
Local LLM Models: Guide to Effective Setup and Use
Local LLMs (Large Language Models) provide a groundbreaking way to deploy powerful AI models directly on your own computer, eliminating dependency on cloud services. These models are revolutionizing industries where sensitive data protection, cost efficiency, and low-latency performance are vital.
By running LLMs locally, you not only reduce recurring subscription fees from cloud providers but also maintain full control over data, model behavior, and performance. From healthcare to legal and financial services, local deployment offers unmatched security and adaptability.
Moreover, experimenting with local LLM models enables individuals and developers to deepen their understanding of machine learning and AI applications in a practical, self-contained environment.
Key Takeaways
Running local LLM models offers significant cost savings by eliminating the need for ongoing subscription fees and reliance on a third party provider.
Popular local LLM tools like Ollama, LM Studio, and GPT4All provide user-friendly interfaces and support a wide range of popular models and model formats for personal use and enterprise applications.
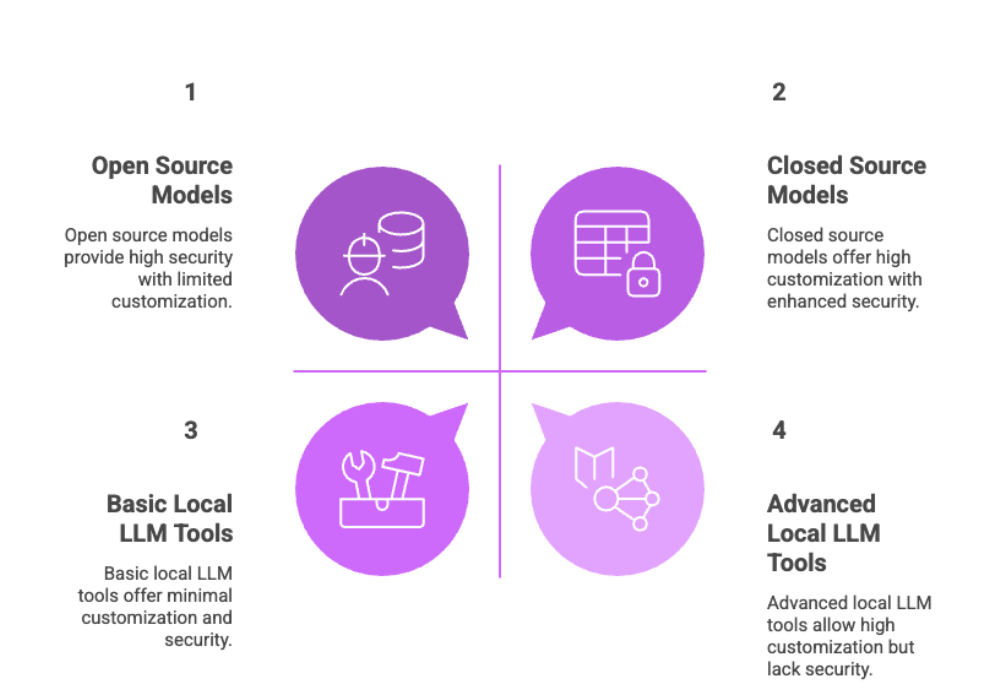
While open source models dominate the local LLM landscape, some users may prefer closed source models for specific use cases; choosing the right tool depends on your hardware, desired key features, and level of customization required.

Benefits of Running LLMs Locally
The rise of local LLM tools has made it increasingly accessible to run LLMs locally with minimal setup. Here's why many developers and businesses are moving away from cloud-based LLMs.
Key Advantages:
Full Data Control: All processing stays on the local machine, protecting sensitive information from exposure to third-party providers.
No Subscription Fees: Eliminate the cost of continuous API access with cloud-based AI models.
Offline Functionality: Run powerful AI models without relying on an internet connection.
Enhanced Customization: Fine-tune models to suit your tasks, whether it's customer service, content generation, or internal document analysis.
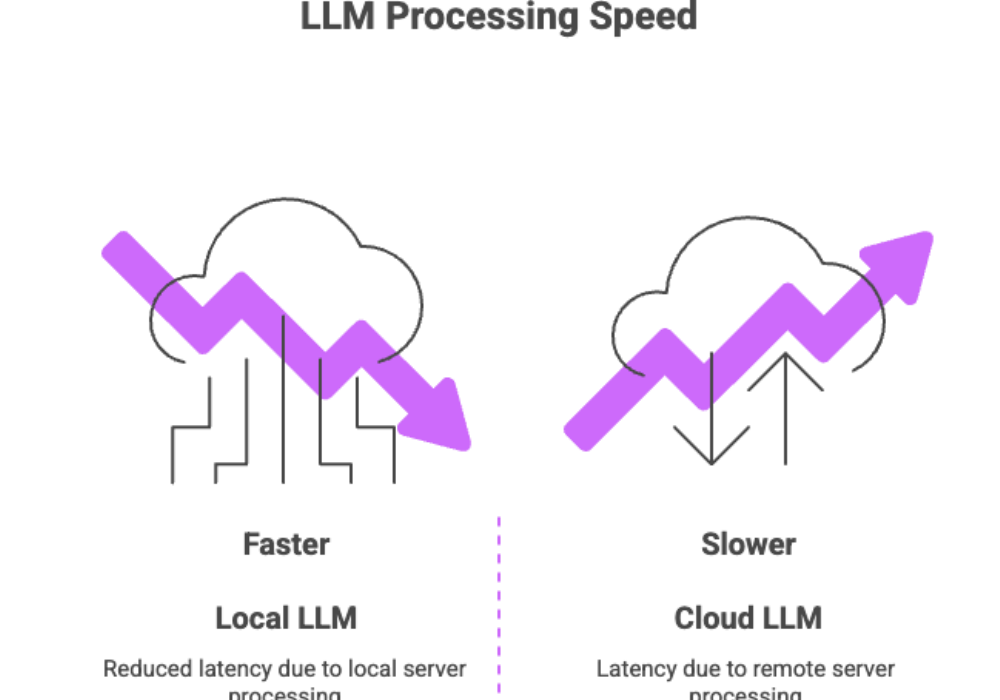
Faster Performance: Reduced latency due to local server processing, especially valuable in time-sensitive applications.
As consumer hardware continues to improve, the barrier to entry for running LLMs locally continues to lower.
Choosing the Best Local LLM Model
Selecting the best models for your environment hinges on two critical factors: your task-specific needs and your hardware capacity.
Factors to Consider:
Model Size & Type: Choose between smaller models for lightweight tasks and larger models for complex reasoning.
Hardware Resources: Ensure your system (especially GPU and RAM) can support the model’s requirements.
Use Case Alignment: Some models are better at code generation, others at logical reasoning or summarization.
Popular Options for 2025:
LLaMA: A high-performance open source LLM suitable for research and production.
Mistral: Known for strong reasoning and low memory requirements.
Phi-3: Ideal for applications with limited hardware.
Qwen: A multilingual model with broad capabilities.
All of these models are available in downloadable model formats like .gguf or .bin, which are widely supported by top local LLM tools.

Setting Up Local LLMs
Setting up local LLMs involves selecting the right models and tools tailored to your hardware and use case. Whether you're a developer seeking fine-tuning capabilities or a casual user wanting a straightforward way to run local LLMs, the process has become more accessible than ever. This section will guide you through the essential steps to get your local LLM models up and running efficiently.
Step-by-Step Setup
To get started with local deployment, follow these core steps:
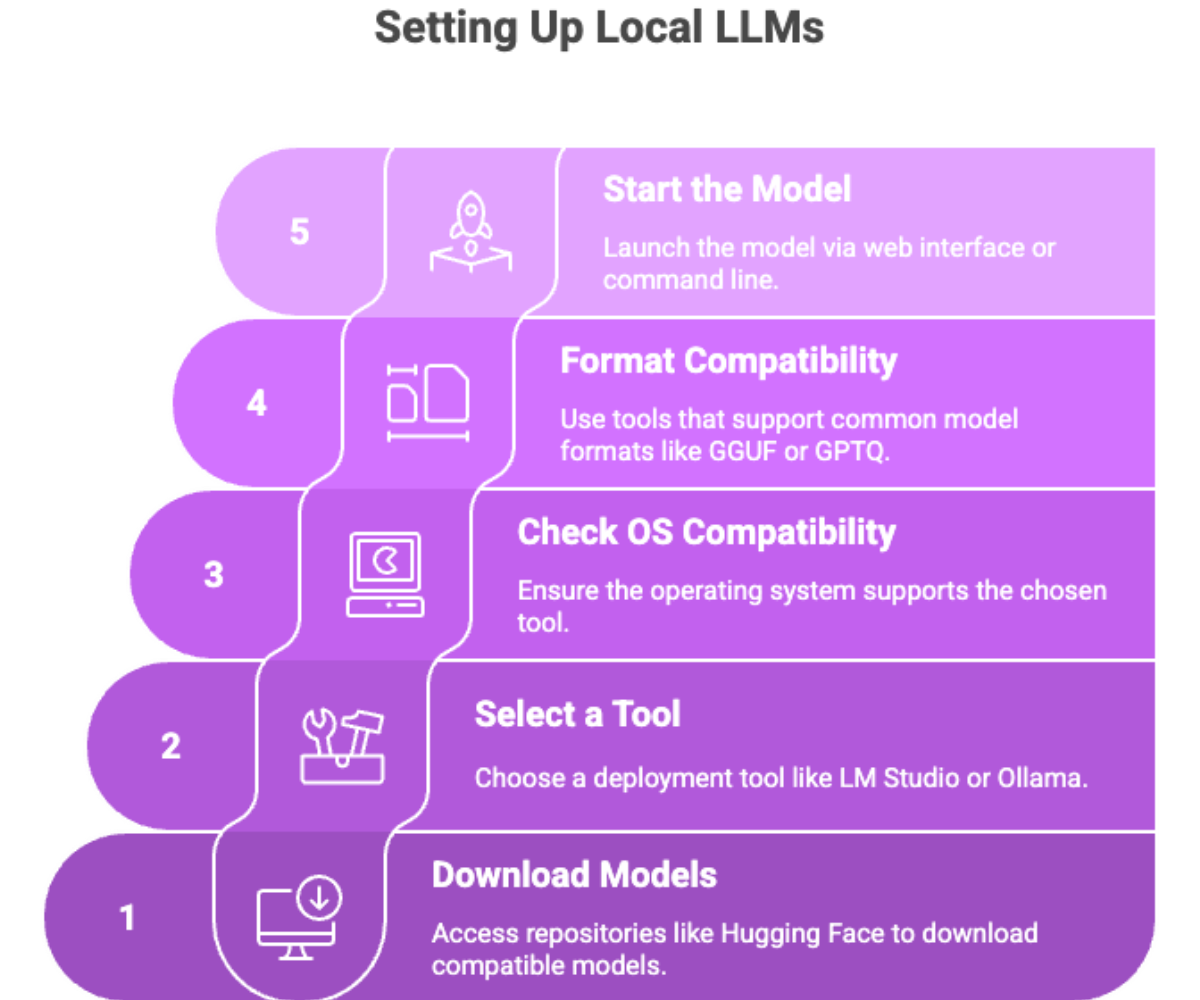
Download Models: Access repositories like Hugging Face to download models compatible with your setup.
Select a Tool: Use LM Studio or Ollama for easy deployment.
Check OS Compatibility: Ensure the operating system supports the chosen tool (e.g., MacOS with Apple Silicon, Windows, or Linux).
Format Compatibility: Use tools that support common model formats like GGUF or GPTQ.
Start the Model: Launch via web interface or command line and begin processing.
Even for users with limited technical expertise, tools like LM Studio offer an intuitive GUI and easy installation, requiring nothing more than a single executable file in many cases.
Fine-Tuning Local LLMs
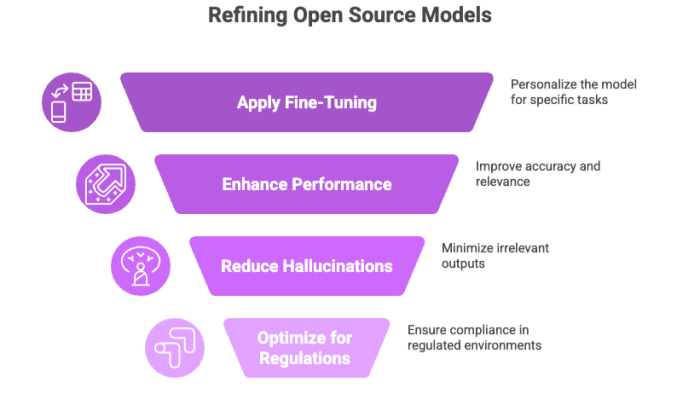
Fine tuning allows you to personalize open source models for specific applications or industries, improving their relevance and accuracy.
Why Fine-Tuning Matters
Boosts performance on niche tasks or datasets
Reduces model hallucination or irrelevant outputs
Enhances performance in regulated environments (e.g., legal summaries, medical documents)
Fine-Tuning Methods:
LoRA (Low-Rank Adaptation): Lightweight method to inject task-specific knowledge.
Instruction Tuning: Reframes model responses using curated prompts and data.
Supervised Fine-Tuning: Train on labeled datasets for maximum precision.
By adjusting model parameters, developers can transform a general base model into a specialized local model without needing massive computational resources.
Running LLMs on Specific Hardware
Choosing the right hardware is crucial for maximizing the performance and efficiency of your local LLM models. This section explores the hardware requirements and compatibility considerations to help you run LLMs smoothly on your machine.
Apple Silicon, GPUs, and Consumer Machines
Thanks to optimized software and open source LLMs, even mid-range consumer hardware can run LLMs locally effectively.
Hardware Requirements:
Video RAM: At least 8–16GB for medium models; more for larger models
RAM: 16GB+ recommended
Storage: SSDs preferred for model files (which may range from 2GB to 30GB+)
CPU/GPU: Apple Silicon, NVIDIA GPUs, and integrated graphics supported by most tools
Tools That Support Specific Hardware:
LM Studio: Runs well on Mac (especially Apple Silicon) and Windows machines
Ollama: Offers optimized performance across platforms with minimal setup
LLaMa.cpp: Built for high-speed inference on CPUs without requiring heavy GPU support
Choose your model and tooling based on your own hardware capabilities and target use case.
Local LLM Tools and Resources
Whether you're a developer, researcher, or casual experimenter, the local LLM ecosystem offers a wide range of tooling.
Popular Local LLM Tools
Tool |
Strengths |
Interface |
Compatibility |
|---|---|---|---|
LM Studio |
Fine-tuning, metrics |
GUI, CLI |
Windows, macOS |
Ollama |
Simplicity, performance |
CLI |
macOS, Linux |
GPT4All |
Broad model support |
GUI |
|
text-generation-webui |
Feature-rich |
Web UI |
Advanced users |
LocalAI |
Versatile platform, API integration |
CLI |
Linux |
Noteworthy Features:
Command Line and Web Interface options for different workflows
Support for multiple model formats and open source models
Ability to run multiple models simultaneously
Access to model parameters and inference settings
With these local LLM tools, anyone can start running models locally—from solo developers to enterprise-scale deployments.
Evaluating Local LLM Performance
Assessing how well your local LLM models perform is essential for refining outputs and ensuring system efficiency. Whether you're deploying for development or production, proper benchmarking guides optimization.
Key Evaluation Metrics
Inference Speed: How quickly responses are generated.
Accuracy: Relevance and correctness of responses.
Memory Usage: RAM and GPU consumption under load.
Model Responsiveness: Latency, particularly in interactive interfaces.
Tools for Performance Testing
Built-in performance dashboards in LM Studio.
Terminal logging via command line tools like Ollama.
External benchmarking scripts tailored for model files in .gguf, .ggml, and .safetensors formats.
To optimize model parameters, track performance in real-world use cases and consider using reduced context length or quantized models for faster results.
Use Cases for Local LLMs
The applications for LLMs locally are both broad and impactful. From individuals working on personal projects to enterprises developing full-fledged systems, the possibilities are expanding rapidly.
Practical Use Cases
Text Generation: Automated content creation, summarization, creative writing.
Code Generation: Generate, debug, or refactor software with natural language prompts.
Logical Reasoning: Use fine-tuned models for decision support or legal inference.
Document Analysis: Process local documents privately without uploading to external servers.
Industries Benefiting Most
Healthcare: Analyze medical data with full HIPAA compliance.
Finance: Automate report generation while maintaining data privacy.
Education: Create tutoring systems that work entirely offline.
Cybersecurity: Red-team simulations without exposing tactics to the cloud.
In the early stages of R&D or product development, these models offer state-of-the-art capabilities without infrastructure investment.
Large Language Models LLMs in Industry
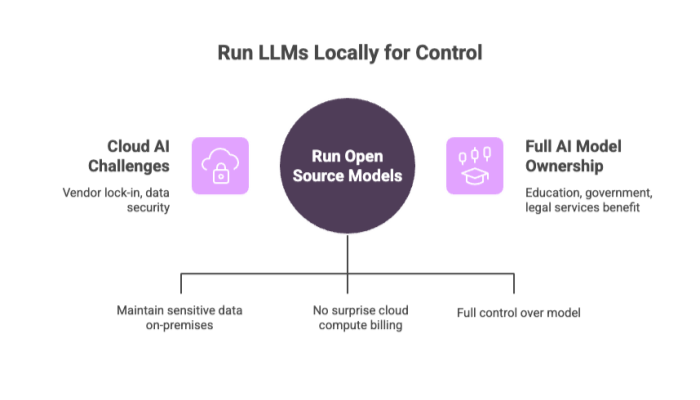
The adoption of large language models (LLMs) across industries is growing, but cloud-based AI comes with challenges like vendor lock-in, data security, and recurring costs.
Running open source models locally provides:
Security and Compliance: Maintain sensitive data on-premises.
Cost Predictability: No surprise billing from cloud compute usage.
Customization: Full control over the base model, architecture, and training data.
Industries like education, government, and legal services benefit from full ownership over their AI models.
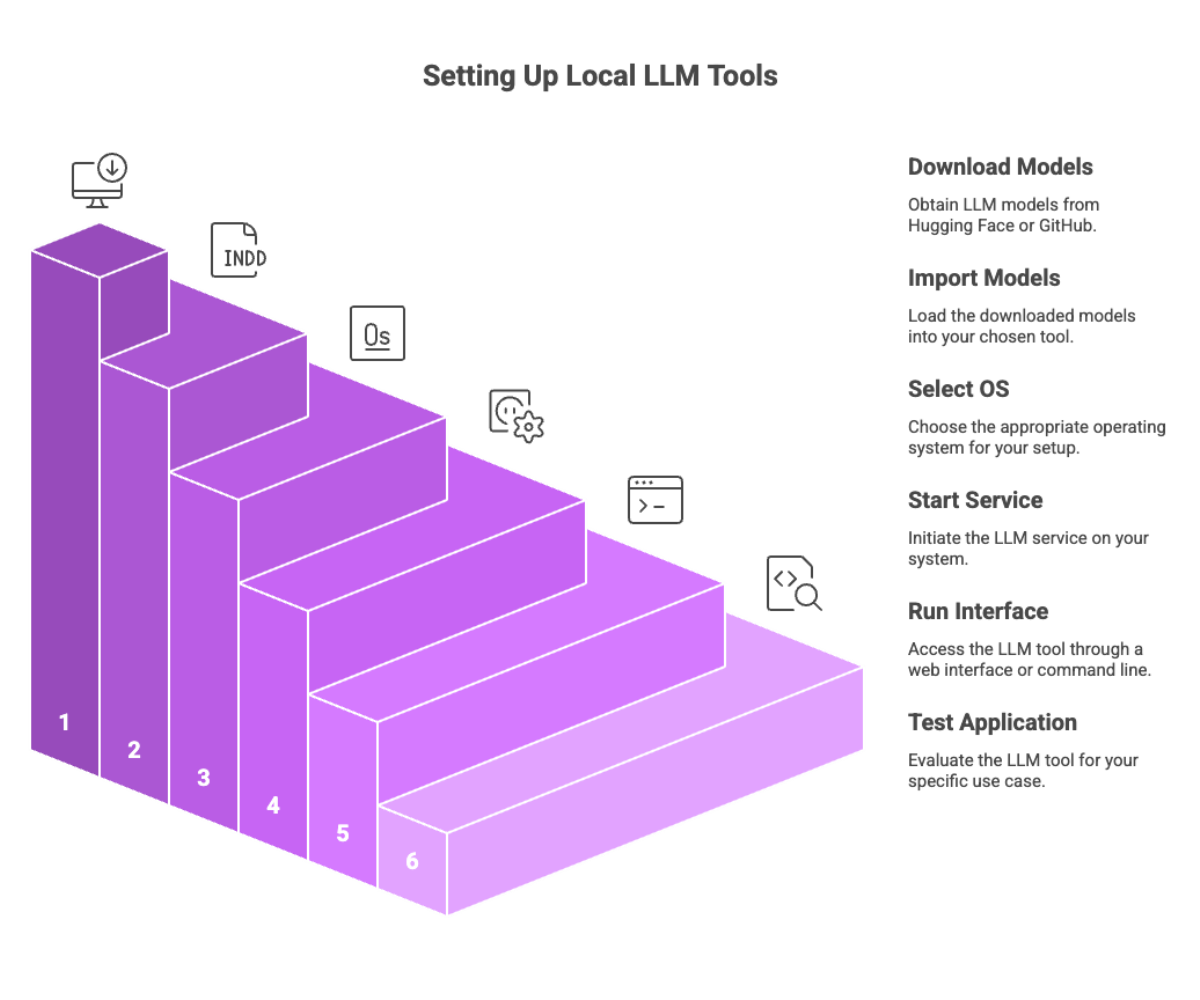
Running LLM Locally with Popular Tools
Here’s how to get started with the most popular local LLM tools.
Top Tools:
LM Studio: Easy-to-use, supports model import, and provides deep control over model parameters.
Ollama: Lightweight and fast; excellent for Apple users and CLI fans.
GPT4All: Simple UI and great documentation for beginners.
LLaMa.cpp: Perfect for performance testing and CPU-only environments.
Setup Summary:
Download models via Hugging Face or GitHub.
Import the model files into your tool of choice.
Select your operating system and start the service.
Run via web interface or command line.
Test for your specific application (e.g., chatbot, document assistant, coding agent).
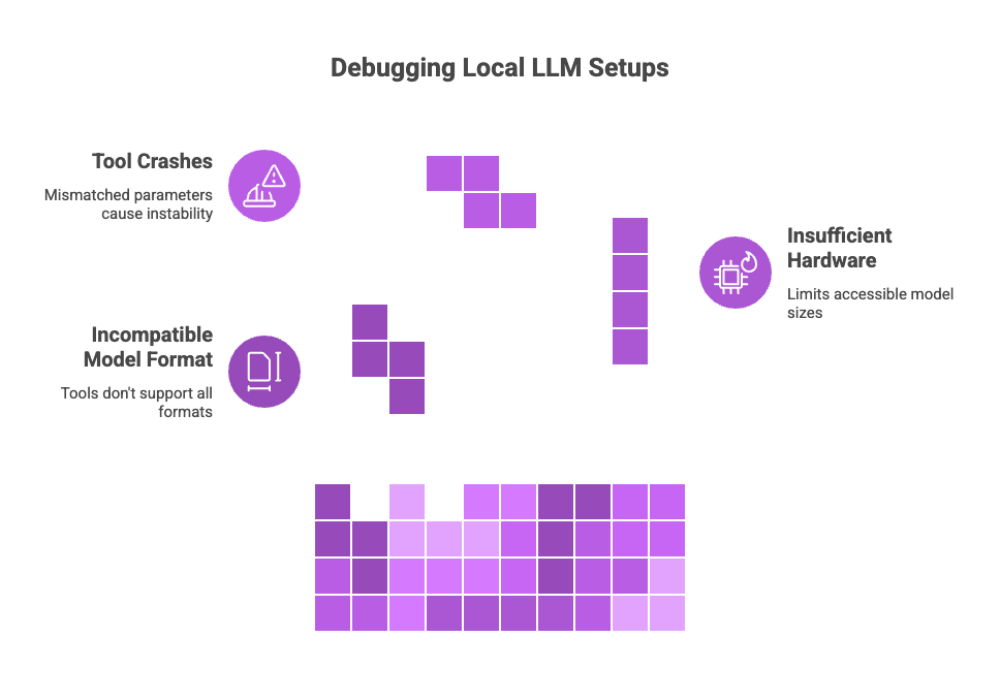
Troubleshooting Common Issues
Common Pitfalls
Incompatible Model Format: Not all tools support all model formats (e.g., GGUF vs GGML).
Insufficient Hardware: Low video RAM or CPU may limit model size.
Tool Crashes or Freezes: Often due to mismatched model parameters or corrupted model files.
How to Fix:
Check forums like GitHub Discussions or Reddit’s LLM communities.
Use logging tools in LM Studio or --verbose mode in Ollama.
Join Discord groups from each tool’s official repo for fast feedback.
Having local visibility over the environment simplifies debugging compared to opaque cloud APIs.
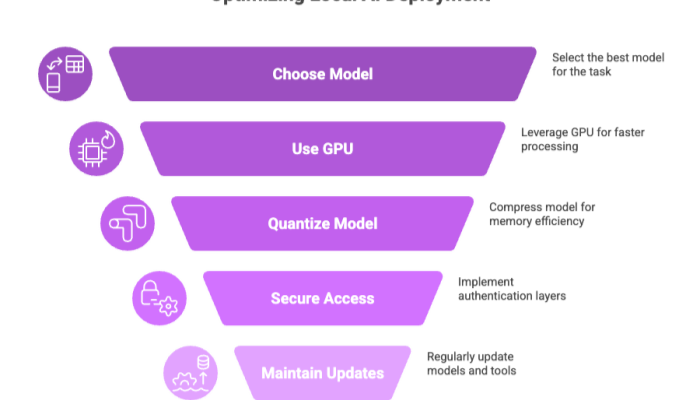
Best Practices for Local LLM Deployment
If you're deploying local AI at scale or for production-grade projects, these tips help maintain performance, security, and consistency:
Choose the Right Model: Match the best model to your task and hardware.
Use GPU Acceleration: Where available, leverage CUDA or Metal for faster processing.
Quantize for Speed: Compress the base model with 4-bit or 8-bit quantization to save memory.
Secure Access: Run tools behind authentication layers if on a local server.
Maintain Updates: Check GitHub for model improvements and bug fixes frequently.
Conclusion and Future Directions
Running LLMs locally has shifted from niche to mainstream, giving developers and organizations a secure, affordable, and highly flexible way to leverage the power of AI models.

Final Thoughts:
Subscription-Free AI: Avoid ongoing API key costs.
Runs Locally = Full Privacy: No data leaks or cloud breaches.
Flexible Infrastructure: Adaptable to any operating system or consumer hardware.
Looking Ahead
Expect rapid innovation in:
Local LLM training techniques
More efficient model formats
Seamless tool integrations
Deeper community support from the open source community
Additional Resources
For more help setting up or fine-tuning local LLM models, explore:
Hugging Face – for open source models
LangChain – for building AI workflows
LM Studio – full-stack tool for running models locally
Cognativ – for scalable server-side AI
Local LLM Community and Support
The growing local LLM community is the backbone of innovation in this space. Join and contribute to open-source projects, attend meetups, and collaborate with experts building the next generation of AI systems.
Reddit: r/LocalLLaMA
Discord: Channels for each LLM tool
GitHub: Join issues, star projects, fork repos
YouTube: Step-by-step tutorials for every tool and model
