
What is a Local LLM? A Practical Guide for Effective Implementation
Local large language models (LLMs) are transforming the way individuals and enterprises deploy AI. Instead of relying on cloud-based AI solutions, which can incur high subscription fees, recurring API costs, and pose data privacy risks, local LLMs run on your own hardware—this is known as local deployment.
By enabling AI to run on a local machine, organizations gain full control over their training data and model outputs. This significantly reduces the reliance on external servers and cloud providers, eliminating exposure to potential third-party breaches. As a result, local LLMs are especially valuable in sectors that demand strict data governance, such as:
Healthcare (HIPAA compliance)
-
Finance (handling PII, regulatory oversight)
-
Legal (attorney-client privilege and document confidentiality)
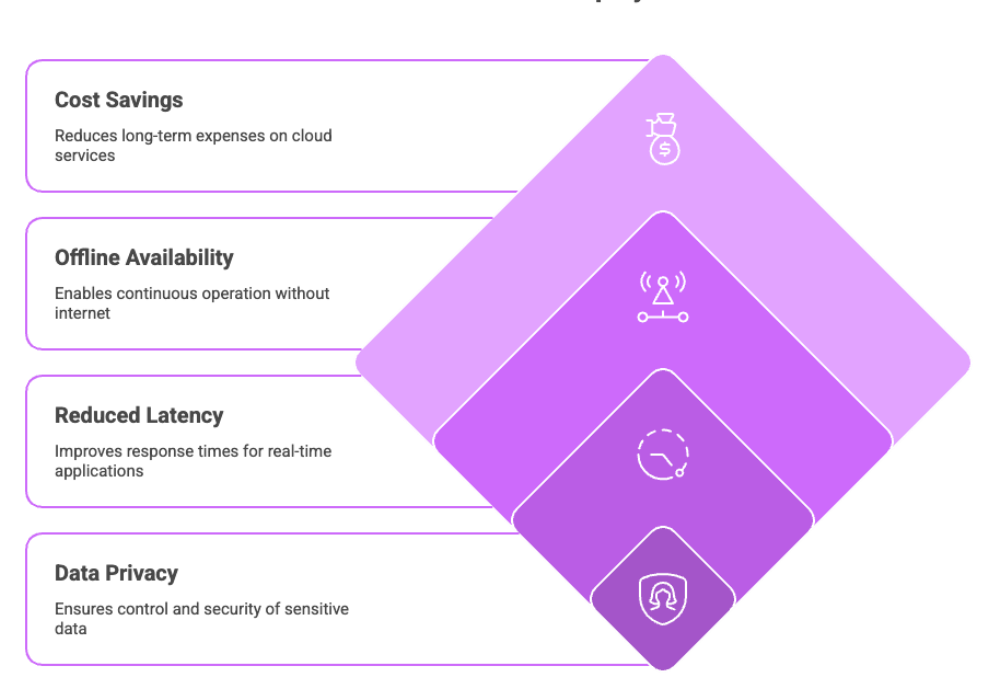
Beyond privacy, running LLMs locally offers reduced latency, improved offline availability, and long-term cost savings—making them a practical and scalable solution for AI deployment.

Basics of Large Language Models (LLMs)
At the heart of many AI applications are large language models, which are sophisticated machine learning systems trained to understand and generate human-like text. These ML models are powered by architectures such as the Generative Pre-trained Transformer (GPT), allowing them to process, understand, and produce complex language-based outputs.
Key Characteristics of LLMs
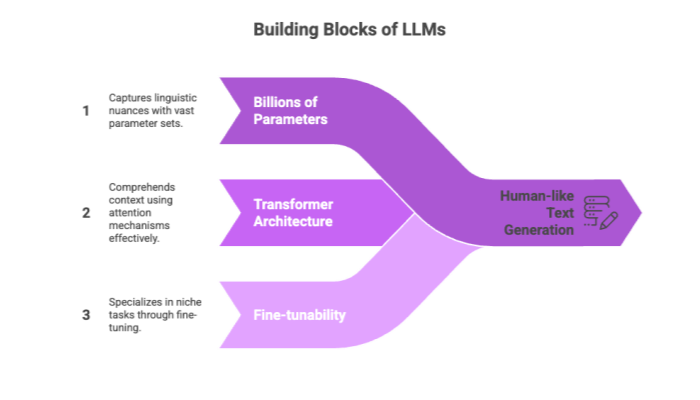
Billions to trillions of parameters: Models like GPT-3 and GPT-4 use these to capture linguistic nuance.
Transformer architecture: This model design leverages attention mechanisms to comprehend the context of words across sentences, improving relevance and coherence.
Fine-tunability: LLMs can be trained further using smaller datasets to specialize in niche tasks—a key feature for local LLM implementation.
By leveraging the transformer architecture, LLMs support a variety of use cases: text generation, summarization, Q&A systems, and even code generation.
Local vs Cloud-Based LLMs
Choosing between a local model and a cloud-based LLM depends on the specific needs of your project or organization. Here's how they compare:
Advantages of Local LLMs
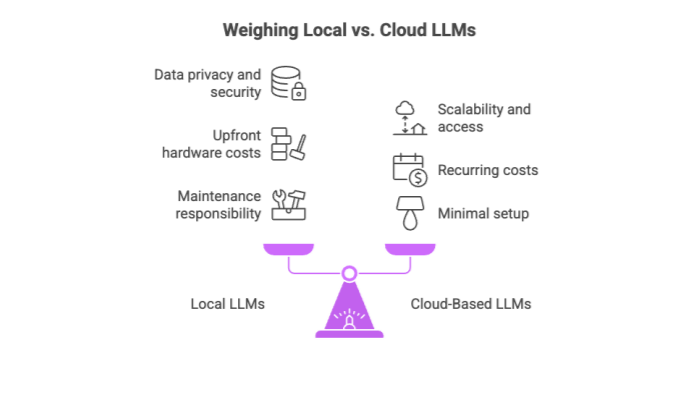
Data privacy and security: No data leaves your network—ideal for working with sensitive data.
Offline functionality: Local LLMs shine in environments without stable internet connectivity.
Avoid vendor lock-in: Gain flexibility and full model ownership.
Limitations
Upfront hardware costs: You need GPUs, RAM, and storage.
Maintenance responsibility: You must manage system updates and security patches.
Cloud-Based LLMs
While they offer scalability, easy access, and minimal setup, they come with recurring costs and security trade-offs. Moreover, depending on a third-party provider means giving up some control over your AI systems and proprietary data.
Hardware Considerations for Running LLMs Locally
To deploy local large language models effectively, your own computer must meet minimum hardware requirements. These specifications will vary depending on the model size, but some general guidelines apply.
Essential Hardware Specs
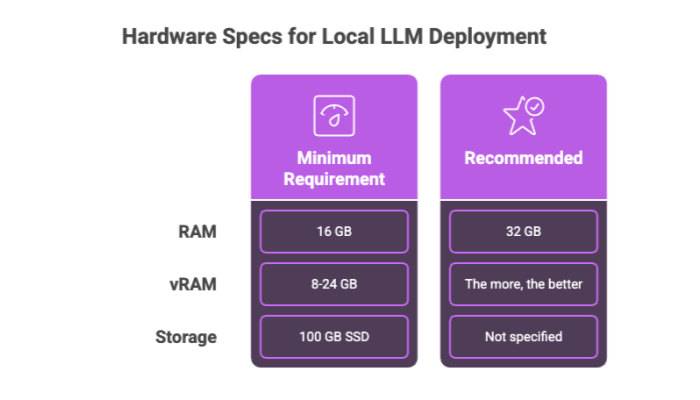
RAM: At least 16 GB; 32 GB is ideal for handling resource-intensive tasks.
vRAM (Video RAM): The more, the better. Most large models require 8GB to 24GB of vRAM for optimal performance.
Storage: SSD with a minimum of 100 GB free space for model files, dependencies, and logs.
Consumer Hardware Tip
Even mid-range laptops or desktops can run smaller models, especially if you use optimized versions or quantized weights (e.g., INT8, GGUF). However, for state-of-the-art performance, a dedicated workstation or server is recommended.
Fine-Tuning for Local LLM Implementation
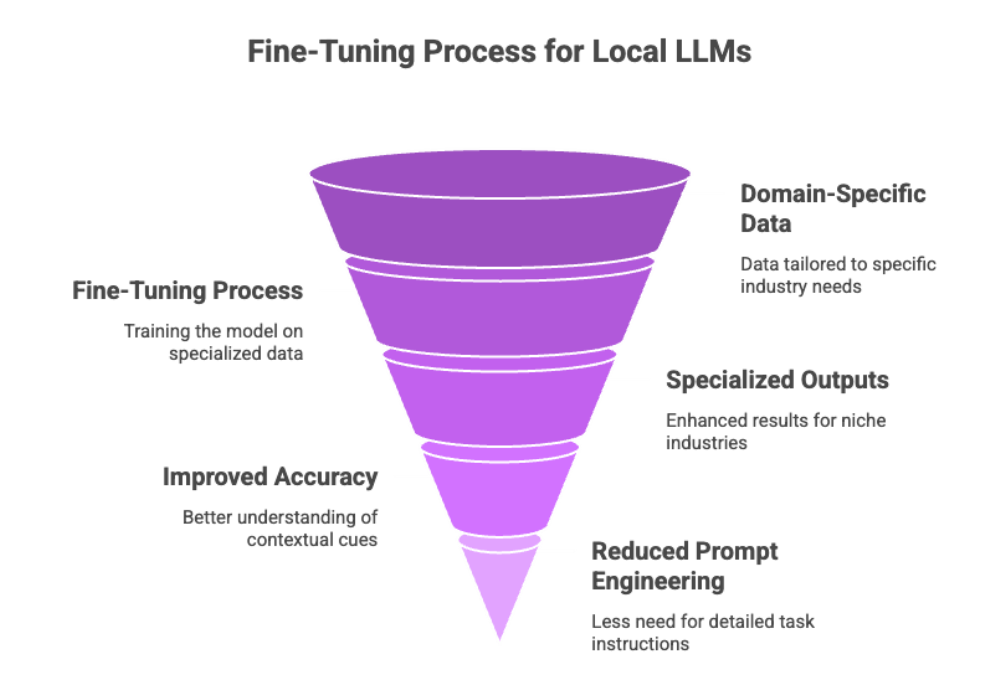
Fine-tuning is the process of training a base model on domain-specific data to improve its relevance and performance. For local LLMs, fine-tuning ensures the model understands unique terminology, workflows, or datasets relevant to your application.
Benefits of Fine Tuning Models Locally
Specialized outputs: Better results for niche industries like law, medicine, or software development.
Improved accuracy: The model learns contextual cues unique to your dataset.
Reduced need for prompt engineering: Once fine-tuned, the model “understands” tasks better.
Unlike initial model training, which requires vast datasets and compute power, fine-tuning is much more feasible on local hardware using tools like LoRA (Low-Rank Adaptation) or QLoRA.
Best Models for Local LLMs
The open source community continuously releases new models, each optimized for different tasks. While it's tempting to try the latest, tested models provide better cost-effectiveness and stability for running local LLMs.
Popular and Reliable Models
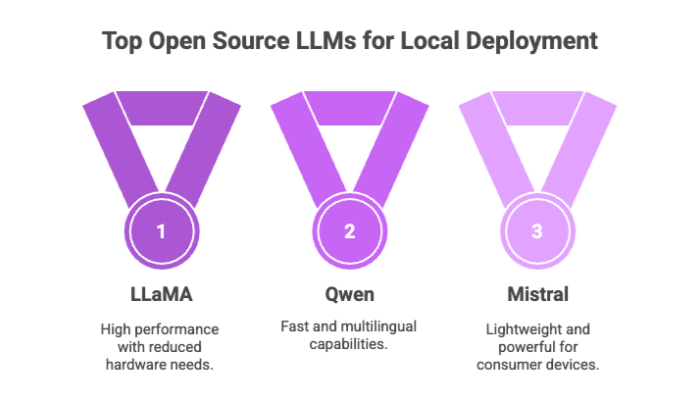
LLaMA (Meta): Offers high competitive performance with reduced hardware needs.
Qwen (Alibaba): Known for its speed and multilingual capabilities.
Mistral: A lightweight yet powerful model ideal for consumer devices.
These open source models are widely benchmarked, maintained by vibrant communities, and often come with pre-trained weights for quick deployment.
Implementing Local LLMs with AI Tools
Thanks to AI tools, implementing and managing local LLMs is no longer a task reserved for advanced developers.
Top Local LLM Tools
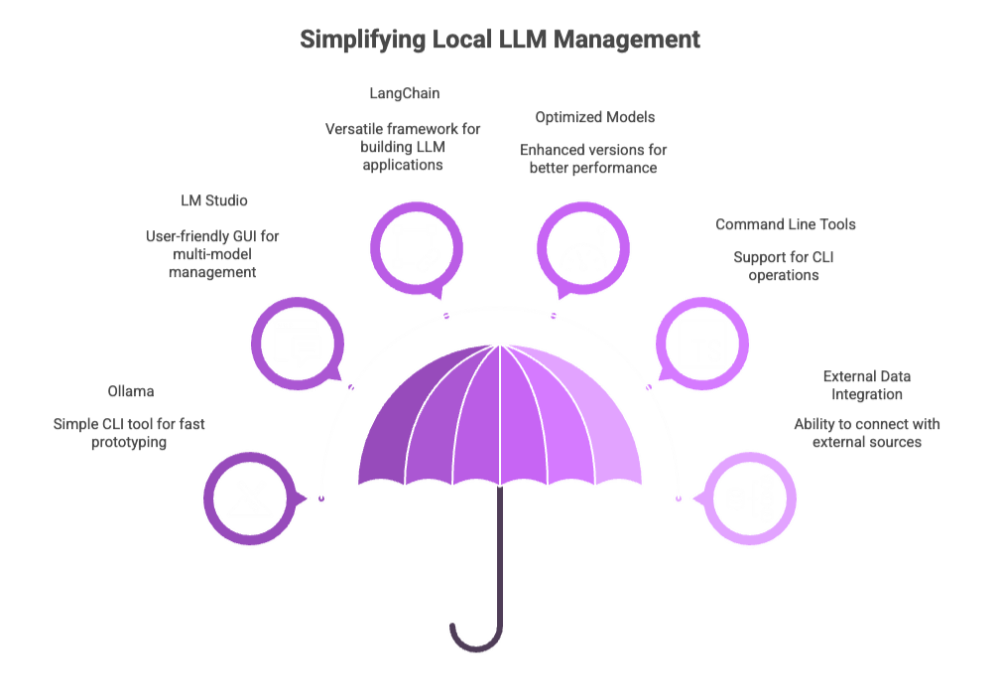
Ollama
Simple CLI tool for running models with minimal setup
Supports automatic model downloading and local execution
Ideal for fast prototyping
LM Studio
Provides a user-friendly GUI for running models
Supports chat, prompt engineering, and multi-model management
Available on Windows, macOS, and Linux
LangChain
A versatile framework for building applications using local LLMs
Supports chaining prompts, retrieval, and agent frameworks
Integrates easily with both local and cloud LLM providers
Features to Look For
Optimized versions of models
Support for command line tools
Integration with external data sources or APIs
These platforms simplify managing local LLMs, making it accessible even for users with limited technical expertise.
Local LLM Security and Ethics
When it comes to security, local LLMs offer clear advantages. By keeping everything on your own hardware, you reduce the risk of breaches, misuse, or data exposure.
Ethical Advantages
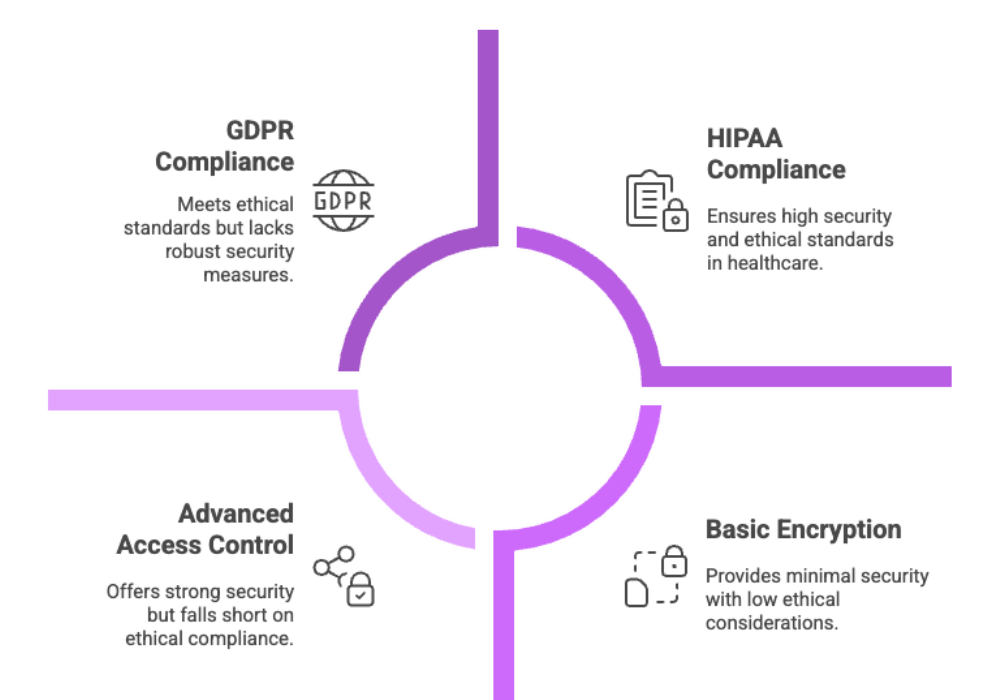
Compliance with HIPAA, GDPR: Especially critical for industries handling sensitive information
Avoiding surveillance capitalism: No sharing of behavioral data with third-party providers
Full control over training and outputs: Reduces the chance of biased or hallucinated responses
Security should include best practices like encryption at rest, access control, and regular audit logging to ensure accountability.
Up next: The second half of the article will include cost and ROI analysis, scalability, integration, real-world use cases, and a future-facing conclusion to meet our target word count and keyword density goals.
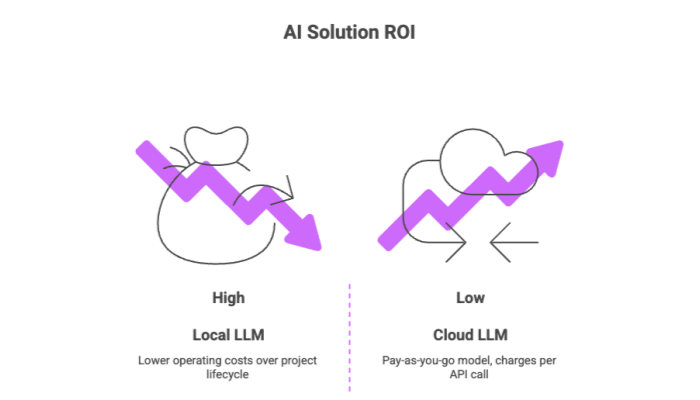
Local LLM Cost and ROI
One of the most compelling reasons to consider running local LLMs is the potential for substantial cost savings. While cloud-based AI solutions operate on a pay-as-you-go model—charging per API call or compute cycle—local deployment entails a one-time hardware investment with low ongoing costs.
Cost Breakdown
Initial Costs: GPU purchase, storage expansion, cooling, power supply upgrades
Recurring Costs: Primarily electricity and occasional hardware upgrades
Eliminated Costs: No more API usage fees, bandwidth fees, or subscription charges
Over time, this model delivers excellent return on investment (ROI)—especially for enterprises that make heavy use of AI systems.
ROI Benefits
Lower operating costs over the lifecycle of the project
Enables high-volume usage (e.g., content generation, batch data processing) at fixed costs
Improved team productivity by enabling always-on local models
Local LLM Scalability and Performance
A common misconception is that local LLMs are only suitable for small-scale tasks. In reality, they can be scaled just like any other system—when implemented with flexibility in mind.
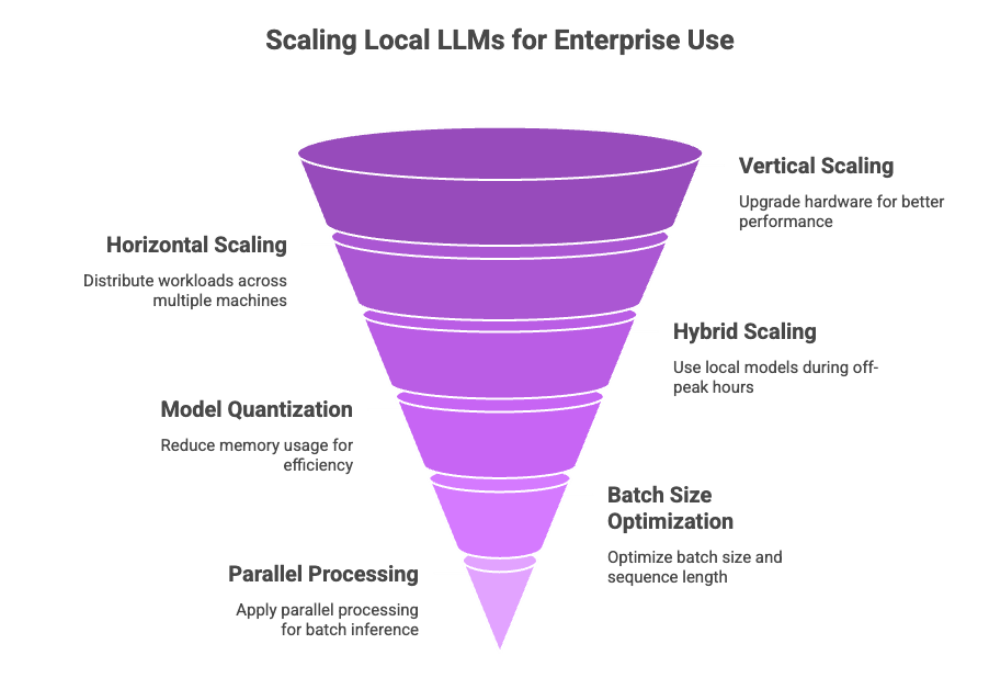
Scaling Strategies
Vertical scaling: Upgrade your local machine or server with better GPUs, more RAM, and faster SSDs
Horizontal scaling: Distribute workloads across multiple machines via LAN or Kubernetes-style clusters
Hybrid scaling: Use local models during off-peak hours and burst to cloud during spikes
Ensuring Performance
To achieve optimal performance, you can:
Use model quantization to reduce memory usage
Optimize batch size and sequence length for your task
Apply parallel processing for batch inference
With these approaches, even large models can run efficiently, maintaining low latency and high throughput for enterprise-scale applications.
Local LLM Integration and Development
To maximize impact, local LLMs must integrate seamlessly with your existing infrastructure, apps, and data pipelines.
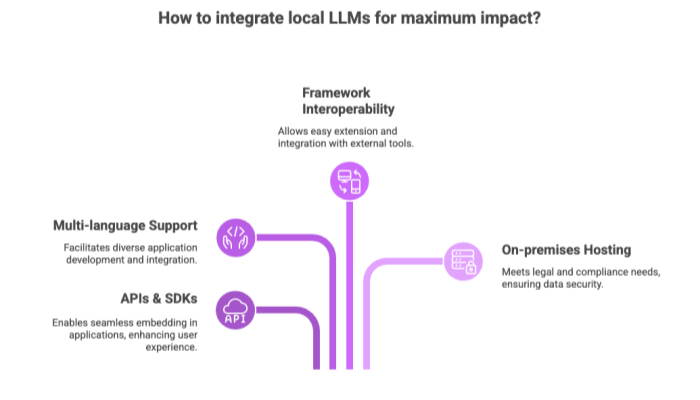
Integration Opportunities
APIs & SDKs: Many local LLM tools provide plug-and-play interfaces for embedding in web and mobile applications
Multi-language support: Python, JavaScript, Go, Rust, and more are often supported out of the box
Framework interoperability: Tools like LangChain and Hugging Face Transformers allow easy extension of own models or integration with external tools
Developer Benefits
Rapid prototyping with open source LLMs
Ability to fine-tune or retrain models with own set of data
On-premises model hosting to meet legal or compliance needs
By streamlining integration, businesses can accelerate time-to-market and reduce reliance on external vendors.
Local LLM Use Cases and Applications
The flexibility of local large language models opens up a wide variety of use cases, both technical and non-technical.
Common Use Cases
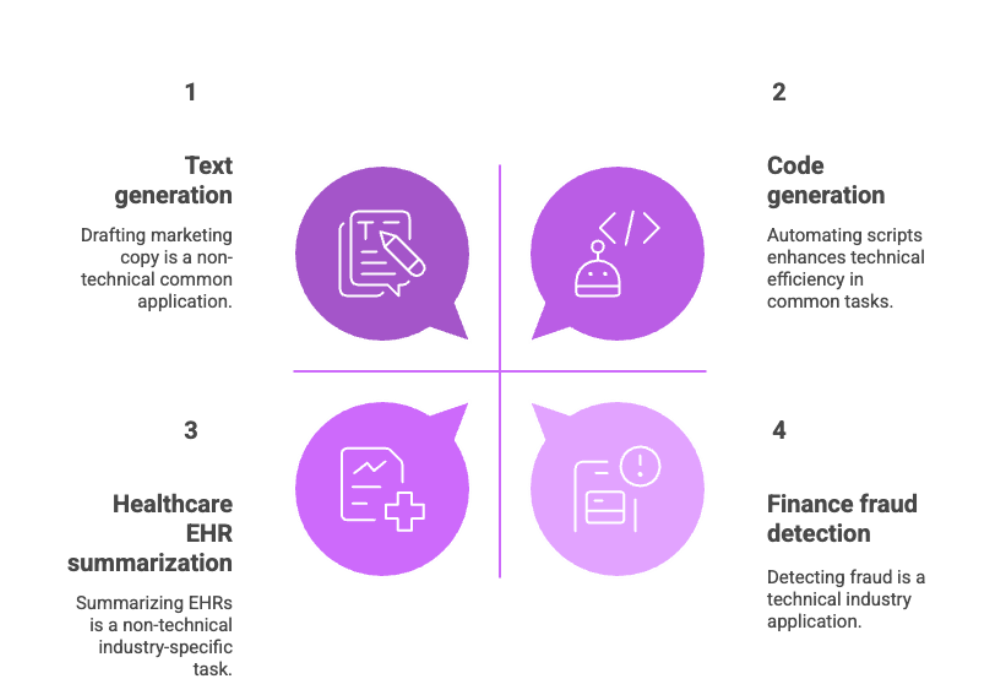
Text generation: Drafting marketing copy, documentation, or reports
Code generation: Building internal developer tools, automating scripts
Data analysis: Parsing and summarizing local documents
Chatbots and assistants: Private customer service bots that don’t require an internet connection
Learn more about examples of software development types and applications.
Industry Applications
Healthcare: EHR summarization, diagnosis suggestions, medical transcription
Finance: Automated report generation, fraud detection
Legal: Case summarization, contract analysis, discovery support
What sets LLMs locally apart is their ability to perform these tasks without sending sensitive information to the cloud.
Conclusion and Future Developments
As the field of AI and machine learning matures, it's clear that local LLMs are becoming a vital component of the next generation of enterprise AI strategies.
Key Takeaways
What is a local LLM? It’s a powerful AI model run on your own computer, independent of cloud providers.
Why adopt it? To gain data privacy, eliminate vendor lock-in, and reduce long-term costs.
Who should use it? Any organization handling proprietary data, working in regulated sectors, or seeking more control over AI systems.
Looking Forward
The open source community continues to deliver better available models, improved toolchains, and expanded interoperability. Innovations in retrieval augmented generation, multi-modal models, and lightweight specialized models will make local deployment more powerful and efficient.
Businesses that embrace local LLMs today are not just safeguarding their data—they're investing in long-term, scalable, and secure AI systems.

