Is BERT an LLM? Understanding Its Role in Natural Language Processing
Language models are a crucial part of natural language processing (NLP) tasks, enabling machines to understand and generate human language.
They assign probabilities to sequences of tokens, learn statistical structure, and support a wide range of natural language processing tasks from text classification to language translation.
Large language models have revolutionized research and production systems by scaling data, parameters, and compute.
As parameter counts grow, these systems capture richer language understanding and deliver stronger generalization across domains.
BERT—Bidirectional Encoder Representations from Transformers—is a notable example of a language model that reshaped the field.
It introduced bidirectional context encoding and pushed state-of-the-art results across many NLP tasks.

Is BERT an LLM?
The short answer is: BERT is a language model, but it is not an LLM in the contemporary sense used for generative assistants.
Today the phrase large language models often refers to decoder-style generative systems that can produce free-form text, follow instructions, and engage in dialogue.
BERT is an encoder-only transformer that focuses on contextual representation learning rather than open-ended text generation.
While the bert model can be large in terms of parameters, its training objective and architecture separate it from generative pre-trained transformer systems.
Understanding this distinction clarifies where BERT excels and where decoder models dominate.

What Is BERT?
BERT stands for Bidirectional Encoder Representations from Transformers.
It was introduced by Google Research in 2018 to improve natural language understanding by modeling context in both left and right directions simultaneously.
The bert model uses an encoder stack to transform input text into contextual vector representations suitable for downstream classification, tagging, and span extraction.
During pre training, BERT is optimized with masked language modeling and next sentence prediction to learn language representations.
This combination enables effective transfer learning: a pre-trained model can be fine tuned on small supervised datasets to reach strong accuracy quickly.

BERT Model Architecture
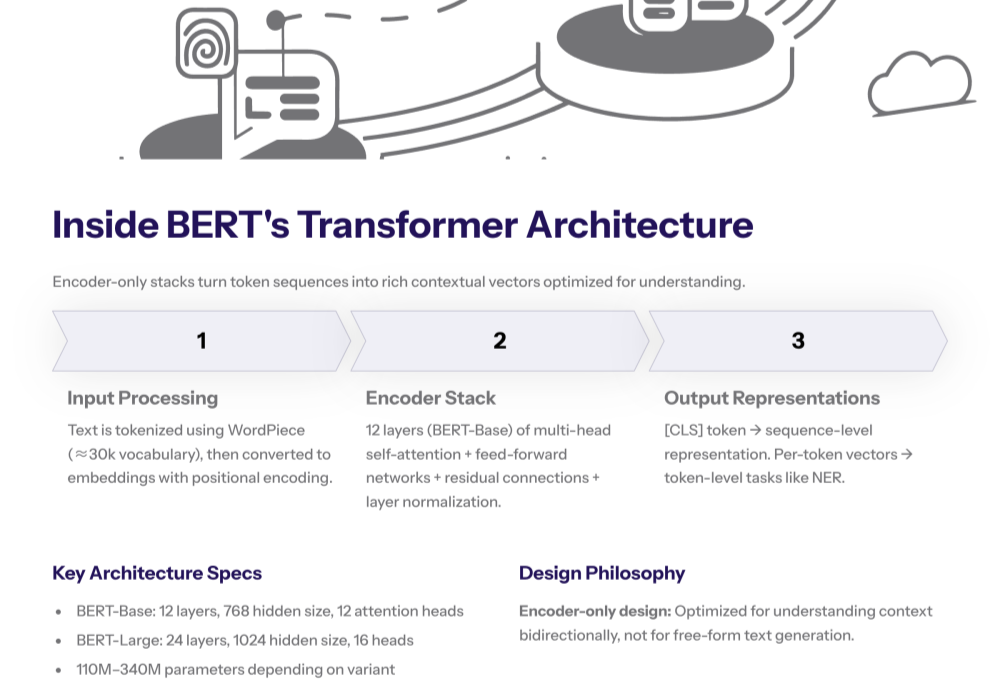
The transformer architecture underpins BERT.
It comprises an encoder stack of multi-head self attention blocks and feed-forward networks, layered with residual connections and normalization.
In its Base configuration, BERT uses 12 layers, hidden size 768, and 12 self-attention heads.
The WordPiece tokenizer maps input text into a 30,000 token vocabulary; each input token is converted into an embedding that is fed through the encoder.
After the stack, BERT outputs a 768-dimensional vector representation per token and a pooled [CLS] representation for sequence-level tasks.
This encoder-only design emphasizes language understanding over autoregressive generation.
How the BERT Language Model Learns?
BERT’s pre training objective is masked language modeling: randomly mask a subset of tokens and train the model to predict each masked token using the surrounding context.
Because the networks attend bidirectionally, the model gains deeper understanding of sentence structure and long-range dependencies.
BERT also trains with next sentence prediction to learn inter-sentence coherence signals useful for question answering and information retrieval.
These choices make BERT a powerful model for feature extraction, sequence tagging, and span-level prediction.

Language Modeling With BERT in Practice
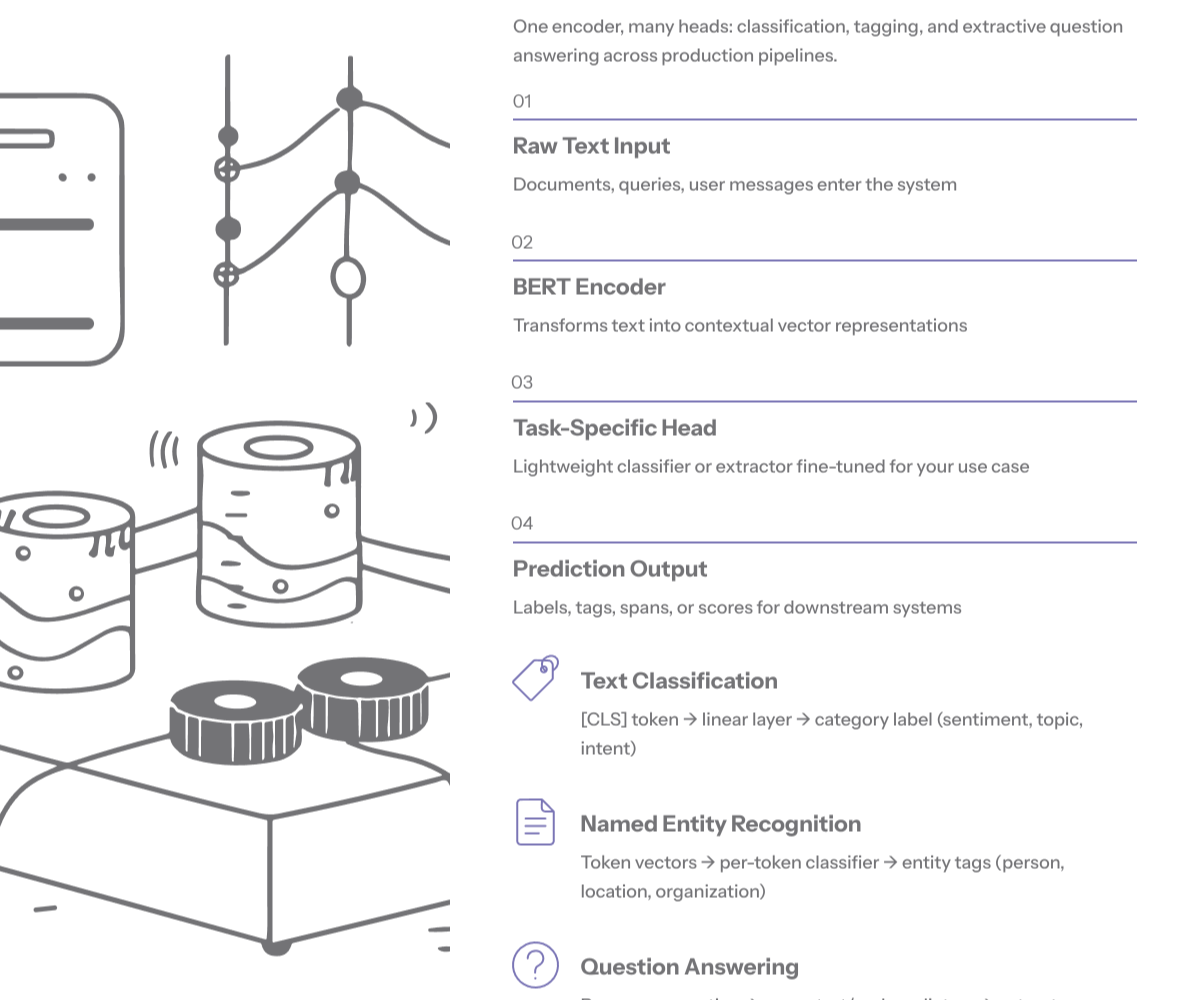
In practical pipelines, the bert model is used as a feature extractor whose contextual vectors feed task-specific heads.
For text classification, a classification layer is added on top of [CLS].
For named entity recognition, token-level classifiers use the per-token vector representation.
For question answering, start and end span predictors operate over contextual embeddings.
Fine tuning updates some or all model parameters on labeled data to adapt BERT to specific tasks and domains.
BERT vs. Large Language Models
Large language models (LLMs) broadly include any model trained on vast textual data, but industry usage has converged on decoder-style generators. For more information on deployment and selection, check out these local LLM tools for efficient model deployment.
These generative systems produce human-like text, follow instructions, and exhibit strong zero-shot learning via in-context prompts.
BERT is not designed to generate long free-form text; it excels at natural language understanding and representation learning.
Put differently: BERT is an LM but not a modern generative LLM intended to generate text conversationally.
This is why BERT shines on extraction and classification while GPT-style models dominate text generation.
Generative Pre-trained Transformer (GPT) in Contrast
The Generative Pre-trained Transformer family uses decoder-only architectures trained with causal language modeling—predicting the next word from left-to-right context.
Unlike masked language modeling, causal objectives force strict autoregression, which is ideal for text generation, summarization, and dialogue.
GPT models do not rely on next sentence prediction; they use massive corpora and scaling laws to learn a general policy for generating human like text.
Instruction tuning and reinforcement learning with human feedback then align the model to user intent, safety rules, and assistant-style conversation.
This pipeline explains why GPT models are strong at generating coherent and contextually relevant text for long outputs.
Where BERT Still Excels?
Despite the generative wave, BERT remains highly competitive for many natural language processing tasks.
Its bidirectional encoder can capture fine-grained dependencies that benefit sentence classification, sentiment analysis, named entity recognition, semantic search, and re-ranking.
For search engines and recommendation pipelines, BERT-derived embeddings serve as high-quality vector representations for retrieval and ranking.
In low-latency inference environments, compact BERT variants deliver excellent cost efficiency while maintaining accuracy.
When the goal is language understanding rather than text generation, BERT is often a simpler and more efficient fit.
Popular Language Models in Context
Popular large language models include BERT, RoBERTa (which refines pre training choices), and GPT series for generation.
Each architecture optimizes different trade-offs between understanding and generation.
Encoder models specialize in extracting meaning and structure from input text; decoder models specialize in producing fluent outputs; encoder–decoder hybrids balance both for tasks like machine translation.
Choosing among them depends on the specific tasks, latency targets, and data scale.
Natural Language Processing Tasks Suited to BERT
BERT performs strongly on text classification and sentiment analysis where contextual cues matter.
It is widely used for natural language processing tasks such as intent detection, topic labeling, toxicity classification, and stance detection.
In information extraction, BERT supports named entity recognition, relation extraction, and slot filling by leveraging token-level vector representation.
For question answering over passages, span predictors on top of BERT can identify precise answer spans with high fidelity.
Fine Tuning BERT for Specific Tasks
Fine tuning adapts a pre-trained model to a target dataset.
With BERT, practitioners commonly fine tune all layers for best performance on moderate datasets.
Layer-wise learning rate decay and careful batch size scheduling often stabilize training.
When data is limited, freezing lower layers and training a thin head can prevent overfitting.
Transfer learning enables strong accuracy with relatively small training data compared to training from scratch.
Training Data and Domain Adaptation
Model performance hinges on the relevance and quality of training data.
Domain-adaptive pre training—continuing masked language modeling on in-domain text—can reduce domain shift before task-specific fine tuning.
For specialized corpora such as financial documents or clinical notes, this step significantly improves language understanding of domain jargon and long-tail entities.
High-quality annotation, balanced classes, and consistent guidelines are essential for reliable evaluation.
Masked Language Modeling: Strengths and Limits
Masked language modeling enables deep bidirectional context and robust natural language understanding.
Because tokens are masked randomly, the model learns to use both left and right context for prediction.
However, the objective is not to produce long coherent passages, so generation quality from BERT without auxiliary decoders is limited.
For applications that must generate text paragraphs end-to-end, decoder-based language models remain preferable.
Next Sentence Prediction: What It Adds
The next sentence prediction head introduces a coarse signal for inter-sentence coherence, which is one of the fundamental techniques used in local large language models (LLMs).
Although subsequent research questioned its necessity, NSP originally helped for tasks like question answering and sentence-pair classification.
Replacing NSP with alternative objectives such as sentence order prediction or removing it entirely can sometimes yield comparable or better results, depending on the dataset.
Practitioners should validate these variants empirically rather than rely on defaults.
Tokenization and Input Representation
BERT uses WordPiece tokenization to split input text into subword units.
Subwords efficiently handle rare words and morphology while keeping sequences tractable.
Special tokens—[CLS], [SEP]—mark sequence boundaries and classification pooling points.
Position embeddings encode token order, and segment embeddings distinguish paired inputs for sentence-pair tasks.
The net effect is a rich input representation that the encoder can transform into contextual vectors.
Scaling Considerations and Model Size
BERT comes in sizes from Base to Large and beyond.
Larger configurations generally improve accuracy on many NLP tasks but require more memory, longer training time, and careful regularization.
When resources are constrained, distillation and pruning can compress models while preserving most of the accuracy.
Selecting the right model size depends on latency budgets, desired accuracy, and serving costs.
Language Translation and Encoder–Decoder Alternatives
While BERT can aid language translation via feature extraction and re-ranking, encoder–decoder architectures trained on translation objectives remain the standard for machine translation.
These hybrids attend to both source and target sequences, combining strong language understanding with fluent text generation.
If your use case is end-to-end translation, choose an encoder–decoder transformer rather than an encoder-only BERT model.
If you need semantic similarity or quality estimation, BERT-derived embeddings excel.
Sentiment Analysis and Text Classification
Sentiment analysis is a classic demonstration of BERT’s contextual understanding.
Because sentiment flips on negation and subtle cues, bidirectional context boosts accuracy.
For text classification, practitioners often pool [CLS] or mean-pool token vectors and add a linear softmax head.
Small learning rates, warmup schedules, and dropout help prevent overfitting, especially on compact datasets.
Question Answering With BERT
For extractive question answering, BERT maps context passages and questions into a single input, then predicts start and end positions for answer spans.
This allows precise grounding in the source text.
Accuracy improves with long context windows and careful truncation strategies that keep relevant evidence.
When answers must be generated beyond span boundaries, decoder models may be preferable, but for retrieval-style QA, BERT remains formidable.
Language Understanding vs. Language Generation
A useful mental model separates natural language understanding from language generation.
BERT focuses on understanding: building contextual vector representations that downstream heads can interpret.
Decoder LMs focus on generation: producing tokens left-to-right to generate human like text.
Both are language models in a broad sense, but their objectives, architectures, and deployment patterns diverge.
Choosing correctly shortens development time and improves reliability.
Transfer Learning and Few-Shot Behavior
BERT popularized transfer learning in NLP: pre-train once, then fine tune for specific tasks.
While decoder LLMs exhibit striking in-context few-shot learning, encoder models can also benefit from few examples through careful fine tuning schedules and prompt-based classification heads.
For resource-constrained environments, this approach achieves impressive accuracy without training very large models.
Training Process and Practical Tips
A stable training process requires disciplined engineering.
Use stratified splits to assess generalization, monitor validation loss and task metrics, and watch for data leakage.
Tune batch size and learning rate jointly; small changes can flip outcomes on compact datasets.
Log training curves, random seeds, and data versions so results are reproducible and explainable.
Evaluating BERT on NLP Tasks
Reliable evaluation mirrors real deployment.
Pair aggregate metrics with slice analysis across demographics, topics, and lengths.
For classification, report accuracy and macro F1; for named entity recognition, token-level F1; for question answering, exact match and F1 over spans.
Calibration and abstention are important when models drive user-facing decisions.
Limitations of BERT
BERT is not a strong free-form generator; without decoders it struggles to generate high-quality paragraphs.
It can be computationally expensive to train and fine tune at scale, especially for large variants.
On tasks requiring multi-step reasoning chains, planning, or tool use, generative LLMs aligned with human feedback often perform better.
Nevertheless, with the right head and training data, BERT offers dependable baselines for many natural language processing tasks.

When to Prefer BERT Over Generative LLMs
Prefer BERT when you need low-latency inference for classification or extraction, when your compute is limited, or when you want compact models that are easy to serve.
In search relevance, entity extraction, and semantic similarity, encoder models provide stable, cost-effective solutions.
Reserve generative LLMs for tasks that require long-form text, multi-turn conversation, or tool-mediated reasoning and text generation.

Fine Tuning BERT Efficiently
To fine tune effectively, start with a low learning rate, apply warmup and decay, and consider gradient clipping for stability.
Adjust batch size to hardware while preserving generalization.
Early stopping on validation metrics helps avoid overfitting.
If data is scarce, leverage data augmentation, weak supervision, or synthetic examples checked by human reviewers.
Handling Textual Data at Scale
Curating textual data at scale demands quality checks: language ID, deduplication, profanity filters, and metadata validation.
Keep annotation guidelines consistent and measure inter-annotator agreement to maintain label quality.
For multilingual tasks, ensure representation across languages, scripts, and domains.
Good data makes fine tuning faster, cheaper, and more reliable.
Contextual Understanding and Vector Representations
Because BERT produces contextual vectors, the same word can have different embeddings depending on context.
This property enables deeper understanding of polysemy and idioms.
Downstream systems leverage these vectors for clustering, semantic search, and knowledge graph population.
Vector representation is the bridge between language understanding and actionable features.
Beyond BERT: RoBERTa, DistilBERT, and More
RoBERTa modifies training dynamics—more data, longer training, and dropped NSP—to improve results.
DistilBERT compresses models through distillation to lower latency.
ALBERT reduces parameters via factorization and parameter sharing, improving efficiency for similar accuracy.
These popular language models demonstrate that encoder families continue to evolve alongside generative systems.
Integrating BERT Into Production
Productionizing a bert model involves choosing serving frameworks, quantizing weights, and building monitoring.
Track latency, throughput, accuracy by slice, and drift in input distributions.
When used in ranking, regularly refresh embeddings; when used in classification, schedule periodic re-training as data shifts.
Tie these operations to business metrics so improvements translate into measurable value.
Answering the Core Question
Is BERT an LLM? In the broad, literal sense—yes, BERT is a language model trained on large text corpora.
In current industry usage, however, LLM usually denotes generative, decoder-based systems for dialogue and long-form text.
By that definition, BERT is not an LLM; it is a bidirectional encoder specialized for understanding.
This distinction matters because it guides architecture selection, data strategy, and performance expectations.
Taxonomy: Defining “LLM” Precisely
The phrase large language model is used inconsistently in both academic papers and industry blog posts.
One definition counts any model with hundreds of millions or billions of parameters trained on massive textual data as an LLM.
Under that broad umbrella, the BERT language model would qualify whenever its parameter count crosses an informal threshold.
A narrower, product-centric definition equates LLMs with instruction-following, chat-ready systems that generate long form text.
By the narrower definition, encoder-only models like BERT are not considered LLMs, because they are not optimized to generate text.
Clarity about definitions prevents talking past each other when teams plan architectures for specific tasks.
Pre-Trained Models and Transfer Learning
BERT popularized a powerful pattern: pre-trained models serve as initialization for a variety of downstream tasks.
Developers rarely train encoders from scratch because transfer learning is so effective.
A typical workflow downloads a pre trained model checkpoint, attaches a small head, and runs a short fine tuning schedule.
This approach leverages the heavy investment in general language representations and reduces dependence on giant labeled datasets.
It also speeds iteration dramatically, turning weeks of data collection into days of model prototyping.
How Does the BERT Model Work Internally?
At a high level, input text is tokenized, embedded, and passed through layers of self attention mechanisms.
Each layer updates token vectors by attending to other positions, enabling long-range context sharing.
Residual connections and layer normalization stabilize gradients and encourage deeper networks.
A task head maps the final vector representation to logits for classification, span start and end indices, or similarity scores.
In effect, BERT converts natural language into dense, task-ready features that are easy to train with small supervised datasets.
Masked Language Modeling Task Details
The masked language modeling task randomly replaces a percentage of input token positions with a mask token.
The model predicts the original token at each masked position using bidirectional context.
In practice, not all replacements are the actual mask token; some are kept or substituted with random tokens to reduce mismatch between pre training and fine tuning.
This subtlety improves robustness during the training process and yields better generalization in downstream tasks.
The objective does not require sequential generation and therefore suits encoders that process the entire sequence at once.
Fine-Tuning Setup: Practical Hyperparameters
When practitioners fine tune BERT, they typically choose small learning rates and moderate batch sizes.
Warmup over the first few hundred or thousand steps helps stabilize optimization, followed by linear or cosine decay.
Gradient clipping prevents exploding gradients on noisy datasets.
Early stopping based on validation loss or F1 avoids overfitting, which can happen quickly on compact corpora.
Layer-wise learning rate decay—smaller rates for lower layers, larger for upper layers—often yields small but meaningful gains.
Language Translation and Cross-Lingual Transfer
Multilingual variants such as mBERT extend the encoder approach to many languages.
They learn cross-lingual alignment so that similar meanings map to similar vector spaces across languages.
This enables zero-shot transfer for text classification and named entity recognition in new languages with few examples.
For machine translation itself, encoder–decoder models trained on parallel corpora remain the best choice because they directly optimize text generation.
Nevertheless, mBERT is invaluable for cross-lingual retrieval, clustering, and sentiment analysis of social media posts.
Natural Language Understanding vs. Generation
Natural language understanding (NLU) places emphasis on extracting structure, semantics, and intent from inputs.
Language generation focuses on producing fluent, coherent outputs in response to prompts.
BERT is squarely an NLU workhorse; generative pre trained transformer systems are specialists at producing long sequences.
This division of labor suggests hybrid systems: encoders for retrieval and classification, decoders for drafting responses.
Such systems combine strengths while controlling cost and risk.
Common Misconceptions
A common misconception is that GPT models are trained with masked language modeling like BERT; in reality they use left-to-right causal objectives.
Another misconception is that encoders cannot scale; in truth, they scale well, but their inference pattern differs from decoders.
A third misconception is that BERT cannot be used for generation at all; while not its design goal, BERT can support generation via additional decoders or masked-to-sequence techniques, though quality lags behind causal decoders.
Clarifying these points prevents architecture mismatches and wasted iteration time.
Precise language about objectives and outputs pays dividends during design reviews.
Practical Case Study: Customer Support Triage
Consider a global enterprise that needs to triage incoming tickets written in multiple languages.
Latency is critical and the majority of decisions are categorical.
A distilled BERT variant fine tuned on labeled tickets yields accurate routing at a fraction of the serving cost of giant generators.
For escalations that require long replies, the system can hand off to a generative model with retrieval to draft responses.
This layered approach delivers end-user quality while maintaining operational efficiency.
Practical Case Study: Search and Recommendation
In search systems, encoders compute embeddings for queries and documents, enabling nearest-neighbor retrieval in vector space.
A cross-encoder BERT model can then re-rank the top candidates by scoring pairwise relevance using full attention between query and document tokens.
This two-stage pipeline outperforms bag-of-words baselines and scales to millions of items.
When paired with behavioral feedback loops, relevance steadily improves without changing core architecture.
Such designs highlight why encoders remain foundational in search engines.
Responsible Use and Dataset Considerations
Modern language systems inherit biases present in textual data.
Auditing datasets for representation and conducting fairness evaluations by cohort are critical.
For sensitive applications, include guardrails and human review, even when models appear highly accurate.
Encoder models like BERT simplify some safety controls because they do not free-generate long passages, but they can still amplify bias in classification settings.
Responsible deployment requires continuous monitoring and periodic refresh of training data.
Integration Patterns With Generative Systems
Many production stacks combine encoders and decoders.
Encoders filter, categorize, and retrieve; decoders draft text conditioned on retrieved evidence.
This pattern keeps generation grounded in verifiable sources and improves factuality.
It also provides levers for governance because the retrieval corpus can be audited and versioned.
As budgets tighten, such hybrid designs balance capability and cost.
Final Verdict
Is BERT an LLM? At parameter scale and by the dictionary definition of a language model trained on large corpora, yes.
By the prevailing usage that equates LLMs with instruction-following, chat-centric generators, no.
The safest summary is: BERT is a powerful encoder language model for natural language understanding; GPT-style models are powerful generators for natural language production.
Selecting between them—or using both—should follow from your task, latency needs, safety posture, and data availability.
Understanding these distinctions is the first step toward building reliable natural language systems.