
What is a Private LLM? Understanding Its Benefits and Challenges
Private LLMs emerge as a strategic solution, allowing businesses to implement powerful language models within their organization's secure environment, thereby protecting sensitive information and maintaining full control over proprietary data. This article delves into what is a private LLM, its key advantages, challenges, and best practices for leveraging these models while ensuring consistent performance and robust data governance.
Key Takeaways
Private LLMs provide organizations with enhanced data security, full control over sensitive information, and support for regulatory compliance by operating within a secure, controlled environment.
Implementing private LLMs requires significant computational resources, technical expertise, and ongoing maintenance but offers benefits such as custom model tuning and reduced vendor dependency.
Choosing between public and private LLMs depends on factors like data privacy needs, compliance requirements, cost considerations, and the desired level of customization and control.

Introduction to Large Language Models
Large language models (LLMs) are sophisticated AI systems engineered to understand, interpret, and generate human language with remarkable accuracy.
By training on extensive datasets, these language models learn the nuances of grammar, context, and meaning, enabling them to perform a wide range of tasks—from content generation to complex decision-making.
As LLMs become integral to business operations, concerns about data privacy and data protection have grown, especially when sensitive data is involved. Private LLMs offer organizations a way to harness the power of large language models while maintaining full control over their data.
By keeping sensitive information within a secure environment, private LLMs ensure that data privacy is prioritized and that proprietary or regulated data remains protected throughout the content generation process.
What is a Private LLM?
A Private LLM (Private Large Language Model) refers to an LLM deployed in a secure, localized environment — often within an organization’s internal infrastructure or private cloud. Unlike public LLMs, which are hosted and managed by third-party providers, private LLMs allow businesses to:
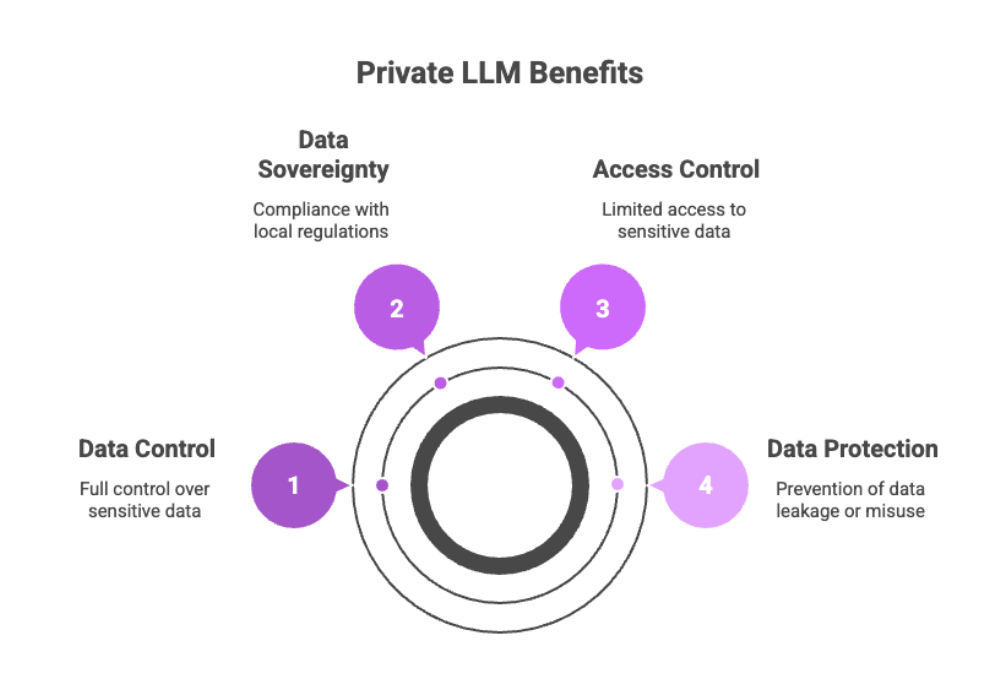
Maintain full control over sensitive data
Ensure data sovereignty and compliance with local regulations
Limit access to sensitive and customer data, reducing the risk of unauthorized data exposure
Avoid data leakage or misuse
These models are especially valuable in sectors that rely on proprietary or sensitive data, such as healthcare (PHI), finance (PII), law, and defense.
Private LLMs enable granular data access controls, ensuring only authorized personnel can view or use internal data. They are ideal for organizations that want to leverage their own data for model training while minimizing data exposure risks, especially when handling confidential or customer data.
Data Collection and Private LLMs
Effective data collection is foundational to developing robust private LLMs. Organizations must carefully curate and manage input data to ensure it is both relevant and compliant with industry regulations. This process requires significant computational resources and technical expertise, as the quality and security of the training data directly impact the model’s performance and risk profile.
With private LLMs, organizations can implement strict data governance practices, limiting access to sensitive information and reducing the risk of data breaches. By controlling the entire data collection and processing pipeline, private LLMs enhance data privacy and security, allowing organizations to protect sensitive data and maintain compliance with evolving privacy standards.
Key Benefits of Private LLMs
Private LLMs represent a crucial advancement in AI technology, offering organizations a secure and customizable way to leverage large language models.
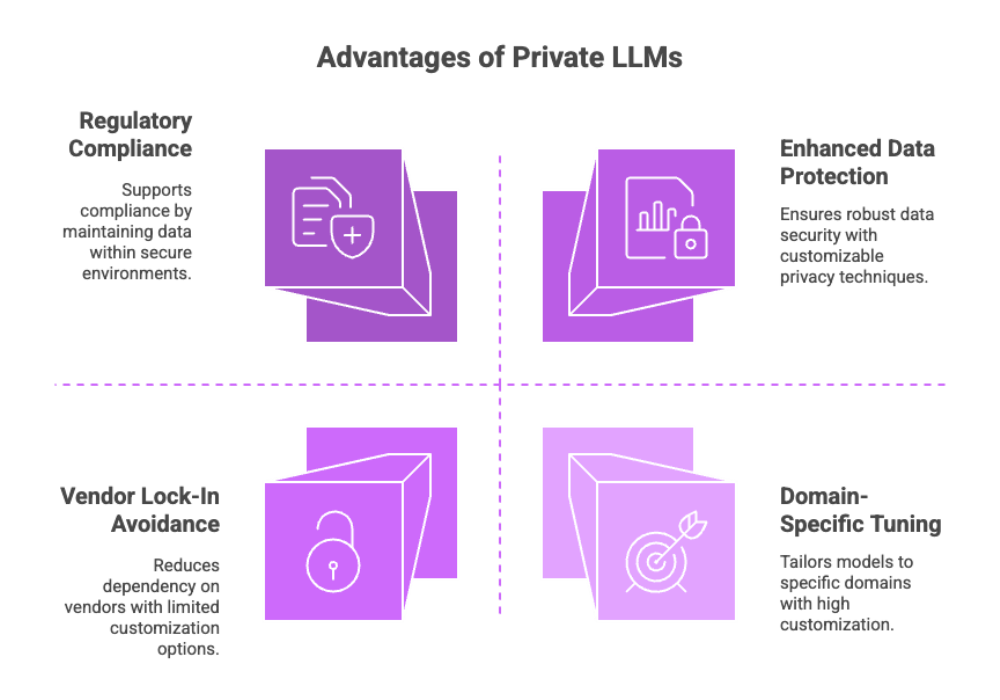
1. Data Security and Privacy
Private LLMs offer enhanced data protection by keeping all information within a controlled environment. With robust security measures like encryption, access control, and isolated compute environments, companies can drastically reduce the risk of:
Data breaches
Insider threats
Unauthorized third-party access
Private LLMs can further secure data processing by leveraging privacy-preserving techniques such as federated learning and homomorphic encryption, ensuring sensitive information remains protected during model training and inference. Additionally, private LLMs help organizations maintain compliance with privacy regulations by safeguarding the rights of data subjects and ensuring personal data is handled according to legal requirements.
2. Compliance with Regulatory Requirements
Private deployments support compliance with GDPR, HIPAA, and other data governance standards by avoiding transmission of sensitive information to external servers, and legal services play a crucial role in implementing effective data privacy measures. A well-defined data strategy is essential for aligning private LLM deployments with regulatory requirements.
3. Custom Model Tuning
Organizations can fine-tune their private LLMs using domain-specific data, ensuring outputs that are accurate and contextually relevant. Rather than training from scratch, organizations can fine-tune an existing model to suit their needs, which is more cost-effective and efficient. Understanding the model's architecture is crucial for effective customization of the LLM model, allowing for better adaptation to specific tasks. This is ideal for niche industries where public LLMs might produce generalized or irrelevant responses.
4. Reduced Vendor Lock-In
Building a private LLM enables businesses to avoid dependence on commercial APIs and pricing structures, as well as to choose between open-source and proprietary models, offering long-term cost benefits and greater operational independence. However, it is important to consider the computational costs and the need for extensive computational resources required for private LLMs, as these factors significantly influence the overall cost-effectiveness and scalability in the long run.
Challenges in Implementing Private LLMs
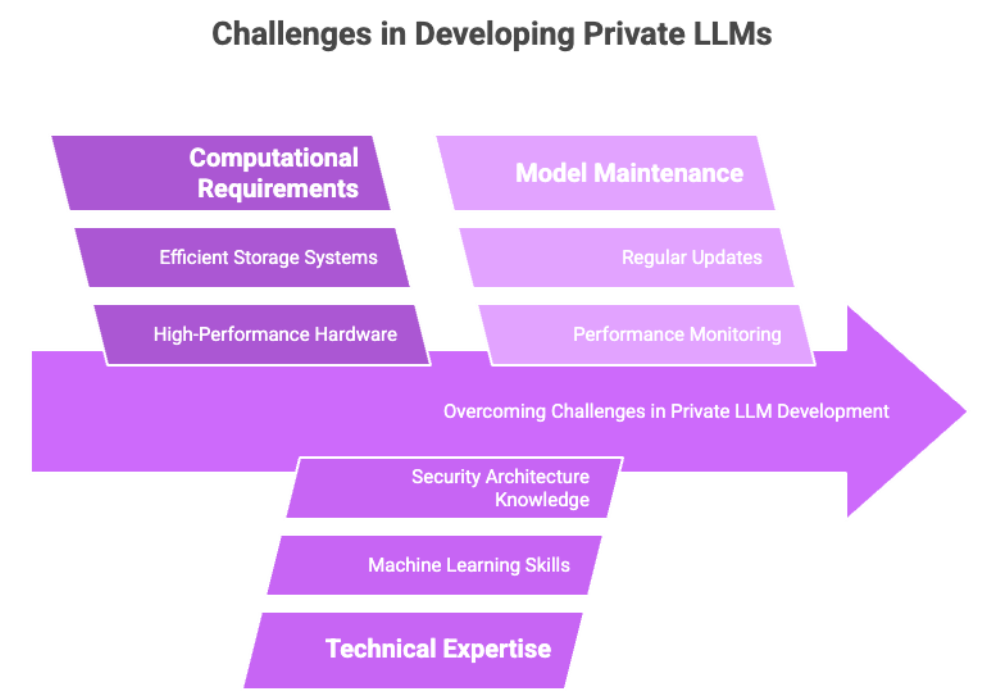
Despite their advantages, private LLMs come with technical and strategic challenges, including internal security concerns. Developing private LLMs requires careful planning to address these challenges.
1. High Computational Requirements
Training large language models requires significant computational power, including access to high-performance GPUs or TPUs, large memory capacity, and efficient storage systems.
2. Need for Technical Expertise
Developing and maintaining a private LLM demands expertise in:
Machine learning
NLP
Data engineering
3. Ongoing Model Maintenance
LLMs degrade over time without continuous evaluation, which is essential for keeping the model up to date with the latest data and techniques, as well as retraining and fine-tuning. Businesses must implement regular updates, performance monitoring, and data integrity checks.
Private LLM vs. Public LLM
When comparing public and private LLMs, it's important to note that public and private llms differ significantly in terms of accessibility, data privacy, and organizational control.
Feature |
Private LLM |
Public LLM |
|---|---|---|
Data Control |
Full control (in-house). Private LLM deployments are managed internally, giving organizations direct oversight of data usage and protection. |
Minimal control (third-party servers). Public large language models are typically accessed via third-party APIs, limiting user control over data. |
Security |
High, customized. Private LLM deployments enhance data privacy and support governance frameworks. |
Standardized, limited customization. Public large language models may use user data for training, raising data usage and privacy concerns. |
Compliance |
Easier to align with industry-specific regulations. Private LLM deployments are critical for organizations prioritizing data privacy and compliance. |
Risk of non-compliance. Public large language models can incorporate user data into their training sets, which may violate data governance regulations. |
Customization |
Fully customizable on proprietary data. Private LLMs rely on internal data for privacy, unlike retrieval augmented generation approaches that combine LLMs with external data sources. |
Limited to prompts or external fine-tuning. Public LLMs may not offer the same level of data isolation as private deployments. |
Cost |
High upfront, low long-term |
Low entry cost, variable usage fees |
Model Training and Fine-Tuning Strategies
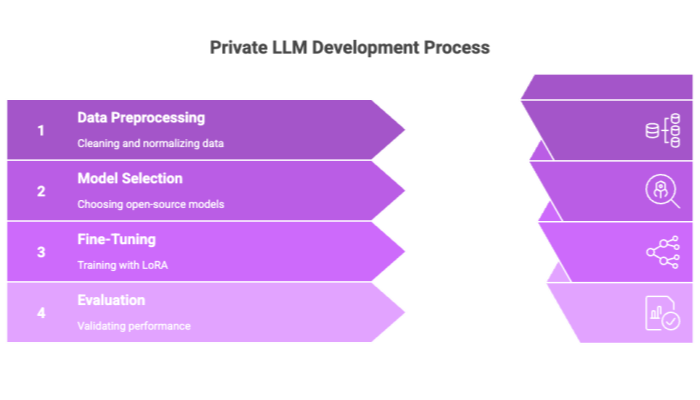
Private LLM development typically follows these steps:
Data Collection: Gather domain-specific and relevant training datasets.
Preprocessing: Clean, normalize, and tokenize the data. During both training and inference, user inputs are also tokenized and processed so the model can convert them into vector representations for similarity evaluation and accurate responses.
Model Selection: Choose from open-source models like LLaMA, Mistral, or Google Gemma.
Fine-Tuning: Train the model using techniques like Low-Rank Adaptation (LoRA) to reduce resource needs.
Evaluation: Use metrics like perplexity, accuracy, and F1 score to validate performance.
Generative AI with Private LLMs
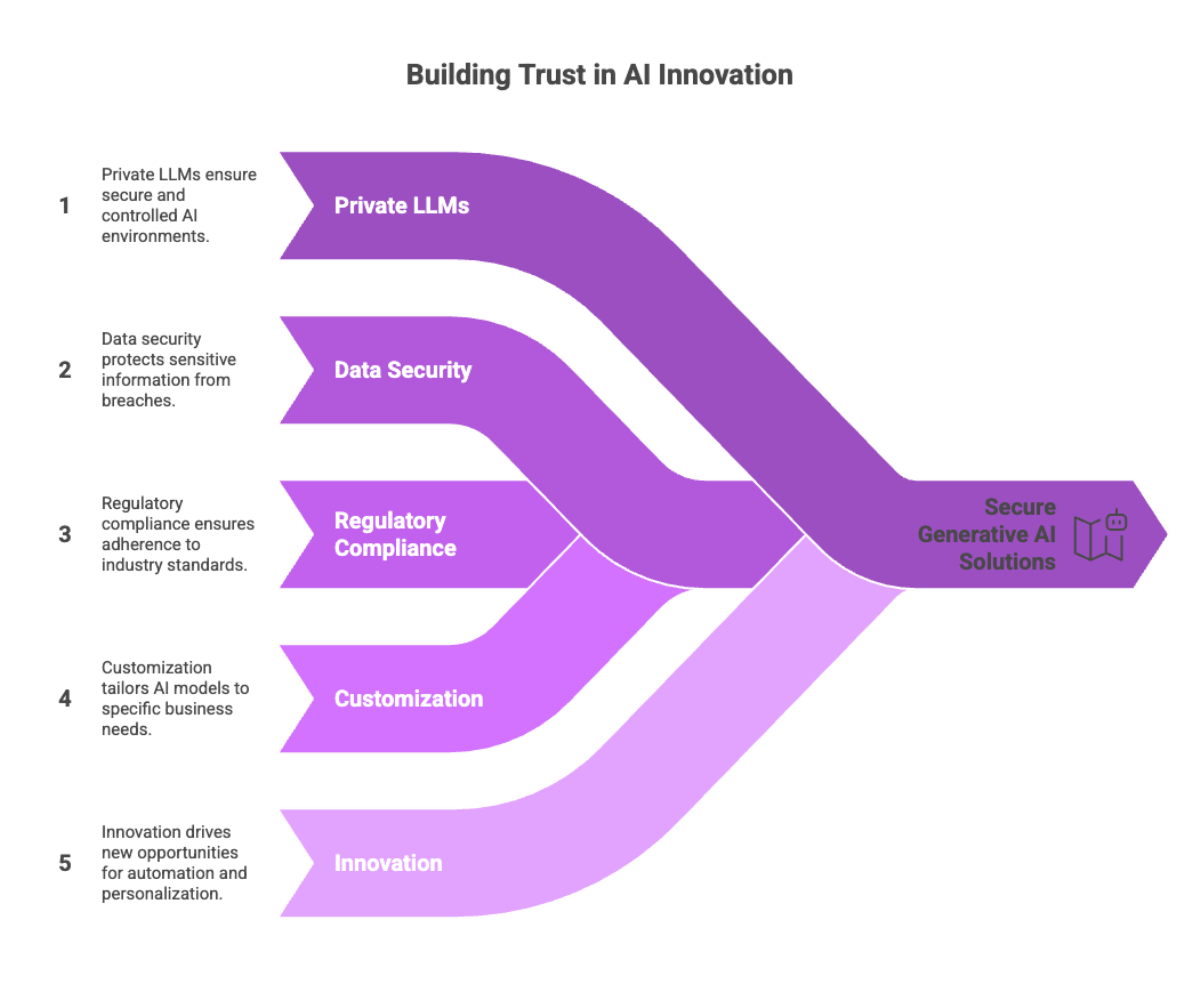
Generative AI leverages advanced language models to create new content, such as text, images, or even code, tailored to specific business needs. When powered by private LLMs, generative AI solutions can be developed and deployed within a secure, controlled environment. This approach allows organizations to innovate with confidence, knowing that sensitive data is protected from unauthorized access and potential data breaches.
By using private LLMs for generative AI, businesses can unlock new opportunities for automation and personalization while ensuring that data privacy and security remain at the forefront of their AI strategy. This balance of innovation and protection is essential for organizations operating in regulated industries or handling confidential information.
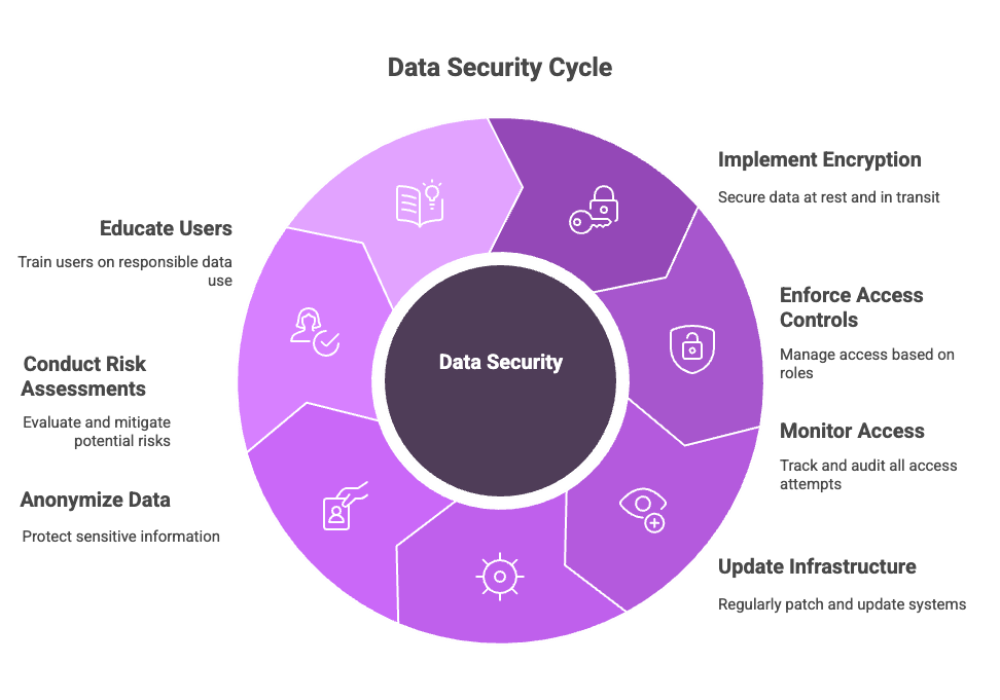
Best Practices for Secure Private LLM Deployment
Use encryption-at-rest and in-transit
Implement role-based access controls
Monitor all access with audit trails
Regularly patch and update infrastructure
Ensure data anonymization or tokenization
Perform risk assessments and compliance audits
Promote user education to ensure responsible and informed use, including understanding ethical considerations, proper data handling, model limitations, and potential biases
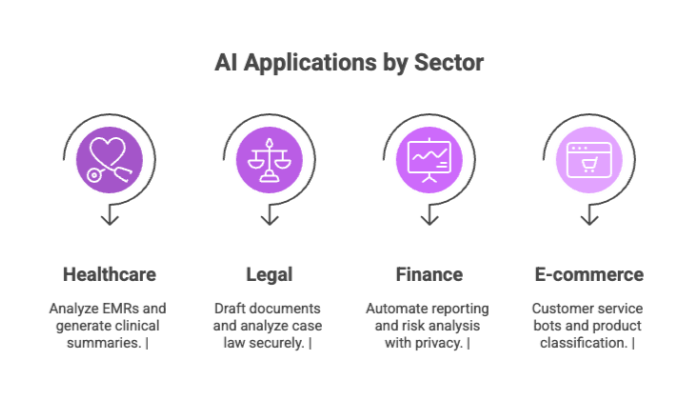
Applications of Private LLMs
Healthcare: Analyze EMRs, generate clinical summaries
Legal: Draft documents, analyze case law securely
Finance: Automate reporting, risk analysis with full data privacy
E-commerce: Customer service bots, product classification
Final Thoughts: Should You Build a Private LLM?
For organizations dealing with sensitive, proprietary, or regulated data, the case for private LLMs is compelling. Although they require upfront investment in infrastructure and talent, the long-term value in terms of data security, performance, and control can outweigh the challenges.
As LLM adoption expands, private deployments will become the standard for businesses that view data privacy and compliance not as options — but as mandates.

