
What Are the Best Enterprise Edge Platforms for Running AI ML Inference Models?
In today's fast-evolving AI landscape, enterprises are increasingly relying on robust platforms to run AI and machine learning inference models efficiently at the edge. With the surge in demand for real-time insights, low latency, and enhanced data privacy, selecting the right enterprise edge platform has become critical.
These platforms support a wide range of AI workloads, including natural language processing (NLP), computer vision, and recommendation systems, enabling organizations to deploy scalable, high-performance machine learning models in production environments.
Leveraging advanced GPU infrastructure, multi-GPU setups, and seamless integration with cloud services, the best platforms empower data scientists to accelerate model training, fine-tuning, and deployment while maintaining enterprise-grade security and lifecycle management.
Key Takeaways
Enterprise edge platforms provide essential capabilities such as multi-GPU support, distributed computing, and seamless cloud integration, enabling scalable and efficient AI inference for diverse workloads including NLP.
Deploying AI models at the edge offers significant benefits like reduced latency, enhanced data privacy, cost savings, and improved reliability, making it ideal for mission-critical production environments.
Leading platforms like Google Cloud AI Platform (Vertex AI), Microsoft Azure Machine Learning, and NVIDIA DGX Cloud offer comprehensive solutions with features such as experiment tracking, model versioning, and support for popular ML frameworks, helping enterprises streamline their entire machine learning workflows.

Introduction to Enterprise Edge Platforms
The rise of enterprise AI has redefined how organizations think about infrastructure. No longer confined to research labs or experimental prototypes, machine learning models are now embedded in everyday business applications — from fraud detection to medical imaging, from supply chain forecasting to voice assistants. The challenge lies in moving these models out of the sandbox and into production environments where they must deliver optimal performance at scale.
This is where enterprise edge platforms step in. They serve as the backbone of modern AI deployment, providing the compute power, integration capabilities, and enterprise-grade features that make it possible for organizations to run AI inference workloads reliably. Unlike consumer-grade edge solutions, enterprise edge platforms are designed to handle complex AI workloads with requirements for multi-GPU support, distributed computing capabilities, and tight integration with cloud services.
The entire ML workflow — from data preparation to custom model training, model serving, and lifecycle management — can be orchestrated using these platforms. This end-to-end approach not only simplifies machine learning workflows but also allows data scientists and engineers to prioritize platforms based on workload type, compliance needs, and budget considerations.
Some of the most recognized enterprise edge solutions today include:
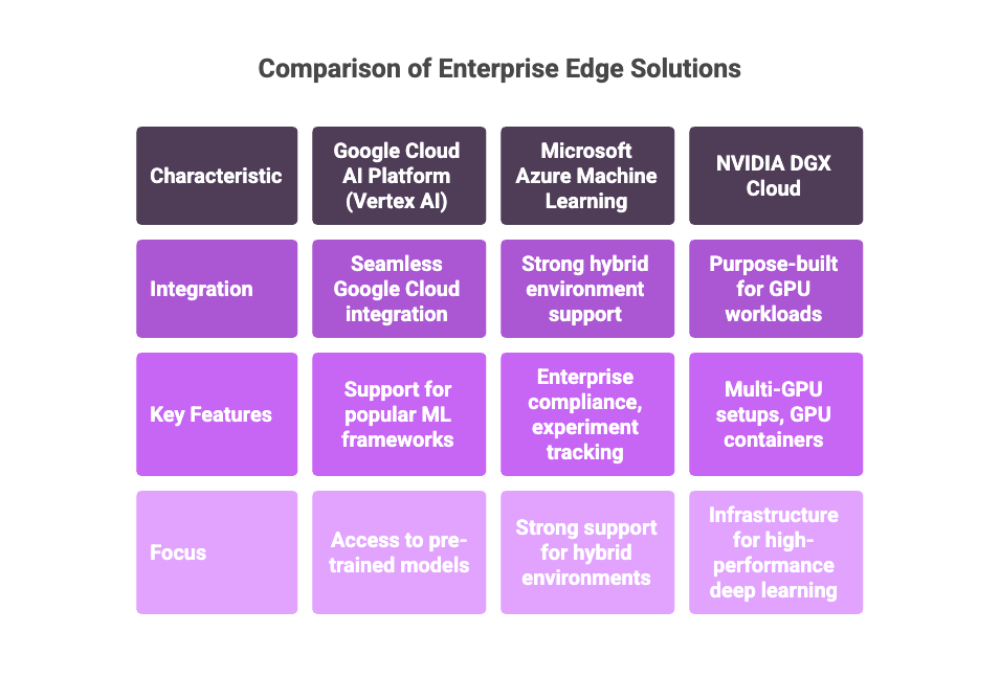
Google Cloud AI Platform (Vertex AI): Known for seamless integration with Google Cloud services, support for popular ML frameworks, and access to pre-trained models.
Microsoft Azure Machine Learning: Offers strong support for hybrid environments, enterprise compliance, and experiment tracking.
NVIDIA DGX Cloud: Purpose-built for GPU workloads, offering unmatched multi-GPU setups, GPU containers, and infrastructure for high-performance deep learning.
As we explore these platforms, the central question remains: which one is the best enterprise edge platform for running AI inference and machine learning models in your specific context?
Benefits of Edge Deployments
The move toward edge AI isn’t just a technical preference — it’s a response to business realities. While the cloud-based platform model remains important, many enterprises are discovering the unique advantages of deploying models closer to where data is generated.
1. Reduced Latency and Real-Time Decisions
Latency can be a dealbreaker in AI systems. In fields such as autonomous vehicles, industrial robotics, and financial trading, a delay of even a few milliseconds can mean lost opportunities or safety risks. Edge deployments allow ML models to run locally, ensuring optimal performance in real time.
Example: A hospital monitoring system that analyzes patient vitals every second cannot afford cloud roundtrips. By using edge AI, inference happens directly on the hospital network, reducing delays that could otherwise impact patient care.
2. Stronger Data Privacy and Security
Industries like finance, defense, and healthcare are bound by strict compliance requirements (HIPAA, GDPR, etc.). Transmitting sensitive data to the cloud for inference exposes organizations to legal and security risks. Running machine learning models at the edge keeps sensitive information local, providing enterprise-grade features such as version control, management capabilities, and lifecycle management without compromising data integrity.
3. Cost Savings Through Localized Processing
Cloud infrastructure costs add up quickly. Each gigabyte transferred or stored incurs charges, making large-scale ML projects financially challenging. By deploying models at the edge, organizations minimize cloud dependence, reducing both GPU access costs and recurring pricing models tied to cloud compute.
4. Greater Reliability in Production Environments
Cloud outages, though rare, do happen. Edge deployments reduce reliance on external providers by ensuring that AI inference can continue even if connectivity drops. For mission-critical systems in logistics or energy, this reliability is non-negotiable.
Taken together, these benefits explain why enterprises increasingly look to edge AI solutions as the foundation of their long-term AI deployment strategies.

Core Features of Enterprise Edge Platforms
Not all enterprise edge platforms are created equal. What separates leaders from laggards are the core features that directly influence how effectively organizations can run AI workloads at scale.
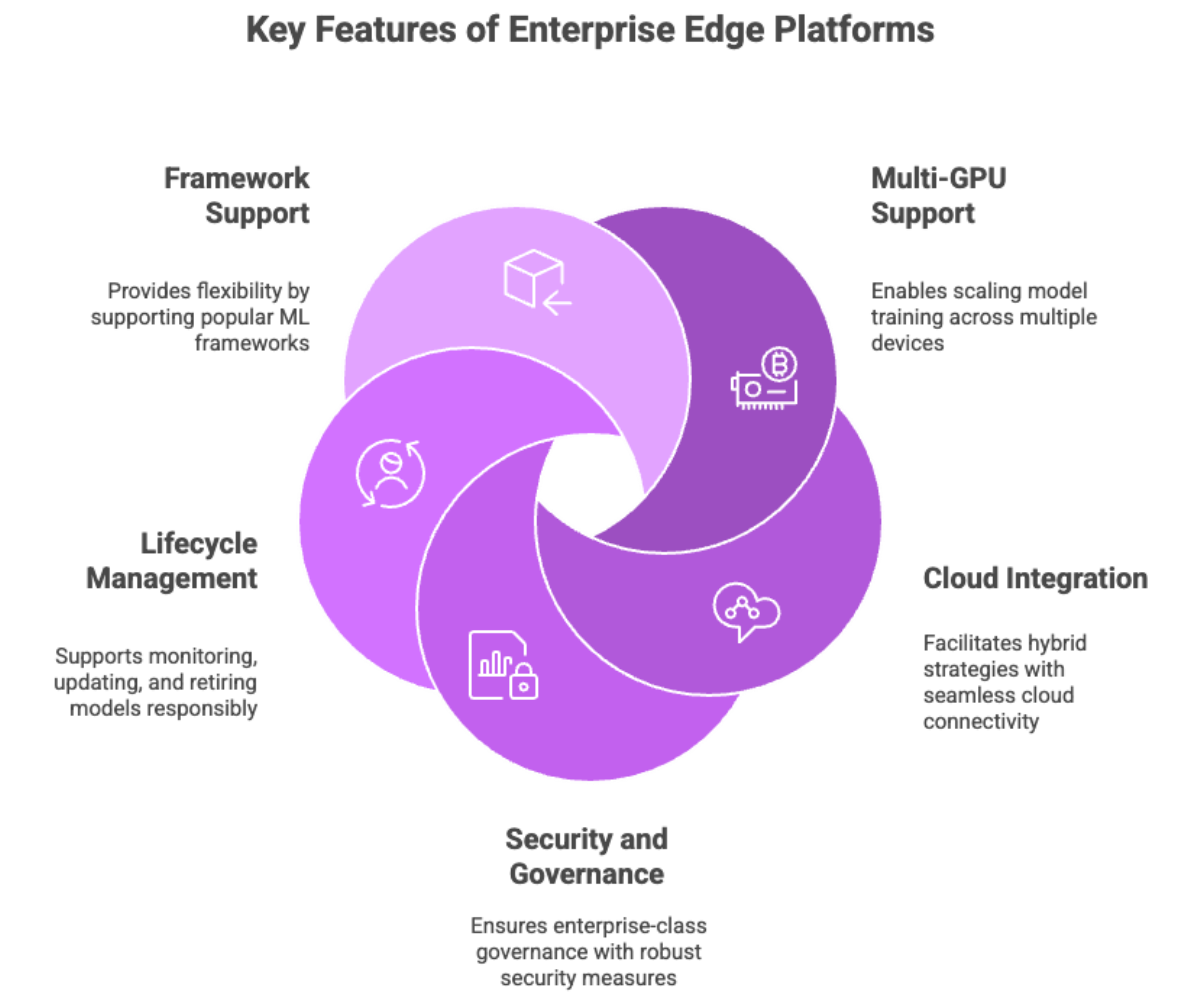
Multi-GPU Support and Distributed Computing
For training and deploying ML models, a single GPU is rarely enough. Multi-GPU setups allow data scientists to scale model training across multiple devices, while distributed computing capabilities extend this further across clusters. Platforms like NVIDIA DGX Cloud specialize in this, offering GPU containers optimized for HPC workloads and GPU accelerated workloads.
Seamless Integration with Cloud Services
The best platforms don’t just run locally; they connect seamlessly to cloud services. This enables hybrid strategies where some tasks (like custom model training) happen in the cloud, while others (like model serving) run at the edge. Vertex AI is a prime example, designed with seamless integration into the Google Cloud ecosystem, enabling access to other Google Cloud services without friction.
Robust Security and Version Control
AI in production environments requires enterprise-class governance. That means strong version control for model deployment, role-based access, and compliance checks baked into the platform. Microsoft Azure Machine Learning excels here, offering enterprise-grade features that align with global compliance frameworks.
Lifecycle Management and Experiment Tracking
Building models is only part of the journey; maintaining them over time is equally important. Lifecycle management ensures that models can be monitored, updated, and retired responsibly. Features like experiment tracking and model versioning help teams keep track of changes, making it easier to compare iterations and replicate successful outcomes.
Support for Popular ML Frameworks
Finally, flexibility matters. The best enterprise edge platforms support popular ML frameworks such as TensorFlow, PyTorch, MXNet, and Scikit-learn. This ensures data scientists can bring their existing machine learning workflows into production without hitting compatibility barriers.
In short, the core features of a platform determine whether it can truly support the entire ML workflow and deliver optimal performance in enterprise use cases.
Cloud GPU Providers
When it comes to enterprise AI, the availability of GPU infrastructure often determines whether a project thrives or stalls. Training and deploying ML models require massive compute, especially for machine learning models involving natural language processing, computer vision, or recommendation engines. That’s why choosing the right GPU cloud provider is critical.
Why Cloud GPUs Matter?
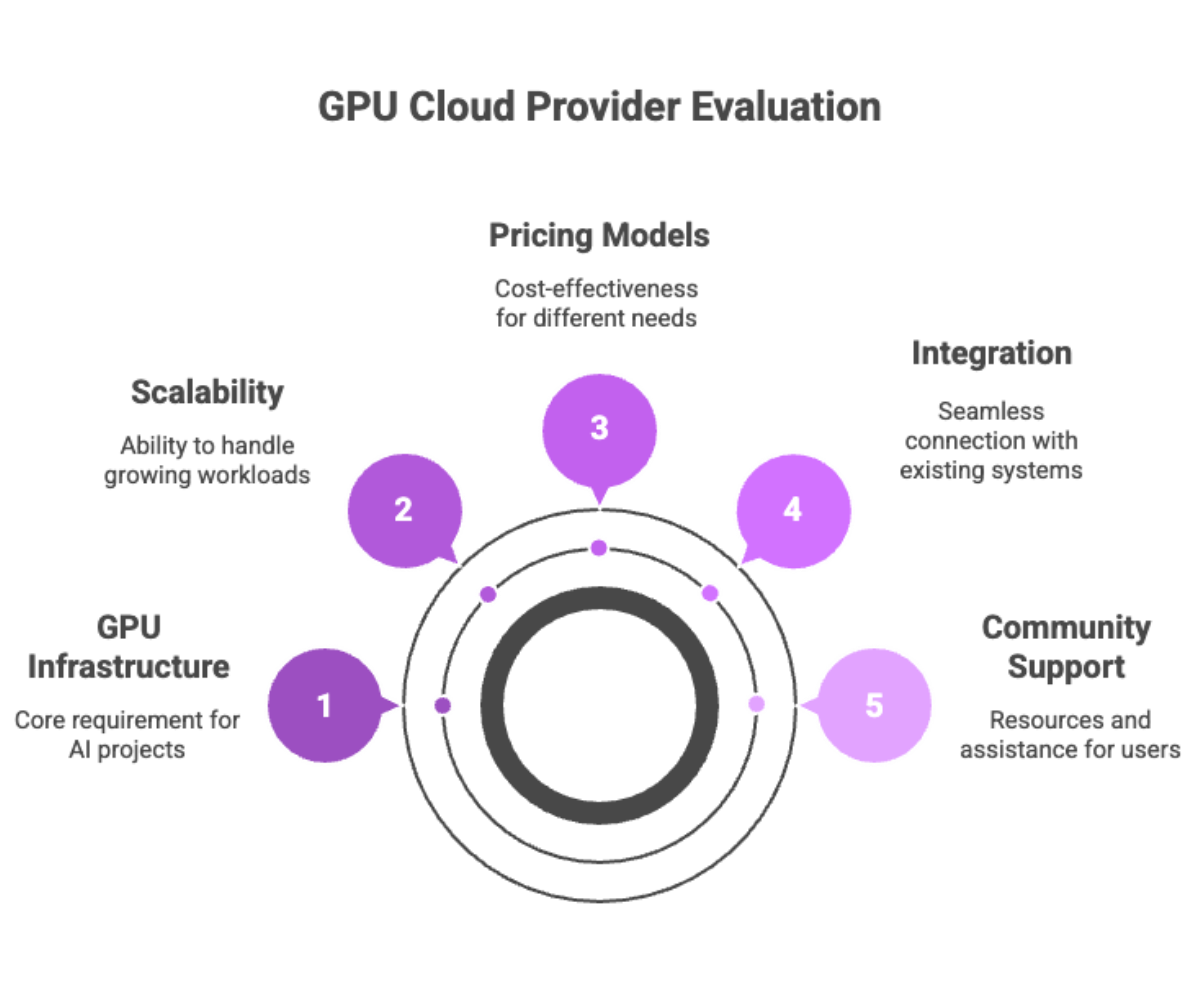
Traditional on-premises clusters offer control but come with high upfront costs and limited scalability. In contrast, a GPU cloud platform allows enterprises to spin up powerful multi-GPU setups on demand, providing access to the latest provider GPU types like the NVIDIA H100 without waiting for procurement cycles.
Key benefits include:
Scalable infrastructure: Instant access to clusters capable of handling HPC workloads.
GPU access on demand: No need to over-provision hardware.
Flexible billing models: Pay-as-you-go or reserved capacity depending on project needs.
Community support: Large ecosystems of tutorials, prebuilt GPU containers, and integrations reduce the steep learning curve.
Top GPU Cloud Providers
NVIDIA DGX Cloud
Purpose-built for AI, DGX Cloud combines GPU accelerated workloads with enterprise-ready orchestration. It offers multi-GPU support, specialized software stacks, and enterprise-grade features like secure networking and compliance monitoring. For enterprises focused on high performance, DGX is often the go-to.
Google Cloud (Vertex AI)
Google has transformed Vertex AI into a powerhouse for machine learning workflows. Beyond pre-trained models and custom model training, Google Cloud provides seamless access to other Google Cloud services, making it easy to integrate with existing infrastructure. Its GPU cloud platform offerings scale from single GPUs to distributed computing capabilities, perfect for both data science experiments and AI deployment in production.
Microsoft Azure Machine Learning
A leader in enterprise, Azure offers one of the most flexible cloud GPU environments. It supports hybrid environments, strong version control, and integrations with enterprise apps like PowerBI and Dynamics. Its pricing models are competitive, and its community support is vast.
When evaluating a GPU cloud provider, organizations should focus on pricing models, availability of GPU resources, and ease of integration with AI deployment strategies.
AI Inference Platforms
Running AI models in production requires specialized infrastructure for model serving. This is where AI inference platforms step in, translating ML models into services that real-world applications can consume reliably.
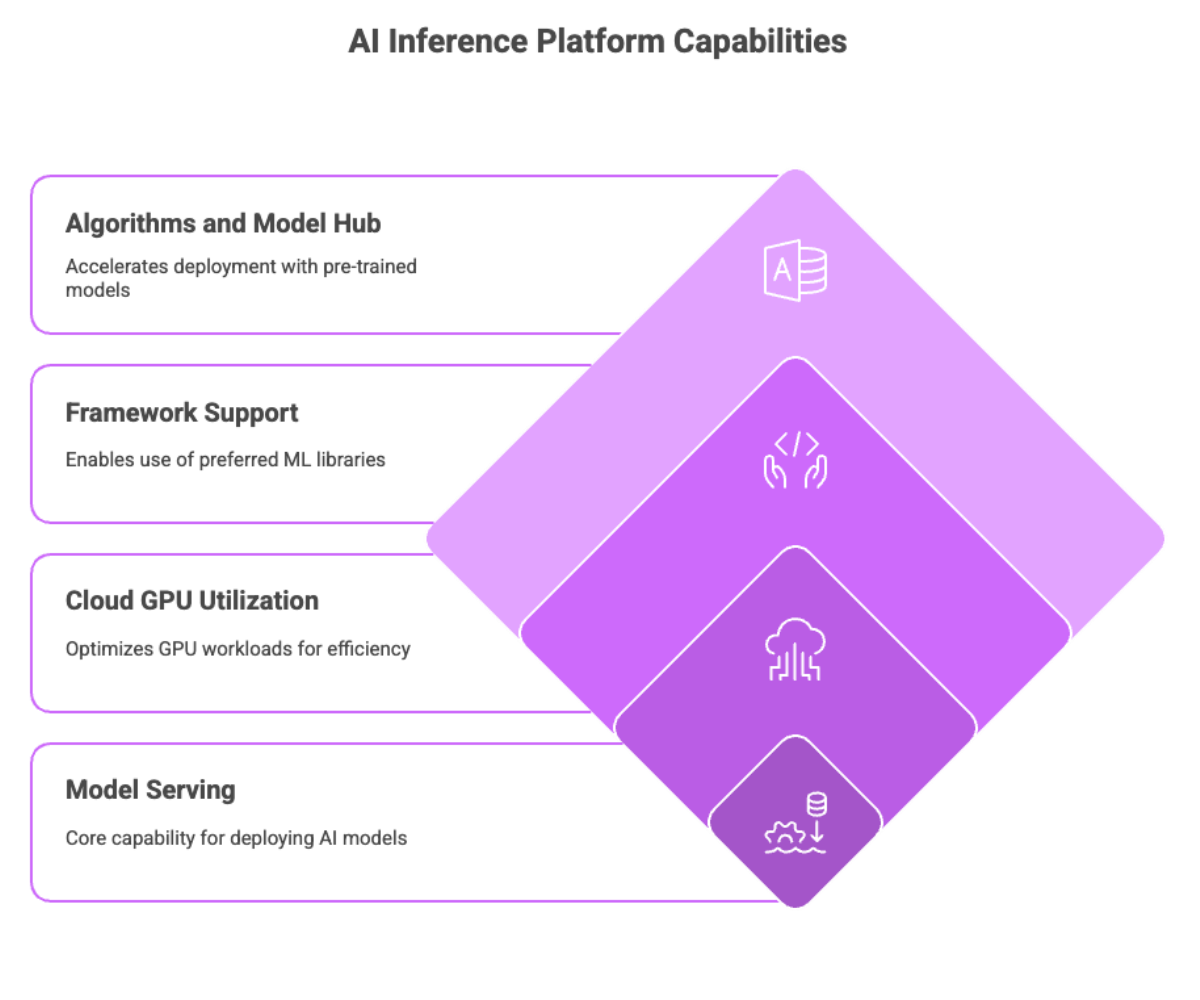
Core Capabilities
Model serving at scale: Handle thousands of concurrent requests.
Cloud GPU utilization: Optimize GPU workloads to ensure efficiency.
Support for popular ML frameworks: So teams can use their preferred libraries.
Built-in algorithms and model hub: Access to pre-trained models that accelerate deployment.
Popular AI Inference Platforms
TensorFlow Serving: Open-source, widely adopted for deploying models into scalable production pipelines.
AWS SageMaker: More than just inference — it offers data labeling, fine-tuning, and full model lifecycle management.
Azure Machine Learning: Strong in AI deployment for hybrid environments, with tools for experiment tracking and compliance.
These platforms are not just about speed; they’re about reliability. Enterprises need model serving that guarantees uptime, security, and optimal performance, particularly in industries where downtime is costly.
Edge AI and Hardware Optimization
Deploying machine learning models at the edge introduces unique challenges. Unlike cloud-based setups with virtually unlimited compute, edge devices face constraints around GPU resources, memory, and power.
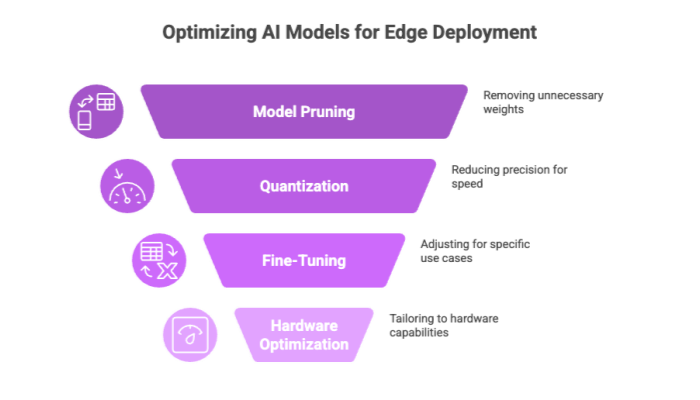
Techniques for Optimization
Model pruning: Removing unnecessary weights for lighter AI models.
Quantization: Reducing precision to make models smaller and faster.
Fine-tuning: Adjusting pre-trained models for specific edge use cases.
Hardware-Specific Considerations
GPU workloads: Some edge devices support discrete GPUs, while others rely on NPUs or optimized CPUs.
Compute resources: Platforms like NVIDIA DGX Cloud offer toolchains that prepare models for deployment on constrained devices.
Support for natural language processing and computer vision: Common AI workloads that require careful hardware optimization.
In practice, edge AI is about finding the sweet spot between accuracy, latency, and cost. Platforms like Google Cloud (Vertex AI) provide automation to help data scientists shrink and deploy models efficiently across diverse hardware.
Deploying ML Models
The path from experiment to production isn’t straightforward. Successful deploying ML models requires enterprise platforms with core features that support the full lifecycle, including efficient model deployment.
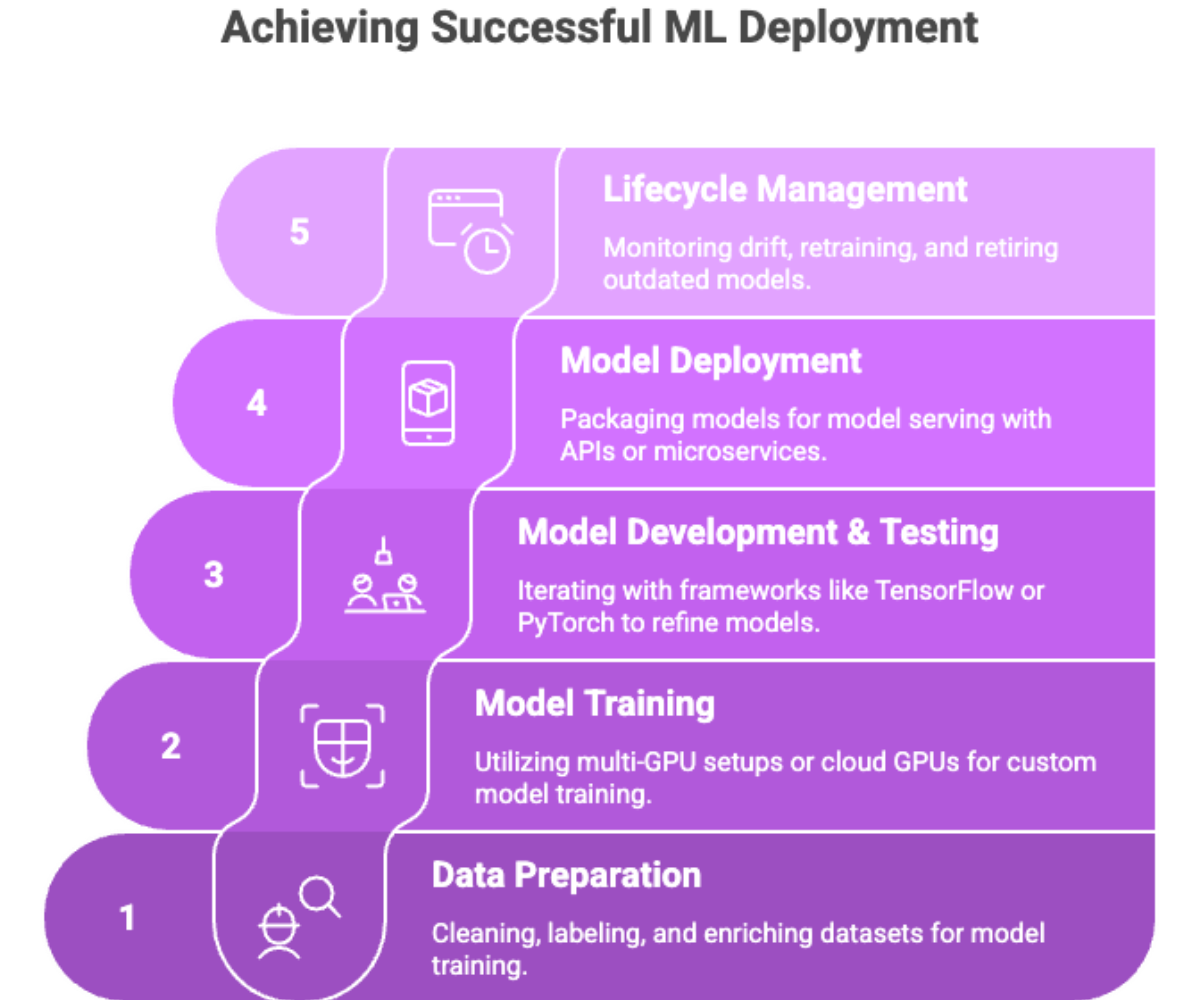
Stages of Deployment
Data preparation: Cleaning, labeling, and enriching datasets.
Model training: Using multi-GPU setups or cloud GPUs for custom model training.
Model development and testing: Iterating with frameworks like TensorFlow or PyTorch.
Model deployment: Packaging models for model serving with APIs or microservices.
Lifecycle management: Monitoring drift, retraining, and retiring outdated models.
Without strong management capabilities and experiment tracking, organizations risk steep learning curves and wasted compute. That’s why enterprise edge platforms like Microsoft Azure Machine Learning are increasingly favored: they make deploying ML models less about logistics and more about innovation.
AI Deployment Strategies
No two enterprises deploy AI the same way. AI deployment strategies must be tailored to organizational needs, compliance requirements, and AI workloads.
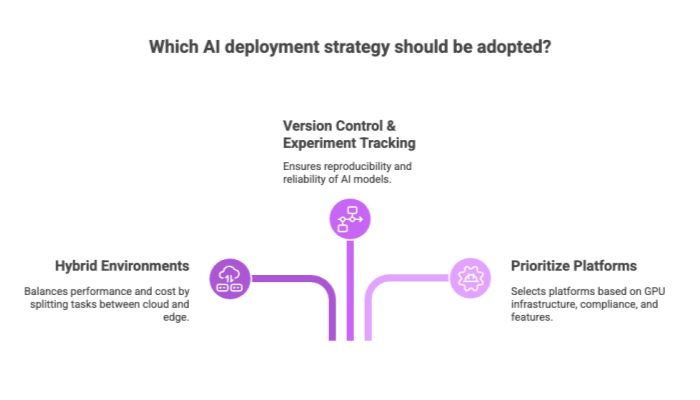
Common Strategies
Hybrid environments: Split tasks between cloud services and edge for performance and cost balance.
Version control and experiment tracking: Essential for reproducibility.
Prioritize platforms: Choose based on GPU infrastructure, compliance, and available enterprise-grade features.
Real-World Example
A financial firm might run model training in the cloud (where GPU access is abundant) but move AI inference to edge servers in data centers for low latency. This hybrid strategy maximizes optimal performance while minimizing costs.
Data Science and Experiment Tracking
Behind every production-ready model are dozens — sometimes hundreds — of experiments. Without experiment tracking, teams lose critical insights.
Key Features
Experiment tracking dashboards: Monitor accuracy, loss, and resource usage.
Model versioning: Keep track of different iterations of ML models.
Data labeling integration: Ensures clean datasets fuel experiments.
Platforms like high tech platforms such as Vertex AI and NVIDIA DGX Cloud shine here, enabling data scientists to streamline workflows across large ML projects while maintaining audit trails for compliance.
Enterprise Edge Platform Comparison
With so many options, comparing platforms requires clear criteria.
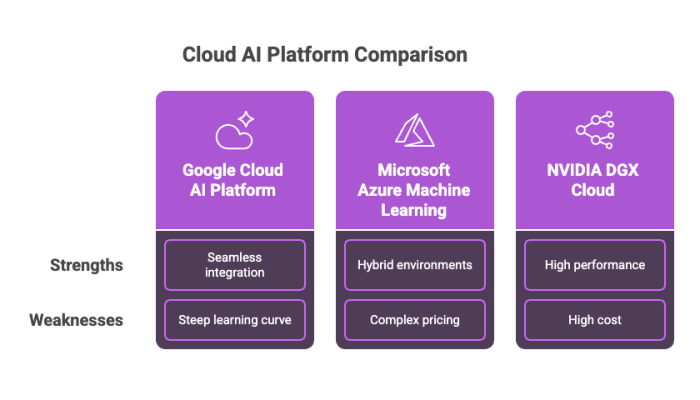
Google Cloud AI Platform (Vertex AI)
Strengths: Tight seamless integration with Google Cloud services, vast pre-trained models, strong community support.
Weaknesses: Can have a steep learning curve for beginners.
Microsoft Azure Machine Learning
Strengths: Best for hybrid environments, strong compliance, excellent experiment tracking.
Weaknesses: Pricing can be complex.
NVIDIA DGX Cloud
Strengths: Purpose-built for high performance, GPU infrastructure, and multi-GPU setups.
Weaknesses: Often more expensive than general-purpose cloud GPU providers.
Enterprises must weigh pricing models, community support, and workload fit to make the right choice.
Conclusion
Enterprise edge platforms are at the core of modern AI deployment strategies. They combine GPU infrastructure, cloud services, and enterprise-grade features like lifecycle management, version control, and experiment tracking to ensure models move seamlessly from lab to production.
By leveraging GPU cloud providers like NVIDIA DGX Cloud, Google Cloud (Vertex AI), and Microsoft Azure Machine Learning, organizations gain access to pre-trained models, scalable GPU workloads, and the ability to deploy ML models in ways that balance cost, performance, and compliance.
As enterprise AI continues to grow, the ability to prioritize platforms based on use case will be a key differentiator. Companies that master AI deployment strategies now will not only achieve optimal performance but also stay ahead in an increasingly competitive, data-driven economy.

