
Understanding Temperature in Large Language Models
Temperature is a crucial sampling parameter in large language models (LLMs) that governs how conservative or adventurous the model is when it chooses the next token.
In practical terms, temperature reshapes the probability distribution over candidate next words: lower temperature settings make the distribution sharper (more deterministic), while higher temperature values flatten it (more diverse and unpredictable). Tuning LLM temperature is one of the fastest levers for controlling tone, creativity, and risk in llm output—and it’s essential for fine-tuning the user experience to a desired outcome.
This guide explains how temperature works mathematically, how different temperature settings affect behavior, and how to choose, test, and combine temperature with other decoding controls (e.g., nucleus sampling, frequency/presence penalties) to optimize LLM output across tasks.


How Temperature Works?
Modern LLMs predict a probability distribution over the vocabulary by passing logits z (raw scores) through the softmax function:
p_i = \frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)}
Here, T is the temperature parameter:
-
Low temperature T<1: divides logits by a small number → larger gaps between alternatives → distribution becomes sharper → the model tends to choose the most probable word (more deterministic outputs).
-
High temperature T>1: divides logits by a larger number → gaps shrink → distribution flattens → the model is more likely to sample less probable tokens (more creative outputs).
A convenient intuition: temperature adjustments are a knob for how “bold” the sampler is. The same base logits can yield very different generated text depending on the numerical value of T.

Temperature, Training Data, and Input Context
Even with identical temperature settings, output quality is bounded by training data and input context. Clean, domain-matched corpora calibrate the logits the model generates, so when you apply a lower temperature value the softmax distribution already reflects the right priors.
Conversely, if the prompt omits key constraints, model performance degrades at any temperature: the model’s response will mirror uncertainty in the context more than your sampling choice. In short, temperature modulates variability around what the network learned; machine learning fundamentals—data coverage and conditioning—still dominate the generated output.
Interpreting Temperature at the Token Level
Mathematically, dividing logits by T makes the softmax distribution sharper as T\!\downarrow and flatter as T\!\uparrow. At small temperature values, the sampler will assign high probabilities to the top candidates, so the model selects high-likelihood tokens and yields concise responses.
As temperature increases, probability mass diffuses to the tail; the model generates longer, exploratory continuations. This mechanism explains why low T yields consistent responses, while high T yields more diverse outputs.
Effects of Low Temperature
With low temperature (e.g., 0.0–0.2):
-
The sampler concentrates probability mass on the top candidates, producing deterministic outputs (especially at T=0, where decoding often reduces to greedy).
-
Pros: precise, concise, stable wording; excellent for tasks requiring precision (e.g., policy-constrained answers, SQL generation, technical documentation).
-
Cons: lower diversity, higher risk of repetitive phrasing; may miss nuanced alternatives or hedging where appropriate.
When to use: structured extraction, schema-bound outputs, unit tests, exact paraphrases, or when you need consistent expected output across runs.

Effects of High Temperature
With high temperature (e.g., 0.8–1.2+):
-
Sampling explores the tail of the distribution, selecting more unusual continuations and yielding diverse responses and creative outputs.
-
Pros: more surprising ideas, varied style and wording; great for creative tasks (brainstorming, fiction, ad copy ideation).
-
Cons: increased risk of drift, contradictions, or reduced factual accuracy; coherence may drop with higher temperature values.
When to use: ideation, alternate phrasings, character voices, brand tone exploration, and speculative drafts.

Medium Temperature and Its Applications
Medium temperature (e.g., 0.4–0.7) aims for a balance:
-
Responses remain engaging and coherent, yet still exhibit variety.
-
A good default for conversational agents, content suggestions, and chatbots that must remain useful without sounding robotic.
When to use: interactive Q&A, general language models for support, and content generation where both accuracy and personality matter.

When a Moderate Temperature Works Best?
A moderate temperature (≈0.4–0.7) is often the pragmatic default for assistants: the LLM generates slightly more variety than greedy decoding while staying grounded in the prompt. You’ll see outputs that are moderately correlated with the top-1 continuation—close enough for reliability, but with alternative wording and examples that keep text engaging. Use this band when you need balanced tone, light creativity, and predictable structure in the generated output.
Comparing Outputs (Qualitative Patterns)
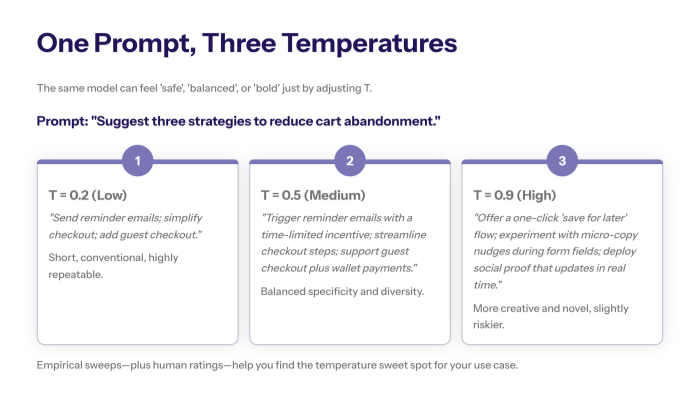
Consider the prompt: “Suggest three strategies to reduce cart abandonment.”
-
T = 0.2 (low temperature)
“Send reminder emails; simplify checkout; add guest checkout.”
Short, conventional, highly repeatable.
-
T = 0.5 (medium temperature)
“Trigger reminder emails with a time-limited incentive; streamline checkout steps; support guest checkout plus wallet payments.”
Balanced specificity and diversity.
-
T = 0.9 (high temperature)
“Offer a one-click ‘save for later’ flow; experiment with micro-copy nudges during form fields; deploy social proof that updates in real time.”
Novel, more creative, potentially riskier.
An empirical analysis of different temperature settings—collecting human ratings for usefulness, novelty, and correctness—often reveals a task-specific sweet spot.

The Role of the “Creativity” Parameter (and Friends)
Some SDKs expose a creativity parameter that maps to temperature; others expose temperature directly. In virtually all cases, higher “creativity” ≈ increasing temperature. Because temperature acts on logits, it interacts with other decoding controls:
-
Top-p (nucleus sampling): Sample only from the smallest set of tokens whose cumulative probability exceeds p (e.g., 0.9). Lower top-p → tighter diversity even if temperature is high.
-
Top-k: Restrict to the k most probable tokens. Lower k reduces tail exploration.
-
Frequency penalty / presence penalty: Penalize repeated tokens (frequency) or encourage introducing new tokens (presence) to reduce repetitive output or stimulate novelty.
-
Maximum length / stop sequences: Constrain rambling and enforce clean termination.
Practical tip: Tune temperature in tandem with nucleus sampling (top-p) and penalties. For example, T=0.7, p=0.9 often yields richer but still coherent text.
Next Word Prediction and Decoding Strategies
LLMs generate one next word (token) at a time. The sampler transforms logits by temperature, applies softmax distribution, optionally prunes by top-p or top-k, then draws the next token. This iterative next token choice shapes style and content. For a comprehensive guide to setting up your local LLM for optimal performance, read more here.
Common decoders:
-
Greedy (deterministic): always pick the argmax. Equivalent to T \to 0 with no sampling.
-
Beam search: explores multiple high-probability paths; useful for tasks like translation, but can reduce variety.
-
Temperature + top-p/top-k: the standard for controllable, high-quality free-form generation.
-
Speculative decoding: speeds up generation (not a diversity control) but keep in mind that it assumes a proposal model; it doesn’t replace temperature.
Choosing Temperature by Use Case
Low temperature (0.0–0.3):
-
Compliance, tasks requiring precision, retrieval-grounded answers with citations, code generation, database queries, deterministic formatting.
Medium temperature (0.4–0.7):
-
Chatbots, long-form summaries, product descriptions, email drafting, educational content where tone matters but correctness remains important.
High temperature (0.8–1.2):
-
Creative writing, brand voice experimentation, brainstorming, naming, lyric or narrative sketches where diverse outputs are valued.
The right temperature depends on the model, the data, and the desired outcome. Start with a recommended band, then refine using empirical analysis and user feedback.
Optimizing LLM Output: A Tuning Playbook
-
Define your metric. Will you judge by human ratings, rubric scores, exactness, or novelty? Align evaluation with goals.
-
Sweep temperature. Try T \in \{0.0, 0.2, 0.4, 0.6, 0.8\} while holding top-p constant (e.g., 0.9).
-
Add nucleus sampling. If outputs are too wild, lower top-p (0.8–0.9). If too bland, raise it (0.92–0.95) or increase temperature slightly.
-
De-repeat with penalties. Apply modest frequency penalty (e.g., 0.2–0.6) for repetitive lists; use presence penalty to encourage new concepts.
-
Constrain format. Use system instructions, explicit schemas, or function/tool calling for predictable structure; rely less on low temperature to enforce format.
-
Compare outputs. Keep a small validation set and run comparing outputs across different temperatures to confirm perceived gains.
-
Document defaults. For each product surface, record temperature/top-p/penalties and rationale; avoid silent drift across releases.
Interactions and Edge Cases
-
Temperature and top-p are coupled. A high temperature with a very low top-p may still look conservative; a medium temperature with a high top-p can be unusually adventurous. Tune both.
-
Model-specific calibration. “0.7” on one provider isn’t guaranteed to match “0.7” on another because raw logits differ. Always validate across models.
-
Short prompts magnify randomness. With limited context, the model relies more on priors; consider lowering temperature or adding conditioning examples.
-
Long prompts approach token limits. If near context capacity, the model may truncate; this can degrade coherence regardless of temperature.
-
High temperature + strict facts. If factuality is paramount, pair high temperature with retrieval (RAG) and stricter top-p, or simply lower the temperature.
Worked Examples (Before/After)
Prompt: “Write two product taglines for a privacy-focused note-taking app.”
-
T = 0.2
-
“Notes that stay yours.”
-
“Capture ideas. Keep them private.”
Consistent, safe, similar each run.
-
-
T = 0.5
-
“Your ideas, locked and beautifully organized.”
-
“Think freely. Store securely.”
Balanced novelty and clarity.
-
-
T = 0.9
-
“Whisper to the page; the page never whispers back.”
-
“Write loud. Share quiet.”
Stylized, evocative, risk of drifting from brief.
-
Use these patterns to align llm output with brand and risk tolerance.
Temperature vs. Other Decoding Controls
-
Temperature: reshapes logits globally, controlling overall adventurousness.
-
Top-k / Top-p: limit the candidate pool; strong local control over tail exploration.
-
Beam search: favors high-likelihood sequences, often reducing diversity; good for exact expected output forms (summaries with strict constraints).
-
Penalties: steer repetition and novelty after temperature and nucleus decisions.
Think “temperature = mood,” “top-p/k = boundaries,” “penalties = stylistic nudges.”
Preventing Irrelevant Responses with Sampling Guards
High T can surface fresh ideas—but it also increases the risk of irrelevant responses. Pair temperature with nucleus sampling (also called nucleus sampling) to cap exploration: restrict choices to tokens whose cumulative probability exceeds p. If drift persists, lower T, tighten p, or switch to other sampling methods (e.g., top-k, contrastive decoding, or beam search for format-critical tasks). These guardrails keep variety without sacrificing alignment to the input context.

Measuring Quality Across Temperature Settings
To avoid purely subjective choices:
-
Content metrics: task rubrics, exact match, BLEU/ROUGE for summarization, factuality checks, citation precision/recall.
-
Behavioral metrics: length control adherence, format compliance, refusal accuracy.
-
Human ratings: usefulness, correctness, tone, coherence.
-
Stability: variance across seeds/runs at a fixed temperature.
-
Cost/latency: higher diverse outputs can increase post-processing time (e.g., more to re-rank or filter).
Run small empirical analysis grids (temperature × top-p) and select the combination that best fits your desired outcome.
Dynamics as Temperature Increases
Expect systematic shifts as temperature increases: wording becomes less repetitive, rare descriptors appear more often, and chains of thought lengthen. Beneficial novelty is moderately correlated with task type (e.g., ideation vs. citation-bound QA). Monitor the trade-off explicitly—when the model’s response must be terse and exact, keep T low; when you value exploration, move into the mid/high band and add retrieval or validation to protect factuality in the generated output.
Practical Implementation Notes (API Mappings)
Vendors expose temperature under different names:
-
“temperature” or “creativity”: same idea; check ranges (often 0–2).
-
Defaults differ. One SDK’s default medium temperature may be another’s low. Always set explicitly.
-
Some providers cap temperature internally for safety. If different temperature values don’t change behavior, the service may be overriding settings in certain modes (e.g., tool calls).
Keep a per-model config registry so product teams don’t guess.
Troubleshooting: Symptoms and Fixes
-
Outputs too bland / repetitive → raise temperature slightly (e.g., 0.4 → 0.6), increase top-p (0.9 → 0.92), apply a small presence penalty.
-
Outputs incoherent / off-brief → lower temperature (0.8 → 0.5), reduce top-p (0.95 → 0.9), strengthen system prompt with examples.
-
Hallucinations in facts → lower temperature, add retrieval grounding, or constrain to tool outputs; check that probable word choices align with sources.
-
Overlong answers → cap maximum length, tighten instructions, or reduce top-p to keep focus.
-
Inconsistent formatting → use structured outputs (JSON schemas, function calls), then relax temperature for style inside fields where safe.
Quick Reference: Temperature by Pattern
-
Extraction / classification: 0.0–0.2
-
Fact-first Q&A (with citations): 0.1–0.4 + top-p 0.8–0.9
-
General chat: 0.4–0.7
-
Marketing copy / ideation: 0.7–1.0
-
Poetry / fiction vignettes: 0.9–1.2 (monitor coherence)
Remember: these are starting points; verify with comparing outputs and user studies.

FAQ: Temperature in Practice
Understanding key NLP concepts like softmax distribution, model samples, and temperature-based decoding helps clarify how temperature controls the randomness and creativity of the model's output. Here are answers to common questions about temperature settings and their impact on llm generated text.
1) Is temperature the only “creativity” control?
No. Combine with nucleus sampling, frequency penalty, and presence penalty for finer control of diversity and repetition.
2) Why do identical temperature settings feel different across models?
Base logits differ by model family and training; calibration isn’t standardized. Always re-tune per model.
3) Does a low temperature guarantee correctness?
No. It makes outputs more predictable, not necessarily more true. Use grounding, tools, or verification.
4) What about slightly higher temperatures like 0.6–0.7?
They often produce slightly more novel outputs while preserving coherence—good defaults for many assistants.
5) How do I pick the right temperature quickly?
Run a small sweep (0.2/0.5/0.8) on a validation set; collect human ratings and pick the winner.
6) Can I vary temperature within a single response?
Yes, with staged prompting: low temperature for structured sections, higher for free-form parts.
7) Does temperature affect “one token” at a time only?
Decoding is sequential, so yes—but cumulative choices shape the whole output’s style and content.
8) Will temperature changes break compliance formatting?
They can. Enforce schemas with tool calling or post-validators, and keep temperature lower for structural elements.
9) Is beam search better than temperature sampling?
For some deterministic tasks, yes. For open-ended generation, temperature + top-p typically yields more natural text.
10) Are there tasks where temperature doesn’t matter?
Highly constrained tool-use or retrieval-only answers may be dominated by constraints—but temperature still affects tie-breaks and wording.
Conclusion
Temperature is a central control for shaping the trade-off between coherence and diversity in large language models. By understanding how temperature settings reshape the softmax distribution—and by pairing them with nucleus sampling, frequency penalty, and presence penalty—you can align llm output with the exact desired outcome of your application.
There is no universally “best” temperature: the optimal temperature depends on the task, the model family, and product constraints around accuracy, style, and cost. Treat temperature as an experiment-backed configuration, not a guess. With small, systematic empirical analysis—comparing outputs across different temperatures—you’ll arrive at settings that deliver reliable, high-quality, and appropriately creative generated text for your users.

