How to Use Mistral AI?
Mistral AI builds efficient, production-ready large language models with a modern architecture that emphasizes throughput, quality, and control. Mistral AI's focus on generative AI is driving advancements in large language models, enabling new capabilities in content creation and reasoning. You can start with general-purpose mistral models for chat and reasoning, or select specialist variants for code, search, and structured outputs. These models are trained for specific tasks such as chat, code, or search.
Mistral’s lineup spans compact checkpoints for edge inference and larger models for high-quality generation in the cloud. The company also maintains open models (open weights) you can run locally, plus hosted endpoints for teams that prefer managed services. Mistral AI's products and strategic growth have positioned it as a leader in the AI industry. The models generate content, responses, or embeddings in response to user prompts.
A core promise is a strong commitment to privacy and portability: you choose where models run, how prompts are stored, and what parameters govern behavior.


Understanding Mistral AI
At a high level, Mistral focuses on efficient training and processing techniques—mixture-of-experts (MoE), careful data curation, and optimized inference stacks. Mistral models are trained using these methods to optimize for high quality at favorable cost.
The ecosystem includes three main entry points: La Plateforme (the developer console and APIs), Le Chat (a chat UI to explore capabilities), and model artifacts you can deploy on-prem or at the edge.
Most mistral models are multilingual and fluent in English, French, German, Spanish, Japanese, Korean, and Chinese, which helps when your user base spans Europe and beyond.


Quick Start: Pick a Model
For general chat, choose Mistral Medium or Mistral Large (latest version)—often marketed as mistral large latest in SDK tags.
For fast, low-latency tasks or embedding pipelines, consider smaller checkpoints tailored for speed.
For coding copilots, use Codestral Mamba; for document agents or structured extraction, select models tuned for tool use and JSON.
Your choice depends on context size needs, latency targets, and cost per token. Start simple; you can switch later by changing a model name and a few parameters.
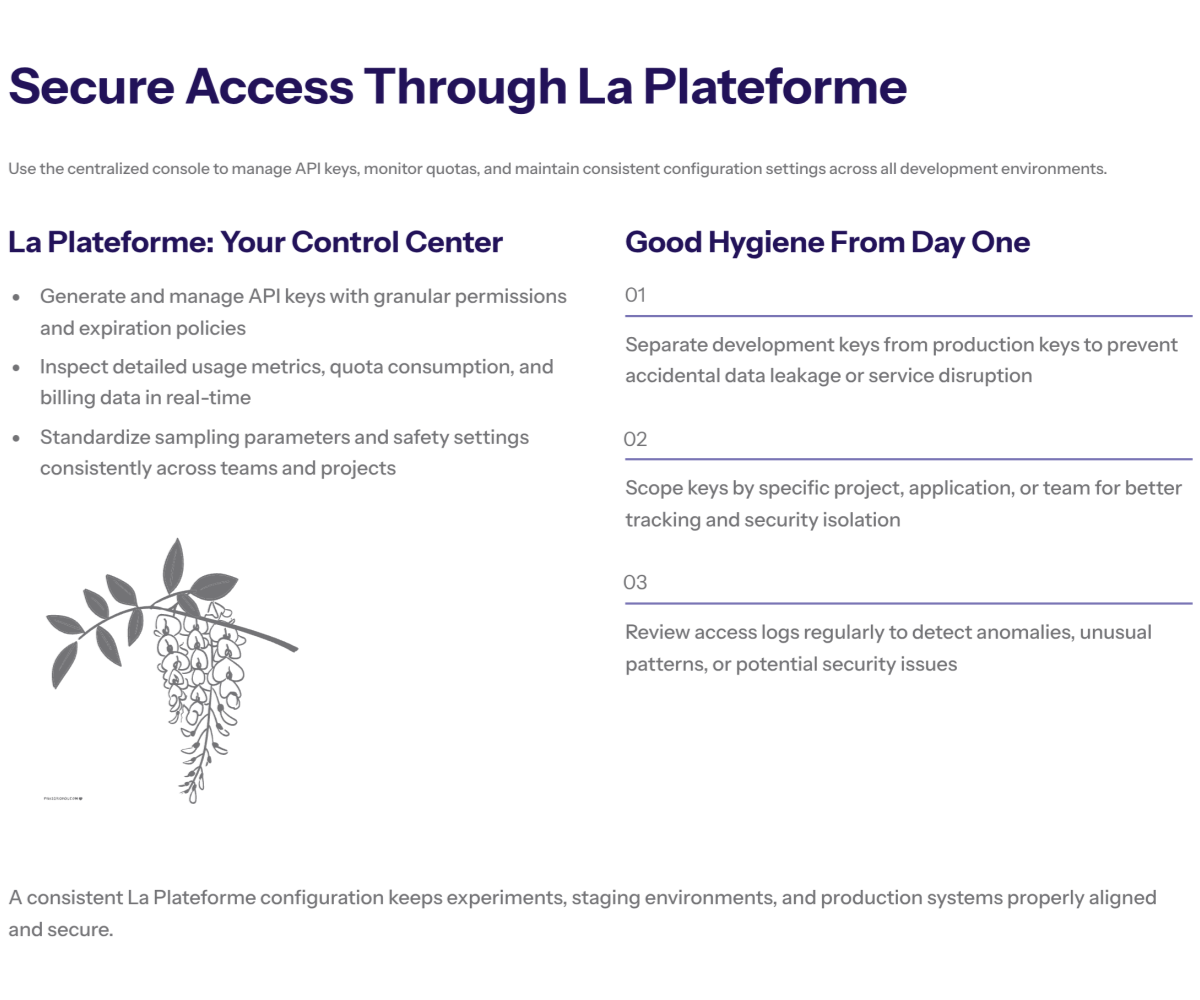
Access via La Plateforme
Sign up on La Plateforme to create an API key and view usage metrics. The dashboard exposes dozens of helpful toggles—sampling parameters, safety controls, and logs—so teams can standardize behavior across environments.
You’ll find SDK snippets, quotas, and endpoint shapes under a clean https interface. Keep separate keys for dev and prod and scope them by project for better security.
Try It in Le Chat
Use Le Chat to experiment with prompts before you write code. Test system instructions, verify how the model handles media references, and check multilingual ability.
As you iterate, copy the prompt and parameters from Le Chat into your application. This tight loop speeds up prompt design and reduces rework for your user experience.
![Slide showing side-by-side pseudo-code snippets in Python and JavaScript calling the Mistral chat completions endpoint, with labels highlighting “model name,” “messages[],” and “temperature/top_p.”](/images/19238)
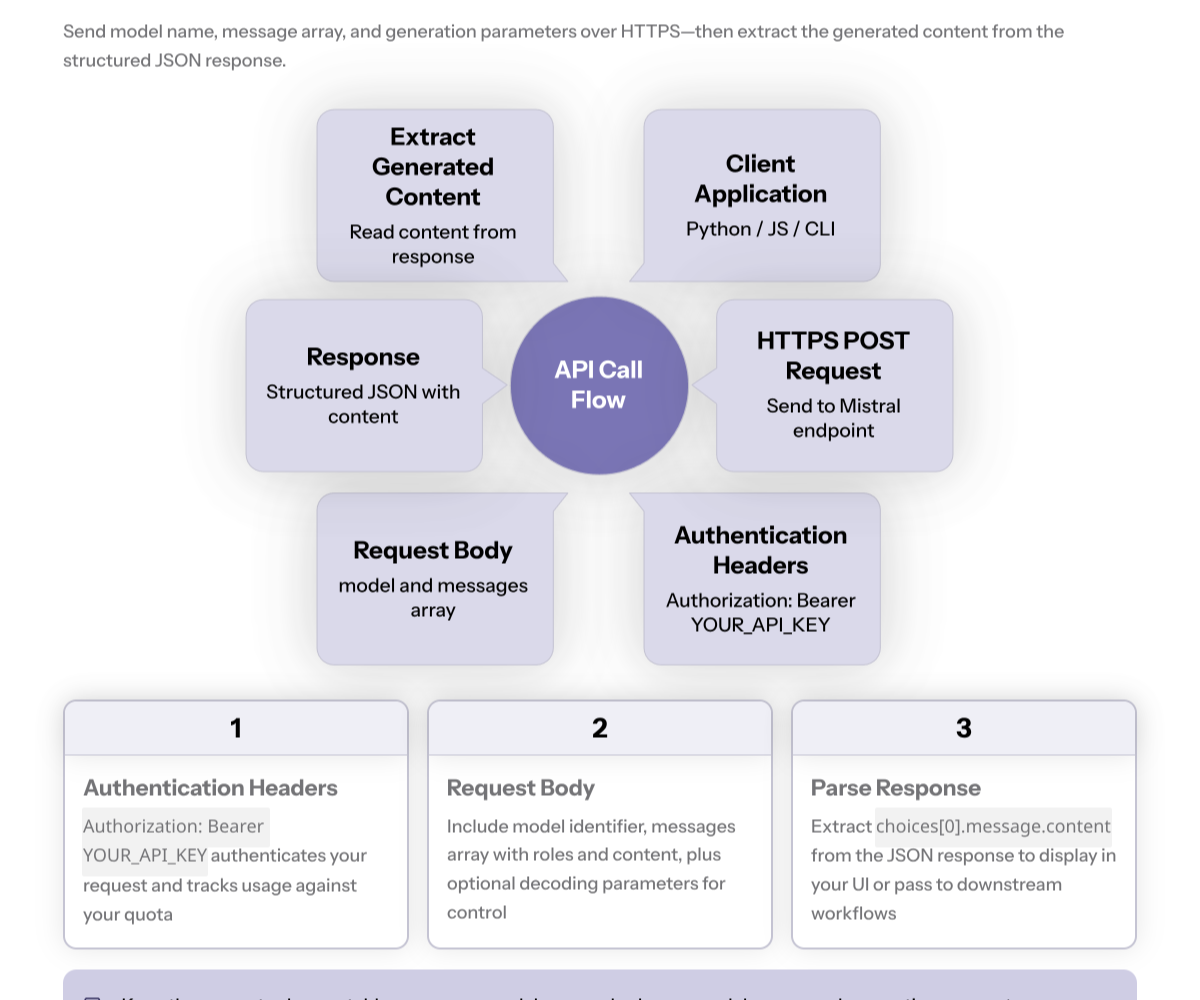
Call the API (Examples)
Below are minimal calls against the standard https endpoint. Replace YOUR_API_KEY and the model name you’ve chosen.
Python
import requests, json
url = "https://api.mistral.ai/v1/chat/completions"
headers = {"Authorization": "Bearer YOUR_API_KEY", "Content-Type": "application/json"}
payload = {
"model": "mistral-large-latest",
"messages": [{"role": "user", "content": "Give me 3 bullet points on model quantization."}],
"max_tokens": 200,
"temperature": 0.4,
"top_p": 0.9
}
resp = requests.post(url, headers=headers, data=json.dumps(payload), timeout=60)
print(resp.json()["choices"][0]["message"]["content"])
JavaScript
const r = await fetch("https://api.mistral.ai/v1/chat/completions", {
method: "POST",
headers: { "Authorization": "Bearer YOUR_API_KEY", "Content-Type": "application/json" },
body: JSON.stringify({
model: "mistral-large-latest",
messages: [{ role: "user", content: "Summarize retrieval augmented generation in 5 lines." }],
temperature: 0.5, top_p: 0.9
})
});
const data = await r.json();
console.log(data.choices[0].message.content);
cURL
curl https://api.mistral.ai/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "mistral-large-latest",
"messages": [{"role":"user","content":"Explain MoE in one paragraph."}],
"temperature": 0.3, "max_tokens": 256
}'
Control Generation with Parameters
Tuning decoding parameters lets you balance creativity, determinism, and cost.
-
temperature: 0.0–1.0; lower values assign high probabilities to top tokens and yield more consistent answers.
-
top_p / top_k: nucleus and k-sampling to trim the tail; these shape the softmax distribution used in token selection.
-
max_tokens: cap the generated length to manage cost and latency.
-
presence_penalty / frequency_penalty: reduce repetition; useful for long reports.
Start with temperature=0.3, top_p=0.9, then adjust based on user feedback and evaluation.

Handle Context and Context Length
Every request consumes a context window composed of your prompt plus the model’s generated tokens.
Be mindful of context length limits; long histories or big documents can fill the buffer quickly and impact processing time.
Use summaries and retrieval to keep only the most relevant input. Chunk documents, store embeddings, then fetch top passages per query.

Multimodal & Media Inputs
Some endpoints accept media (e.g., images) with text prompts. You can ask the model to caption, extract tables, or ground answers in visual content.
When sending images, include concise descriptions in the input to improve accuracy. Validate file size and formats to avoid retries and wasted processing.
Multimodal support makes it easier to create assistants for receipts, screenshots, or whiteboard photos—especially useful on edge devices with cameras.
Codestral Mamba for Code
Codestral Mamba targets code reasoning and generation with strong autocomplete and translate-between-languages behavior.
You can scaffold tests, migrate snippets across languages (Python, Java, TypeScript), and enforce style using system prompts.
Add repository context via RAG so the model is powered by your project structure, not just public corpora.
Streaming, Speed, and Cost
Enable server-sent event streaming to deliver tokens as the model generates them—this improves perceived speed for your user.
Batch small requests when possible to reduce overhead; measure the trade-off with concurrency.
Track tokens-in and tokens-out to project cost; set parameters like max_tokens to keep budgets predictable.
Run Open Models Locally
If you prefer local inference, pull open models and spin them up with your favorite runtime. This maximizes control, achieves greater data security, and helps with residency requirements in Europe.
Local setups shine for prototyping, private corpora, and offline workloads at the edge. For serving at scale, combine local gateways with managed services.
Cloud, Edge, and Enterprise Options
You can deploy via hosted endpoints in the cloud, containerized services on-prem, or accelerated nodes at the edge for low-latency UX.
For regulated teams, an enterprise model package offers SSO, audit logging, and data-retention controls. These features enable collaboration without sacrificing governance.
Mistral also supports integrations sometimes referred to as Mistral NeMo for GPU scheduling and lifecycle management—useful when you orchestrate dozens of workloads.
Data Protection and Security
Adopt least-privilege API keys, encrypt at rest, and redact PII in logs. Rotate secrets regularly and pin the latest version of model images to avoid surprises.
Design prompts to avoid echoing secrets; disable transcript saving in Le Chat for highly sensitive cases. Add DLP filters when prompts can include customer media or uploaded files.
Multilingual: Build for a Global User Base
The models are fluent in major languages, including Japanese, Korean, and Chinese. This helps you create one flow with regional instructions per locale.
For specialized terminology, include glossaries, style guides, and a few in-domain examples per language. Evaluate with bilingual users before scaling.
Tool Use, RAG, and Function Calling
Use tool/function calling to connect the model to search, databases, and calculators. Keep your tool schema concise; validate input before executing.
With RAG, store embeddings of your knowledge base and attach top passages; this reduces hallucinations and enables grounded answers. Cache frequent queries to save cost.
Monitoring, Evaluation, and Guardrails
Measure faithfulness, toxicity, and policy adherence on held-out prompts. Add automatic checks for PII leakage and risky media content.
Log parameters, prompts, and hashes of retrieved context so you can reproduce behavior. Roll out in stages and watch real-time metrics for drift.
Best Practices for AI Development
Mistral AI’s strong commitment to open-source models and transparent artificial intelligence development has shaped a set of best practices that empower teams to build robust, secure, and high-performing AI solutions. Whether you’re deploying Mistral AI models for text generation, document understanding, or code generation tasks, following these guidelines will help you maximize the value and reliability of your AI projects.
1. Optimize for Context Length and Enterprise-Grade Needs
When working with Mistral models—such as Mistral Small for lightweight tasks or Mistral Large (latest version) for enterprise-grade applications—always consider the context length required by your use case. Efficiently managing input and output context ensures faster processing, lower cost, and more relevant results. For complex workflows, leverage the ability to fine-tune models, adapting them to your domain-specific data for improved accuracy and performance.
2. Prioritize Security and Data Privacy
Protecting your data is paramount. Always use unique API keys for each project and environment, and manage your API endpoint access with strict permissions. Mistral AI’s architecture is designed with security in mind, supporting encrypted data processing and compliance with enterprise standards. Regularly rotate your API keys and monitor usage to prevent unauthorized access.
3. Leverage Open-Source and Multimodal Capabilities
Mistral AI’s open source models and open weights allow you to experiment, collaborate, and innovate with confidence. Take advantage of the company’s multimodal models to process not just text, but also images and other media, expanding the range of applications you can build. Tools like Le Chat and La Plateforme make it easy to prototype, test, and deploy solutions across dozens of languages—including French, Italian, German, Spanish, Japanese, Korean, and Chinese—enabling you to serve a truly global user base.
4. Balance Performance, Cost, and Flexibility
Select the right model for your needs: use Mistral Small for speed and cost efficiency, or Mistral Large for state-of-the-art performance in demanding scenarios. For code generation tasks, Codestral Mamba offers specialized capabilities. Always monitor your usage and adjust parameters to keep costs predictable while maintaining high-quality outputs.
5. Foster Experimentation and CollaborationMistral AI’s development philosophy encourages users to experiment with new features, collaborate across teams, and contribute to the evolution of language models. The company’s roots in southern France reflect a European commitment to privacy, innovation, and inclusivity—values that are embedded in every aspect of its AI models and services.
6. Stay Future-ReadyAs the field of artificial intelligence evolves, Mistral AI continues to push the boundaries with new models, larger context windows, and enhanced multimodal capabilities. By following best practices and leveraging the latest version of Mistral models, you’ll be well-positioned to create secure, scalable, and innovative AI-powered solutions.
To get started, explore Mistral AI’s API endpoint, experiment with Le Chat, and review the documentation on La Plateforme.
By embracing these best practices and harnessing the power of Mistral AI’s open-source models, you can create AI solutions that drive growth, efficiency, and global impact. Visit https://mistral.ai to learn more about the company’s offerings and join a vibrant community shaping the future of artificial intelligence.
Common Pitfalls and How to Avoid Them
Overlong context windows lead to higher cost and slower processing—summarize and prune.
Unbounded temperature risks irrelevant responses—use a moderate setting and penalties.
Ignoring system prompts yields inconsistent tone—standardize base instructions across all services.

End-to-End Example: Doc Q&A Agent
-
Index PDFs; store embeddings.
-
Build a retrieval layer that returns top-k passages + citations.
-
Call mistral large latest with a system prompt that enforces JSON answers.
-
Set decoding parameters: temperature=0.2, max_tokens=400.
-
Stream tokens to the user and render citations under the generated answer.
This example scales from a single laptop to a cloud cluster. Another example swaps in Codestral Mamba and adds test generation for codebases.
Mistral Offers and Where to Go Next
Mistral offers a pragmatic path: start in Le Chat, deploy via La Plateforme, or bring open models to your stack.
For long-term success, document your architecture, set SLOs, and keep prompts versioned. This mindset protects quality as teams grow.
Future Outlook
Expect broader multimodal models, larger context windows, and better tool-use APIs in the future. Latency improvements and energy-aware schedulers will keep quality and cost aligned.
Keep an eye on roadmap posts and changelogs; new parameters and model families often unlock simpler designs with fewer prompts.
Frequently Asked Questions about Using Mistral AI
To help you get the most out of Mistral AI, here are answers to some common questions about the platform, its models, and capabilities. These FAQs cover key aspects like fine tuning, document understanding, and leveraging enterprise-grade features to enhance your AI development experience.
Who are the founders of Mistral AI?
Mistral AI was co-founded by Timothée Lacroix, who is a key researcher known for his expertise in large-scale AI models. His leadership and innovation have contributed significantly to the company's credibility and achievements in AI development.
What are the benefits of fine tune capabilities in Mistral AI models?
Fine tuning allows you to adapt Mistral AI models to your specific domain or use case, improving performance and relevance. By customizing the model with your own data, you can enhance text generation quality, reduce hallucinations, and optimize the model for specialized tasks such as code generation tasks or document understanding. This flexibility makes Mistral AI suitable for both research and enterprise-grade applications.
How does Mistral AI support document understanding in complex workflows?
Mistral AI offers specialized models and APIs designed for advanced document understanding, including parsing tables, extracting structured data, and interpreting layouts in scientific papers or business reports. These capabilities enable developers to build intelligent agents and leverage AI development services that automate processing of diverse document types, improving efficiency and accuracy in enterprise environments.
What enterprise-grade features does Mistral AI provide for secure deployment?
Mistral AI emphasizes security and compliance with features such as role-based access control (RBAC), audit logging, and data retention policies. Its flexible deployment options allow running models on-premises, in the cloud, or at the edge, giving organizations control over data privacy and regulatory requirements. These enterprise-grade provisions ensure reliable and secure AI services for mission-critical applications.
How do I choose between small and large models?
Start small for speed and iterate. If quality plateaus, switch to mistral large latest and re-evaluate with the same prompts.
Can I run models for free?
You can try open models locally; hosted endpoints bill by tokens. Local isn’t entirely free—you’ll pay in hardware and ops.
Is there a UI for non-developers?
Yes—Le Chat. Share prompt templates so non-technical users can experiment safely.
Do models accept images?
Select multimodal models that parse media; follow file and size guidelines for reliable processing.
What about on-prem?
Use containers and GPUs on your infra or at the edge; pair with RBAC and audit logs for security.
Quick Checklist
-
Pick a model (chat vs. Codestral Mamba).
-
Test prompts in Le Chat.
-
Get an API key from La Plateforme over https.
-
Tune decoding parameters and context strategy.
-
Add RAG/tooling; monitor quality, cost, and latency.
-
Scale to the cloud or the edge as needs evolve.
With these steps, you’ll be ready to create robust, multilingual applications powered by Mistral—across prototypes, production services, and global users.

