
Local AI Solutions for Enhanced Privacy and Performance
Local AI solutions represent a powerful alternative to traditional cloud-based AI models by enabling data processing and inference directly on local devices. This approach offers significant benefits, including improved data privacy, reduced latency, and cost efficiency, making it an ideal choice for businesses seeking to harness AI while maintaining control over sensitive information. By leveraging advanced local AI tools and parameter-efficient fine-tuning, organizations can unlock new possibilities in AI development, driving innovation across various industries and paving the way for a new era of personalized, secure, and offline-capable AI applications.
Key Takeaways
-
Local AI solutions empower businesses to maintain full control over sensitive data by running AI models directly on local devices, enhancing privacy and security while reducing reliance on cloud servers.
-
By eliminating the need for constant internet connectivity and cloud infrastructure, local AI significantly reduces latency and operational costs, enabling real-time decision making and offline functionality.
-
Advanced frameworks and tools for running AI models locally, combined with parameter-efficient fine-tuning, unlock new possibilities for personalized, cost-efficient, and high-performance AI applications across various industries.

Introduction to Artificial Intelligence
Artificial intelligence (AI) is the discipline of building systems that perform tasks which typically require human intelligence—classification, prediction, reasoning, and language understanding. For more than a decade, most AI applications shipped as cloud services. Today, a new wave of local AI (also called edge AI) is shifting AI workloads to local devices such as laptops, smartphones, embedded boards, and browsers. Running AI models locally minimizes round trips to cloud servers, …
This guide takes a practical, vendor-neutral look at the best local AI solutions available now, how to run AI models locally for real-time decision making, and what a tech lead should consider when selecting, training, and deploying AI applications at the edge.
Benefits of Local AI
Moving inference from the cloud to the device changes your risk, cost, and UX calculus:
-
Enhanced data privacy and data security: Keeping sensitive data on device reduces exposure from sending data to remote servers, shrinking your attack surface and regulatory footprint. In many workflows—legal, health, finance—avoiding sending data to the cloud is the simplest way to stay compliant. Apple’s on-device stack is a canonical example of this privacy-by-design approach.
-
Low latency & offline reliability: Local inference removes network hops and local AI eliminates the need for a constant internet connection. Apps keep working on factory floors, in hospitals, and in low-connectivity environments.
-
Cost efficiency: You avoid recurring API fees and egress charges, amortizing hardware you already own. When scaled across fleets, local AI significantly reduces TCO.
-
Performance & personalization: On modern hardware, optimized models deliver high accuracy and faster response times. You can fine-tune and cache on-device for personalized behavior without sharing sensitive data.
-
Resilience: Local systems continue to operate during cloud outages or rate limits. For safety-critical security systems and robotics, that’s a game changer.
Data Privacy and Security
Data privacy is a primary driver for local inference. By keeping data on device, teams avoid transmitting sensitive information to third parties. You retain data ownership, maintain auditability, and minimize cross-border transfer concerns. For regulated industries, local AI dramatically simplifies DPIAs and vendor risk reviews. Security posture also improves:
-
Fewer exposed endpoints (no public inference APIs).
-
Smaller blast radius—breaches of a vendor’s backend don’t automatically compromise your users.
-
Optional on-device model encryption (for example on Apple platforms) to protect intellectual property at rest.
While cloud AI providers invest heavily in security, the act of centralizing data in shared infrastructure introduces inherent aggregation risk. Local AI solutions mitigate that by design.
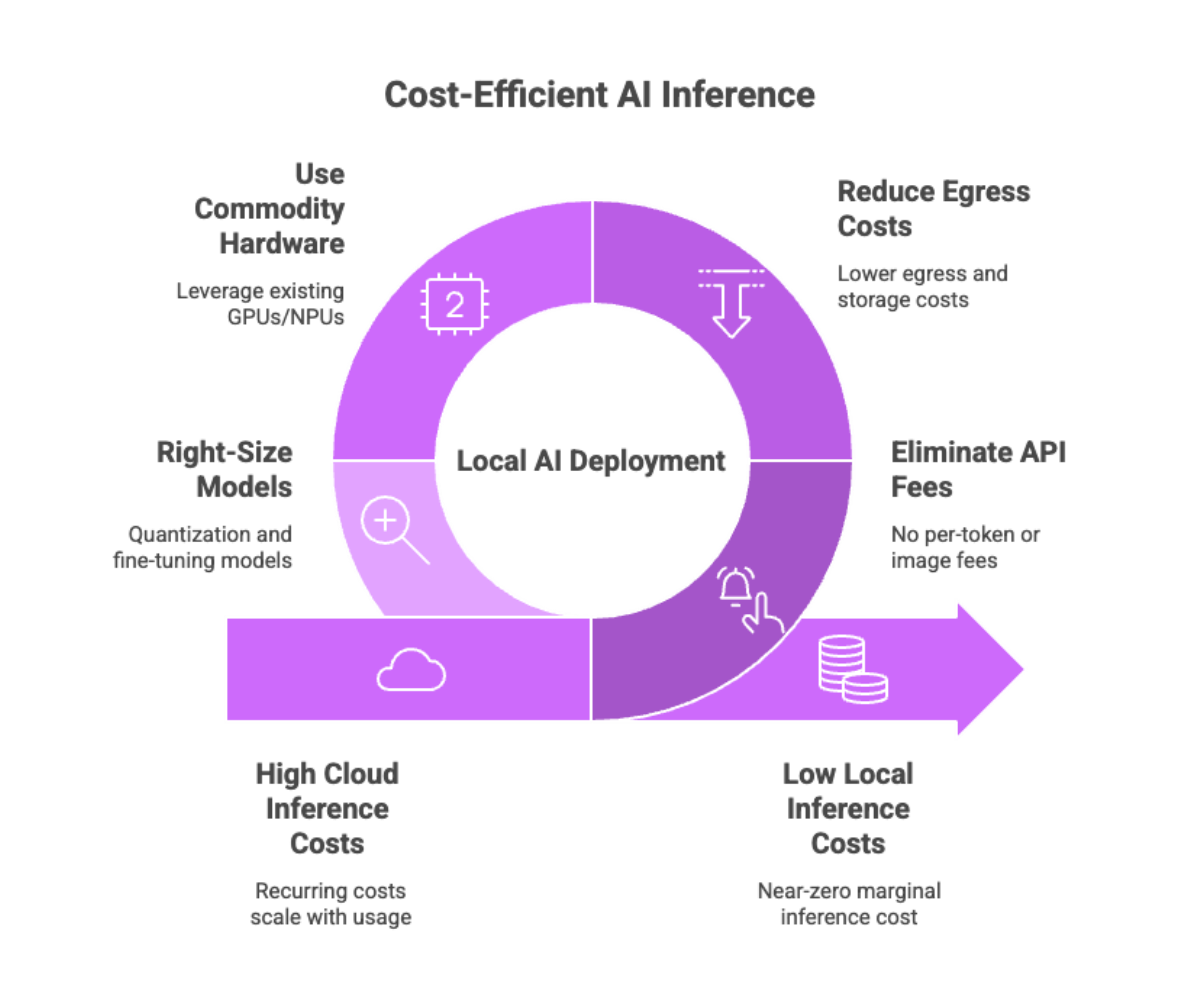
Cost Efficiency of Local AI
Cloud inference is convenient, but recurring costs scale with usage. Local AI flips the equation: you invest in one-time hardware and software development, then run inference at near-zero marginal cost. Savings come from:
-
Eliminating per-token or per-image API fees.
-
Reducing egress and storage line items.
-
Using commodity GPUs/NPUs already present in devices.
-
Right-sizing models (quantization, parameter-efficient fine-tuning) to match your hardware.
Across fleets, local deployment can be the most cost-efficient path for steady workloads, while the cloud remains a good burst-capacity or experimentation layer.
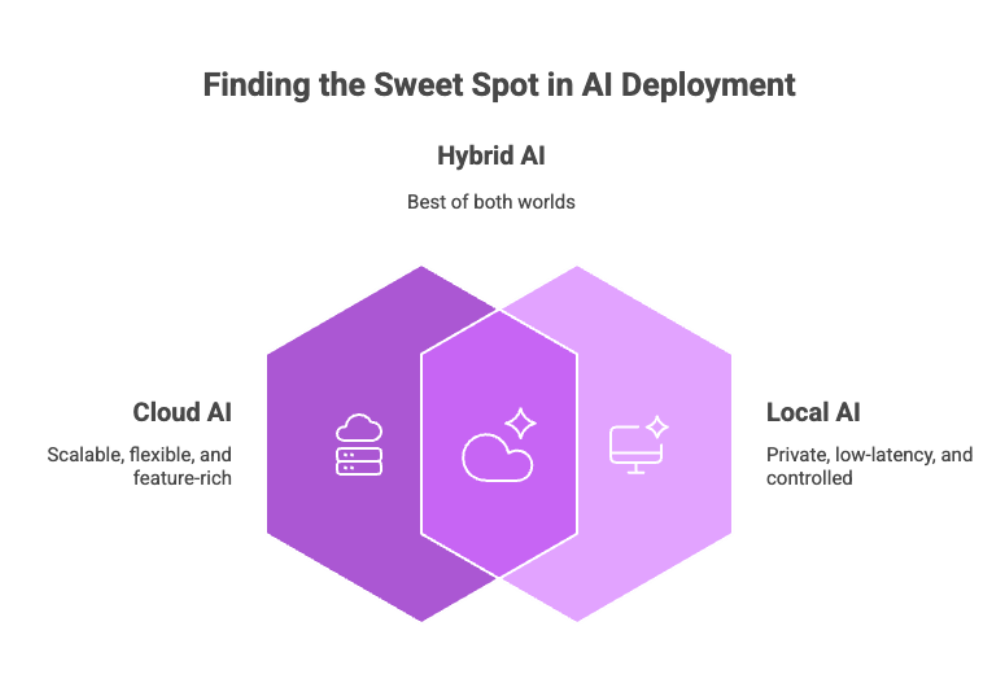
Cloud AI vs. Local AI: A Comparison
Both approaches have merit. The sweet spot for many organizations is a hybrid posture.
-
Cloud AI: Quick to start, easy to scale, rich model catalogs. Trade-offs: higher recurring costs, network latency, potential exposure of sensitive data, dependence on remote servers.
-
Local AI: Lower latency, strong privacy posture, full control over data and tuning, predictable costs. Trade-offs: device constraints, maintenance of runtimes/drivers, careful model selection.
For privacy-critical, latency-sensitive AI apps, local AI is often the default; for experimentation and spiky workloads, cloud AI shines. Many teams blend them—local first, cloud fallback.
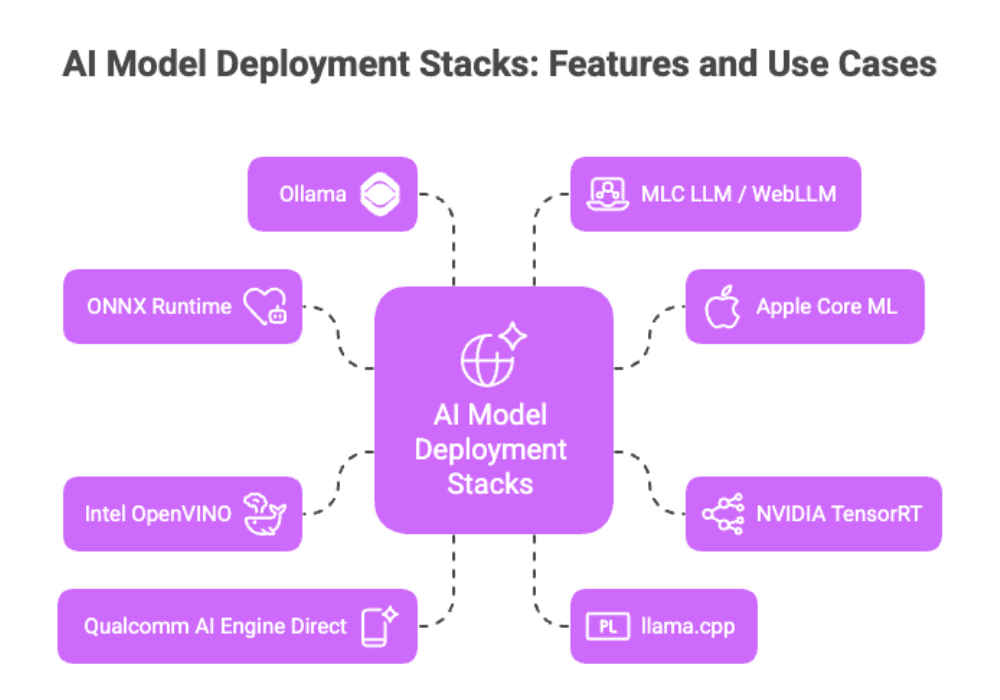
Best Local AI Solutions: Frameworks, Runtimes, and Tooling
Below are the leading stacks for running AI models locally—from general-purpose inference runtimes to specialized LLM launchers. Each is production-proven and actively maintained.
ONNX Runtime (with Execution Providers)
ONNX Runtime is a universal engine for deploying models across CPUs, GPUs, and NPUs using pluggable Execution Providers. You can target DirectML on Windows GPUs, TensorRT on NVIDIA, OpenVINO on Intel, NNAPI on Android, and Core ML on Apple silicon—one graph, many backends. This is the “write once, run anywhere” layer for edge AI. It’s ideal for classic vision, audio, and small/medium language models.
-
Best for: Cross-platform AI solutions where you want one model to run on many devices (PCs, mobiles, embedded).
-
Why: Mature optimizations, hardware abstraction, strong vendor support.
Apple Core ML
Core ML is Apple’s on-device framework that automatically routes operators to CPU, GPU, or Neural Engine, and supports model encryption. With Apple silicon, it can run mid-size large language models locally at interactive speeds. Great fit for iOS, visionOS, and macOS apps prioritizing privacy and UX.
-
Best for: Apple-first products needing tight OS integration and on-device privacy.
-
Why: Optimized kernels, NE acceleration, first-class developer tooling.
NVIDIA TensorRT (and TensorRT-LLM)
TensorRT is NVIDIA’s compiler/runtime that squeezes maximum throughput and minimum latency from CUDA GPUs. For LLMs, TensorRT-LLM provides graph-level optimizations, paged KV-cache, and speculative decoding. If you ship on RTX PCs or Jetson edge devices, this is the path to top-tier performance.
-
Best for: Throughput-critical workloads on NVIDIA GPUs (vision AI, recommenders, security systems, LLMs).
-
Why: Aggressive fusion, precision calibration, LLM-specific kernels.
Intel OpenVINO
OpenVINO accelerates inference on Intel CPUs, integrated GPUs, and NPUs, with growing GenAI support. It includes conversion/optimization tools and an execution provider to run ONNX graphs efficiently—particularly compelling on iGPUs where every millisecond counts.
-
Best for: Intel-heavy fleets (desktops, edge gateways) seeking cost efficiency and good per-watt performance.
-
Why: Broad model coverage, strong CPU/iGPU acceleration, simple packaging.
Qualcomm AI Engine Direct (QNN) / Windows ML
On Snapdragon devices (Android and Windows on ARM), Qualcomm’s QNN targets the Hexagon NPU for low-power, on-device inference. On Windows 11, the new Windows ML runtime (powered by ONNX Runtime) orchestrates GPUs and NPUs with policy-based EP selection, giving you a consistent way to route AI workloads for real-time decision making on Copilot+ class hardware.
-
Best for: Battery-sensitive mobile and Windows ARM devices that need NPU offload.
-
Why: Vendor-optimized kernels, EP integration, strong ecosystem momentum.
llama.cpp + GGUF
llama.cpp is the C/C++ workhorse for running AI models (especially language models) fully offline across CPUs and GPUs. It uses the GGUF format and supports quantization (Q4–Q8) for tiny memory footprints. If you require a lightweight, embeddable LLM runtime with minimal dependencies, this is it.
-
Best for: Shipping an LLM inside your app, kiosks, air-gapped environments.
-
Why: Small binaries, broad hardware support (CPU, CUDA, Metal, Vulkan), robust community.
Ollama (Local LLM Orchestrator)
Ollama wraps model download, configuration, and serving behind a simple CLI and local REST API. It supports importing GGUF checkpoints via a Modelfile, exposes an OpenAI-style interface, and plays nicely with developer tooling. Think of it as a “Docker for local LLMs.”
-
Best for: Teams that want fast prototyping and a stable local AI endpoint on laptops and servers.
-
Why: One-command pulls, run locally with sane defaults, easy integration.
MLC LLM / WebLLM (In-App & In-Browser)
MLC LLM compiles models to run natively on Apple, AMD, and NVIDIA GPUs—and its WebLLM sibling runs LLMs directly in the browser with WebGPU. This unlocks AI applications that never touch the network: installable PWAs, educational tools, and consumer apps with strong privacy by default.
-
Best for: Cross-platform apps, web experiences, and BYOD scenarios.
-
Why: Compiler-driven optimization, WebGPU acceleration, OpenAI-compatible APIs in browser.
Running AI Models Locally: Architecture Patterns
A pragmatic edge stack looks like this:
-
Model format & conversion: Standardize on ONNX for classical models; use GGUF for LLMs when targeting llama.cpp/Ollama.
-
Inference runtime: Choose an engine per platform (ONNX Runtime, Core ML, TensorRT, OpenVINO) or a launcher (Ollama, llamafile) for language models.
-
Hardware acceleration: Select EPs/backends—DirectML (Windows), TensorRT (NVIDIA), Core ML (Apple), OpenVINO (Intel), NNAPI (Android), QNN (Qualcomm), WebGPU (browser).
-
App integration: Serve via localhost API (Ollama), embed a library (ONNX Runtime, llama.cpp), or run in-browser (WebLLM).
-
Observability & safety: Log tokens/latency on device, add guardrails, and implement local data privacy policies (no telemetry of sensitive data).
Minimal examples
Below are minimal examples demonstrating how to run local AI models using popular runtimes and tools to help you get started quickly and effectively.
ONNX Runtime (Python)
import onnxruntime as ort
opts = ort.SessionOptions()
sess = ort.InferenceSession("model.onnx", sess_options=opts, providers=["DmlExecutionProvider","CPUExecutionProvider"])
y = sess.run(None, {"input": X})(DirectML EP accelerates Windows GPUs; fall back to CPU if needed.)
llama.cpp (CLI)
./llama-cli -m ./model.Q4_K_M.gguf -p "Explain edge AI in one sentence."(GGUF is the required format for llama.cpp models.).
Ollama (serve locally)
ollama run mistral:7b-instruct
# then POST to http://localhost:11434/api/generate(Ollama exposes a localhost HTTP API for simple integration.)
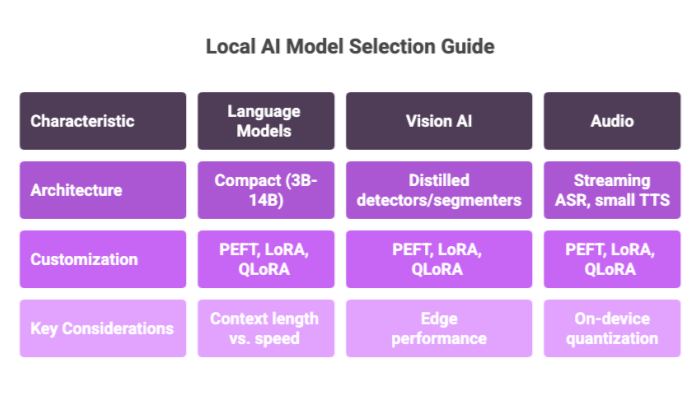
AI Model Selection and Training
Choosing the right local AI models depends on task, hardware, and latency budget:
-
Language models: Prefer compact architectures (e.g., 3B–14B) that fit your VRAM/Unified Memory. Evaluate context length vs. speed.
-
Vision AI: Use distilled detectors/segmenters (e.g., MobileNet-family, YOLO-N variants) for edge performance.
-
Audio: Streaming ASR and small TTS can run well with on-device quantization.
For customization, parameter-efficient fine-tuning (PEFT) is the standard. LoRA injects low-rank adapters into a frozen base and trains only a tiny fraction of weights; QLoRA extends this by fine-tuning adapters while the base is 4-bit quantized—retaining quality with minimal memory. These methods make fine-tuning practical on a single GPU or high-end laptop, and the resulting adapters can be merged and exported to GGUF or ONNX for local deployment.
Practical tips
-
Start with high-quality instruction datasets; noisy data sabotages high accuracy.
-
Use quantization-aware training or post-training quantization to hit your latency target.
-
Evaluate accuracy on-device; kernel differences (e.g., WebGPU vs. CUDA) can shift numerics.
-
For vision AI pipelines, move pre/post-processing into the graph to reduce CPU overhead.
-
For LLMs, align context window with device memory—oversized windows slow generation and may degrade UX.
AI Development and Deployment
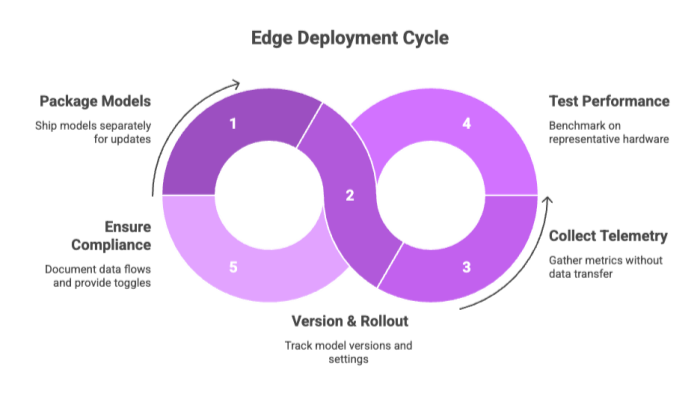
Effective edge deployment blends MLOps with DevOps:
-
Packaging: Ship models separately from app binaries so you can update them over the air (or sideload in air-gapped sites).
-
Versioning & rollouts: Track model versions and EP settings per device cohort.
-
Telemetry (privacy-preserving): Collect metrics (latency, error rates) without sending data or prompts off device.
-
Testing: Benchmark on representative hardware; include cold-start and warm-cache scenarios.
-
Safety & compliance: Document on-device data processing flows; provide toggles for offline-only mode.
Industry Applications of Local AI
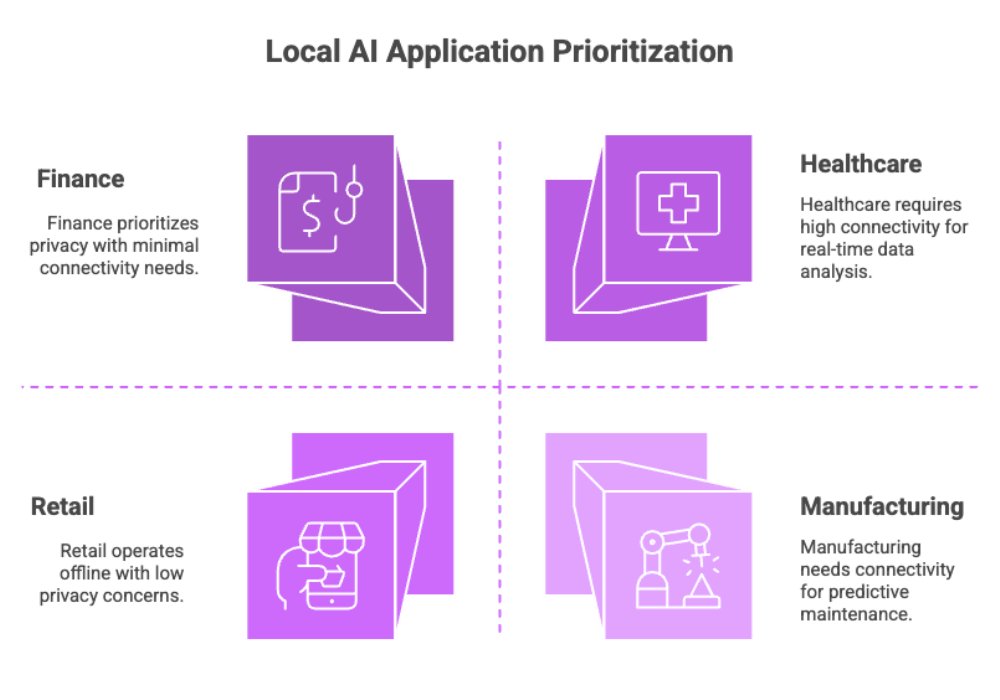
Local AI excels where milliseconds, privacy, or connectivity matter:
-
Healthcare: On-device triage, OCR of lab forms, radiology assist with de-identified images (no external servers).
-
Finance: Meeting summarization and entity extraction with sensitive information kept client-side.
-
Retail: Shelf analytics and loss prevention with security systems operating offline in the store.
-
Manufacturing: Predictive maintenance and visual inspection at the line for real-time decision making.
-
Field services & IoT: Drones, meters, and kiosks that run AI models locally, sync opportunistically.
-
Developer tooling: Code assistants and linters that work without an internet connection.
Benchmarking and Performance Tuning
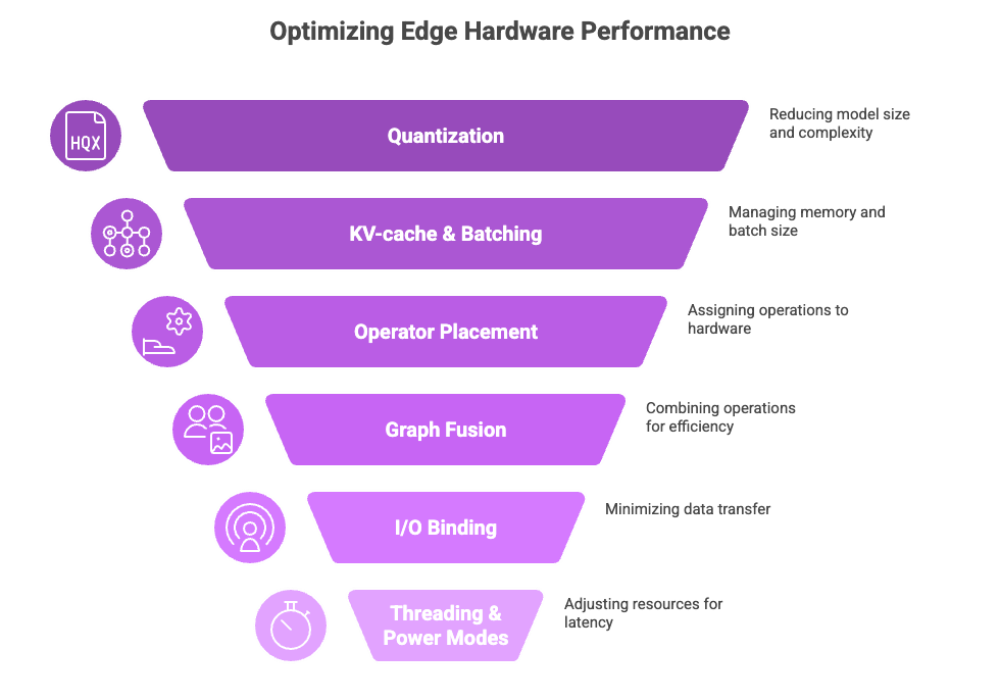
Reaching high accuracy and low latency on edge hardware requires deliberate tuning:
-
Quantization: int8/int4 for transformers; FP16 for GPUs/NPUs that support it. Calibrate with representative data to preserve accuracy.
-
KV-cache & batching (LLMs): Enable paged KV-cache where supported (e.g., TensorRT-LLM) and cap batch size to what your device can sustain without swapping.
-
Operator placement: With ONNX Runtime EPs, pin specific ops to the accelerator and leave unsupported ops on CPU; verify with provider capability logs.
-
Graph fusion: Let compilers fold layernorms, activations, and matmuls where possible; export clean graphs from your training framework.
-
I/O binding: Keep tensors on the device (WebGPU, CUDA, Metal) to minimize host-device copies.
-
Threading and power modes: Tune inter/intra-op threads and device power profiles for your latency SLOs.
-
Memory budgeting: Align context length, batch, and precision to VRAM/Unified Memory. Overshooting often causes dramatic slowdowns.
A sound practice is to establish a repeatable benchmark harness per device class and gate releases on p50/p95 latency, tokens/sec, and accuracy deltas. Record EP settings alongside model hashes to make profiles reproducible.
Compliance, Governance, and Risk
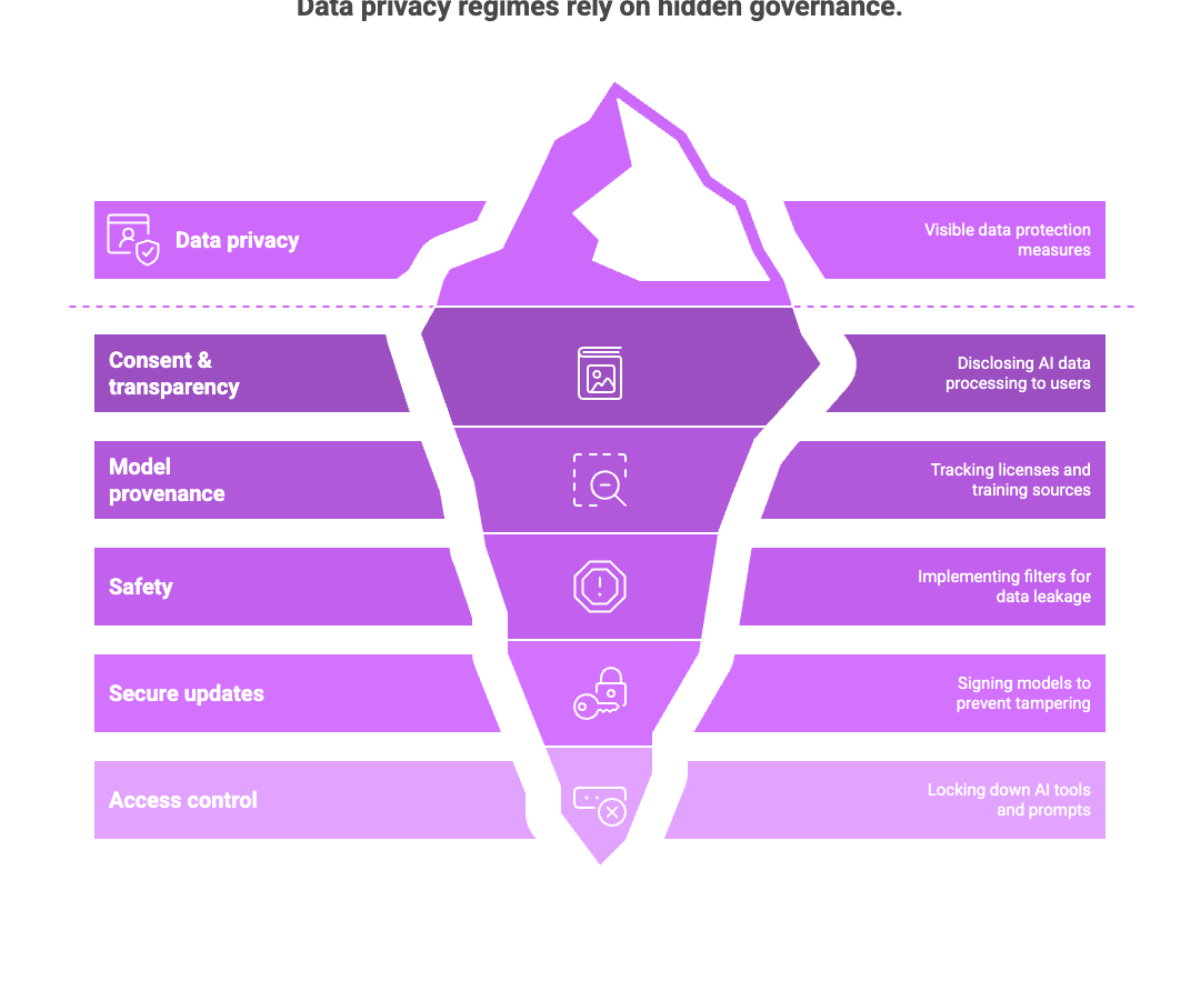
Local processing supports data privacy regimes (e.g., minimizing cross-border transfers under GDPR), but governance still matters:
-
Consent & transparency: Disclose when AI processes user data locally, and provide clear controls.
-
Model provenance: Track licenses and training sources for open source models you redistribute.
-
Safety: Implement local filters for PII leakage and harmful outputs; log safety events on device.
-
Secure update channels: Sign models; verify integrity before loading to prevent tampering.
-
Access control: Lock down AI tools and prompts that could expose internal logic in shared workstations.
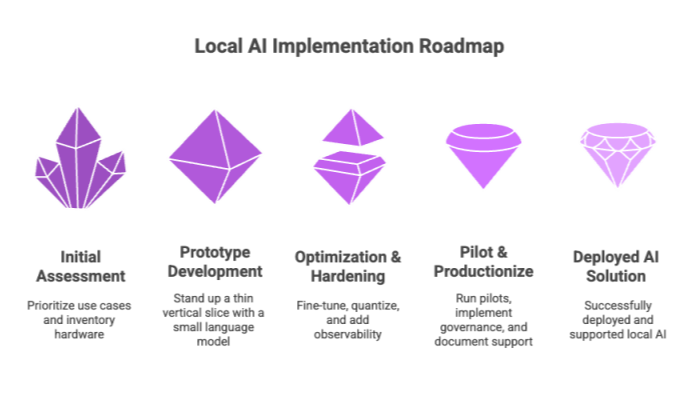
30-60-90 Day Implementation Playbook
Use this 30-60-90 day implementation playbook as a practical roadmap to successfully assess, optimize, and deploy local AI solutions within your organization.
Days 0–30: Assess & prototype
-
Prioritize use cases with privacy or latency pain.
-
Inventory hardware (CPU/GPU/NPU) and choose a primary runtime (ONNX Runtime, Core ML, TensorRT, OpenVINO).
-
Stand up a thin vertical slice with a small language model via llama.cpp or Ollama.
Days 31–60: Optimize & harden
-
Apply parameter-efficient fine-tuning (LoRA/QLoRA) on task data.
-
Quantize and export to ONNX/GGUF; wire EPs (DirectML/TensorRT/Core ML/OpenVINO/QNN).
-
Add observability, local caching, and a rollback path for models.
Days 61–90: Pilot & productionize
-
Run pilots on representative local devices; collect latency/quality/feedback.
-
Implement governance (model signing, privacy toggles, safety filters).
-
Document a support runbook and schedule model refreshes.

Reference Configurations (Good Defaults)
-
Windows laptop (integrated GPU): ONNX Runtime + DirectML EP; quantized ONNX models for vision; GGUF 7B-class LLM via llama.cpp or Ollama with 4K context.
-
Mac (Apple silicon): Core ML for vision/audio; Core ML-optimized 8B-class LLM with FP16/NE acceleration; or llama.cpp Metal backend.
-
NVIDIA RTX desktop: TensorRT/TensorRT-LLM for LLMs; ONNX Runtime + TensorRT EP for classic nets; batch where latency allows.
-
Intel iGPU edge box: OpenVINO runtime with INT8; post-training quantization on representative datasets.
-
Android device: TFLite or ONNX Runtime with NNAPI; MLC LLM if running an LLM fully on device.
-
Browser: WebLLM (WebGPU) for small LLMs; ONNX Runtime Web + WebGPU for image/audio tasks.
Glossary (Quick Refreshers)
-
Edge AI / local AI: Running AI models on or near the data source rather than in the cloud.
-
Execution Provider (EP): A plugin in ONNX Runtime that maps parts of a graph to an accelerator.
-
GGUF: A compact file format used by llama.cpp for quantized language models, designed for fast loading and simple metadata.
-
LoRA/QLoRA: Parameter-efficient fine-tuning methods that train small adapters (and in QLoRA, use a 4-bit base) to adapt big models cheaply.
-
WebGPU: A modern browser API that exposes GPU compute for portable, high-performance local AI in web apps.
Frequently Asked Questions (FAQ)
Here are answers to some common questions about local AI, its capabilities, and practical considerations to help you better understand and implement these solutions.
Is local AI always more private than cloud AI?
Yes in the sense that data never leaves the device by default, which reduces exposure and makes data secure by design. Still enforce app-level permissions, encryption at rest, and safe logging.
Do local models match cloud quality?
For many tasks, yes—especially with task-specific fine-tuning and retrieval. For frontier-scale creativity or multi-modal reasoning, cloud models may still lead.
How do I get performance on a laptop without a discrete GPU?
Use ONNX Runtime with DirectML on Windows, OpenVINO on Intel iGPUs, or Core ML on Apple silicon. For LLMs, combine quantized GGUF builds in llama.cpp with small context windows.
What about the browser?
WebLLM and ONNX Runtime Web with WebGPU now run compact language models and vision nets directly in the tab—zero install, strong privacy.
Which file formats should I standardize on?
ONNX for classic nets across platforms; GGUF for LLMs when targeting llama.cpp/Ollama.
Putting It All Together
Local AI is no longer a science project. With the right runtimes, quantized models, and parameter-efficient fine-tuning, organizations can ship fast, private, and cost-efficient AI applications today. Start with a small pilot—pick one use case, select an inference stack that matches your hardware, and measure accuracy and latency on the local devices that matter. As you expand, you’ll unlock new possibilities for user experience while reducing reliance on the cloud.
Sources and Further Reading
-
ONNX Runtime: Execution Providers; Web; WebGPU EP; DirectML EP.
-
Apple: Core ML overview; model encryption; typed execution; Apple ML research on on-device Llama.
-
NVIDIA: TensorRT quick start; TensorRT-LLM docs; release notes.
-
Intel: OpenVINO docs and 2025 release notes.
-
Android: NNAPI overview and runtime module.
-
Qualcomm & Windows: QNN SDK and Windows ML overview & EP selection policy.
-
LLM tooling: llama.cpp (GGUF); Ollama library & Modelfile; llamafile.
-
MLC LLM & WebLLM: project and browser engine.
-
PEFT: LoRA and QLoRA.
-
Edge AI benefits: industry overviews.
