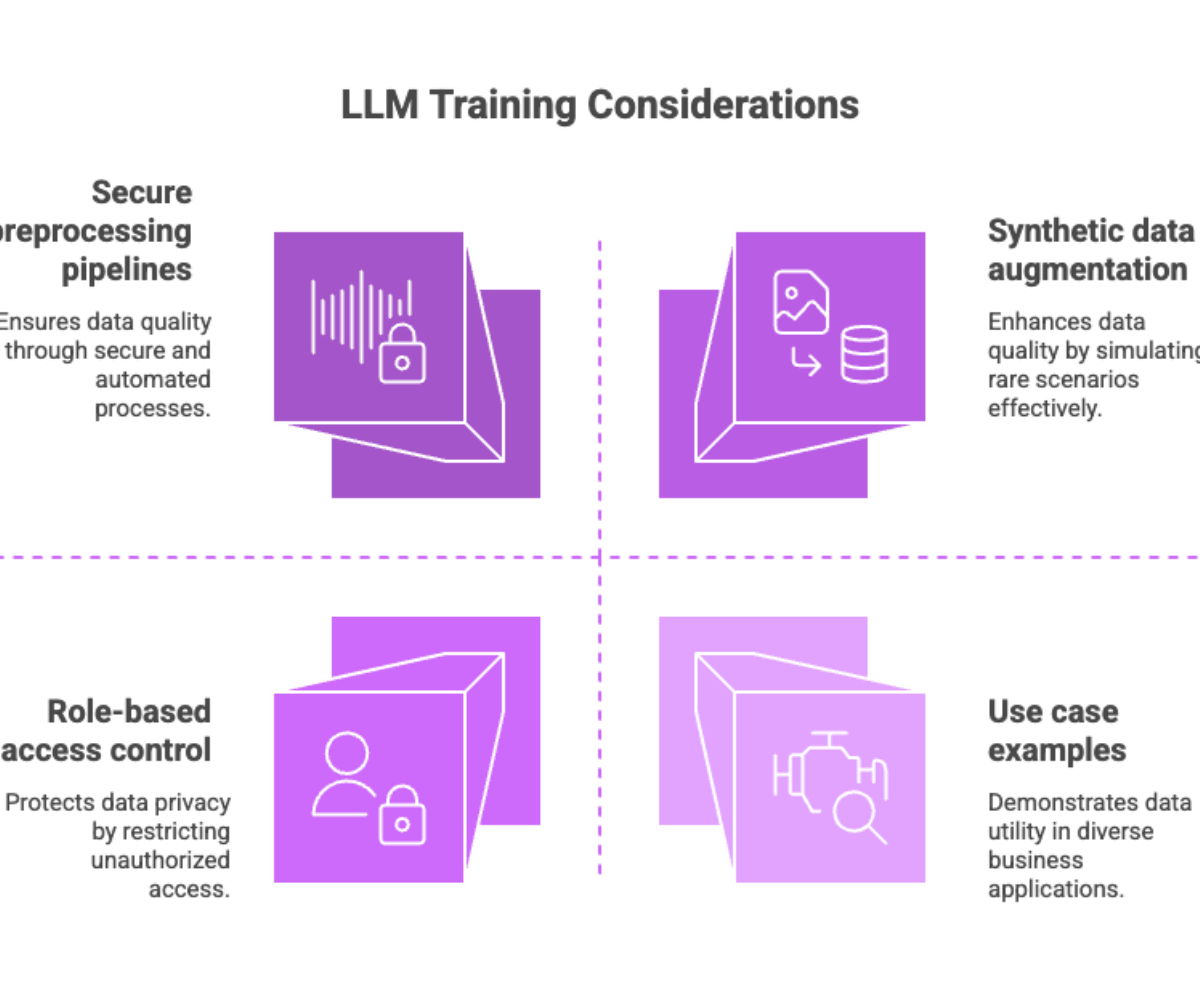
Secure preprocessing pipelines: Automate cleaning and tokenization while maintaining encryption
Role-based access control (RBAC): Prevent unauthorized team members from accessing datasets
Data categorization: Separate public, confidential, and restricted data layers
Augmenting with Synthetic Data
Use synthetic data to balance datasets, test edge cases, or simulate rare but impactful business scenarios. This also helps mitigate privacy concerns while ensuring robust model training.
Use Case Examples:
Law firms analyzing case documents
Retailers optimizing product descriptions
Healthcare providers generating compliant patient summaries
An instance where a private LLM was used to identify and resolve data inconsistencies in financial records, helping a business address compliance challenges
Implementing Access Controls and Data Governance
Effective access controls and data governance are fundamental to securely managing private data when working with large language models. This section introduces key strategies and frameworks that organizations can adopt to protect sensitive information, ensure compliance with regulatory requirements, and maintain accountability throughout the data lifecycle.
Key Components:
Multi-factor authentication (MFA) for admin access
Attribute-based access controls (ABAC) for granular policy enforcement
Continuous monitoring to detect anomalies and respond to threats in real-time
Regulatory Compliance Frameworks:
Ensure alignment with:
GDPR (EU)
CCPA (California)
ISO 27001 (global standard for information security)
A robust data governance framework not only protects against breaches, but also enhances transparency and regulatory readiness.
Managing Machine Learning and AI Workloads
Training LLMs on private data demands advanced infrastructure and skilled personnel. Databases play a crucial role in these environments by storing embeddings, supporting vector search, and enabling efficient retrieval for AI workloads.
Infrastructure Considerations:
High-performance GPUs
Cloud instances with auto-scaling capabilities
Container orchestration using Kubernetes or Docker
Choosing the right database technology (such as traditional databases, vector databases, or data warehouses) is crucial for efficiently managing, storing, and querying data during LLM training
Operational Best Practices:
Schedule model checkpoints to prevent data loss
Use ML pipelines (e.g., Kubeflow, MLflow) to automate versioning and rollback
Align AI workloads with business goals and cost-efficiency
Leveraging automation and optimized workflows can significantly reduce operational challenges and costs.
This ensures that training LLMs remains productive and scalable across departments.
Streamlining LLM Training Pipelines
Large language models have transformed how organizations approach natural language processing, but training these models on private data introduces unique challenges. To maximize efficiency and maintain compliance with regulatory requirements, it’s essential to streamline LLM training pipelines with a focus on automation, workflow optimization, and robust monitoring.
Automation and Workflow Optimization
Automating your LLM training pipeline is a game-changer for both productivity and data security. By integrating open-source tools and frameworks, organizations can design end-to-end workflows that handle everything from data ingestion to model evaluation with minimal manual intervention. For example, leveraging low-rank adaptation (LoRA) allows teams to fine-tune pre-trained models on proprietary data while significantly reducing computational resource requirements. This not only accelerates the training process but also makes it more cost-effective.
Implementing strong access controls and maintaining detailed audit trails throughout the pipeline are essential for protecting sensitive information and mitigating insider threats. These measures ensure that only authorized personnel can access proprietary data during the fine-tuning process, and every action is logged for accountability. By combining automation with these security best practices, organizations can create efficient, secure, and scalable LLM training workflows.
Monitoring and Maintenance
Continuous monitoring and proactive maintenance are vital for sustaining high performance and minimizing potential risks in LLM training. Real-time monitoring systems enable organizations to track key metrics, quickly identify data exposure incidents, and respond to security threats as they arise. Regularly updating model weights and retraining on fresh data helps prevent model drift, ensuring that outputs remain accurate and relevant.
Incorporating techniques like prompt engineering and synthetic data generation can further enhance model performance and reduce the risk of overfitting to the original training data. These strategies allow organizations to adapt to evolving data sources and business needs while maintaining a strong security posture. Ultimately, a well-monitored and maintained LLM training pipeline is essential for delivering reliable, compliant, and high-performing AI solutions.
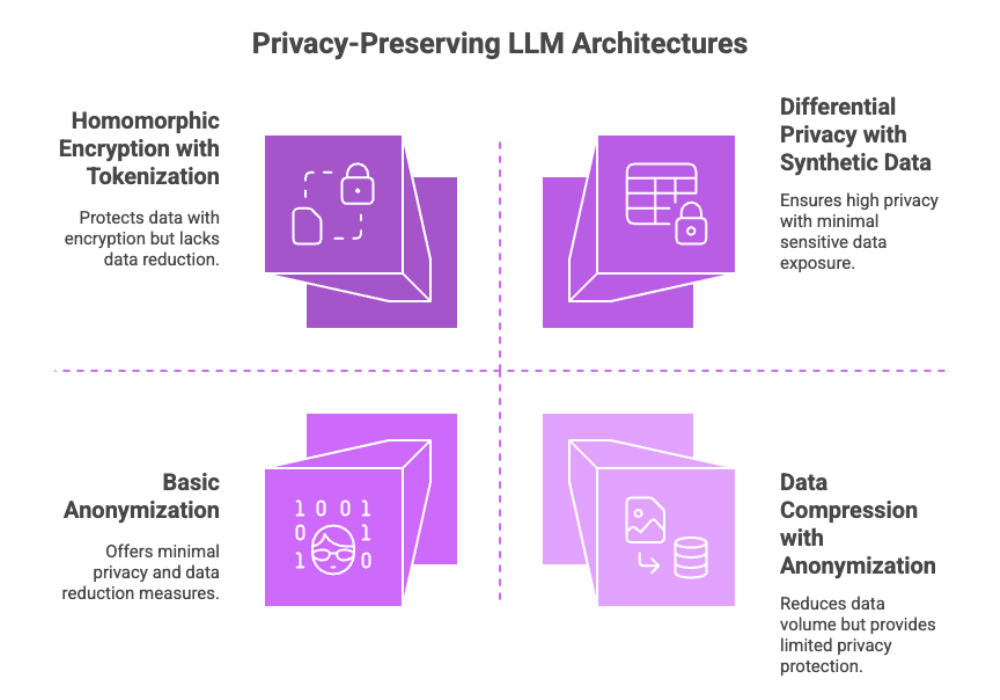
Privacy-Preserving Architectures
As organizations increasingly train LLMs on private data, adopting privacy-preserving architectures becomes critical for safeguarding sensitive information and maintaining user privacy. By leveraging advanced techniques such as differential privacy, homomorphic encryption, and secure multi-party computation, organizations can ensure that their models are trained on sensitive data without exposing confidential details or violating regulatory requirements.
These privacy-preserving methods are designed to protect sensitive information throughout the LLM training process, allowing organizations to harness the power of AI while upholding the highest standards of data security and compliance. Implementing such architectures is not just a technical necessity—it’s a strategic imperative for any organization handling sensitive or regulated data.
Techniques for Data Minimization
Data minimization is a cornerstone of privacy-preserving LLM architectures. By reducing the volume and sensitivity of data used in training, organizations can significantly lower the risk of data exposure and potential breaches. Techniques such as data compression, tokenization, and anonymization help strip away personally identifiable or sensitive information, making the data safer for use in machine learning workflows.
Synthetic data generation and data augmentation are also powerful tools for minimizing risk. By creating artificial datasets that mirror the structure and characteristics of the original data—without containing actual sensitive information—organizations can train effective models while protecting privacy. These approaches not only help mitigate potential risks but also support compliance with regulatory requirements and industry best practices.
By prioritizing data minimization and privacy-preserving techniques, organizations can create robust, secure LLM training environments that protect sensitive information and maintain trust with users and stakeholders.
Open Source LLMs: Flexibility with Responsibility
Open-source LLMs provide customizable, cost-effective alternatives to commercial APIs. In contrast, public LLMs offer accessible, cloud-managed solutions for AI workloads, making it easier to persist, manage, and query model input data and vector embeddings, while also providing native vector database support for long-term storage and semantic search.
Benefits:
Full access to model weights and architecture
No vendor lock-in
Flexible for on-premise deployments
Leading Open-Source Models:
LLaMA by Meta
Mistral-7B
Falcon
Gemma by Google
There are also many other models available for benchmarking and comparison, including both private LLMs and well-known public options like Anthropic's Claude and Meta's Llama.
Customization Tips:
Apply prompt engineering techniques for better model alignment
Use vector embeddings for contextual document retrieval; embedding data into the model's context enables more accurate retrieval and improves response quality
Experiment with retrieval augmented generation (RAG) to enhance accuracy
Note: Always validate that your usage of open-source models complies with licensing terms and security protocols.
Evaluating LLM Performance Effectively
Reliable evaluation is essential for continuous improvement. Evaluating model outputs is crucial to ensure the accuracy and relevance of language model responses.
Core Metrics:
Perplexity: Measures fluency and prediction capability
Accuracy / F1-score: For classification or QA tasks
BLEU / ROUGE: For translation and summarization
Human Evaluation: Contextual correctness and bias detection
Use tools like Eval Harness, OpenLLM, or proprietary dashboards to automate performance monitoring.
Evaluation Strategy:
Test across multiple data slices (i.e., demographics, query types)
Monitor for model drift
Perform A/B testing against existing models; comparing your results to an existing model helps assess improvements and determine if your solution is more suitable for your needs.
Addressing Common Challenges with LLMs and Private Data
Working with large language models on private data presents unique challenges that organizations must navigate carefully. These challenges range from safeguarding sensitive information to managing the technical complexities of training and maintaining high-performing models. Understanding these issues and their solutions is essential for harnessing the full potential of LLMs while maintaining data security and compliance.
Key Issues:
Data Exposure: Unauthorized access to sensitive datasets
Model Drift: Performance degradation over time
High Resource Requirements: Costly training cycles
Solutions:
Implement encryption and access controls
Use low-rank adaptation and transfer learning
Select the right method for data handling and model training to ensure security, accuracy, and alignment with organizational needs
Continuously evaluate with audit trails and model diagnostics
Regular model evaluation and dataset updates are critical for long-term sustainability.

Final Thoughts: Using LLMs Securely with Private Data
Leveraging LLMs with private data opens up powerful opportunities—but only when approached with a focus on data governance, model evaluation, and infrastructure optimization.
To recap:
Start with clean, well-labeled, and secure training data
Use fine-tuning or LoRA to customize pre-trained models
Implement access controls, audit trails, and encryption
Evaluate and monitor LLMs regularly
Align everything with regulatory and ethical standards
Staying informed about recent developments in LLM training and privacy techniques is crucial for maintaining best practices.
By following these practices, organizations can master the balance between LLM performance and data privacy, turning AI into a trusted partner in business transformation.

